如祺出行AI数据战略:以高价值场景驱动世界模型训练
具身智能的发展浪潮正全面加速,但实现突破的关键瓶颈往往在于数据层面。当前行业竞争的核心挑战,并非单纯依赖硬件算力的提升,而在于能否获取用于模型训练的高质量、高价值数据——即那些自带因果逻辑、富含交互特性、且严格遵循物理规律的真实世界数据。如今,一座堪称“黄金数据矿”的资源宝库正式对外开放:其日均产出高达1600小时的高质量多模态数据,完整记录了从决策、执行到环境反馈的全链条因果关联,天然构成了物理世界的精准数字映射。
而打开这座数据宝藏的钥匙,正掌握在一家领先的出行科技平台——如祺出行手中。
近期,如祺出行旗下数据业务板块首次系统披露了其AI数据资产布局,正式以大规模、高价值的真实出行场景数据,切入具身智能与世界模型的训练赛道。目前,其已建立起覆盖标注数据、行为数据、合成数据及多模态训练数据集的完整资产体系,初步构建了服务于物理世界AI模型的真实场景数据基础设施。
截至2026年5月,如祺出行已在广州、上海、重庆、沈阳等全国核心城市投入运营超过300辆智能驾驶数据采集车辆。这支规模化车队日均合规产出超过1600小时、约130TB的高质量场景数据,为自动驾驶技术迭代,乃至更广泛的具身智能、世界模型研发提供了持续、稳定、充沛的数据供给。
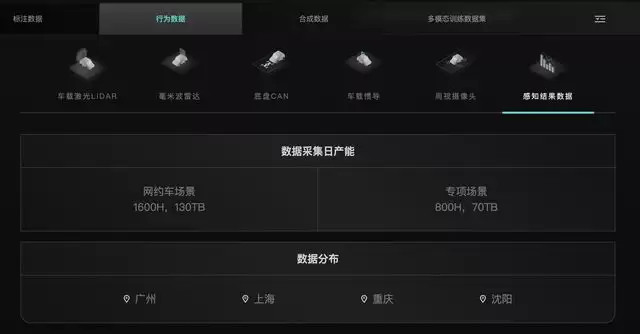
这些从海量真实出行场景中持续沉淀的多模态数据,其应用价值远不止于自动驾驶领域。它们能够同时支撑机器人、通用人工智能等多个前沿行业的AI训练需求,为具身智能体和世界模型提供一个可扩展、高保真的真实世界数据底座。长期关注AI模型训练的行业专家指出,在空间智能成为AI发展核心方向的当下,包含了丰富驾驶行为、复杂道路交互、精确空间关系与连续时序变化的真实出行数据,无疑是训练物理世界AI模型的稀缺优质资源。
手握AI训练的“黄金数据矿”
当前,以具身智能为核心应用载体的世界模型,已成为全球人工智能竞争的下一个战略高地。然而,高质量物理交互数据的严重短缺,正成为制约其走向大规模商业化落地的核心瓶颈。行业分析数据显示,目前全球可用于具身智能背后世界模型训练的高质量数据总量,仅约50万小时左右。相比之下,头部科技公司单年的数据需求就高达百万小时级别,供需失衡的矛盾异常突出。
值得关注的是,像如祺出行这样的智能出行平台,却天然具备持续生产并沉淀这类高价值训练数据的独特优势。依托平台每年数亿级的出行订单与海量车辆运行轨迹,能够持续积累驾驶员行车、泊车、城市道路通行等高频且复杂的交通场景多模态数据。与传统的静态图像、视频或人工搭建的仿真数据不同,这些数据完整记录了“驾驶员决策-车辆控制-环境反馈”的全链条动态过程,具备天然的因果关联与交互逻辑。这恰恰能直接破解出行相关AI模型训练面临的“数据荒”难题,堪称训练世界模型与具身智能的核心战略资产。
公开资料显示,如祺出行自2024年起便开始战略性布局AI数据解决方案。基于自身出行平台的运营网络与合规优势,其将搭载激光雷达、高清摄像头、毫米波雷达等多类传感器的智能驾驶数据采集车投入常态化运营,同步合规采集真实的驾驶行为与多维道路环境数据。

以典型的自动泊车场景为例,如祺数据不仅记录3D障碍物的精确空间位置,还同步采集车辆底盘CAN信号、毫米波雷达点云、激光雷达点云与多路摄像头视频流,从而围绕单一的泊车行为,构建起一个多模态、高精度的“行为-状态-环境”联合数据集。

业内专家分析认为,这类数据因其具备完整的感知、推理、决策与反馈闭环,能够高效支撑具身智能体与世界模型去理解和学习复杂的空间关系、动态交互以及各类长尾场景。其数据价值与信息密度远超传统的静态图片或合成视频,是训练空间智能模型不可或缺的“黄金数据矿”。有接近如祺出行的消息人士透露,该公司已开始将其积累的数据用于训练车后服务机器人等具身智能应用,积极探索数据价值向更广泛机器人领域的延伸。
全栈服务能力延伸至具身智能
与传统AI数据服务商多聚焦于基础数据标注环节不同,如祺数据已完成从单一标注服务向“标准化数据集+全栈技术服务能力”的战略升级。其形成了从数据采集、规模化预处理、高精度标注,到合成数据生成、多模态数据融合处理的全链路服务能力。这一完整的技术与服务体系,使其服务范围不仅深度覆盖智能驾驶领域,更能高效拓展至具身智能、通用大模型、机器人等高价值赛道。
目前,如祺数据已具备将完整数据服务封装成标准化、模块化产品的能力,让客户能够实现“开箱即用”,无需再投入大量资源进行底层数据清洗、标注等繁重工作,这显著降低了企业获取和使用高质量真实世界数据的门槛。
在规模化交付与服务能力上,如祺出行已在全国建立了3大核心服务交付基地,专业服务团队规模超过1500人,并整合了超过1000家BPO合作伙伴及近百万众包资源,可实现月千万级数据项的标注产能,充分满足高并发、大规模的数据处理需求。技术层面,公司自研的OCC自动化标注算法,可减少90%以上的人工标注时间,同时将交付准确率稳定在98%以上。此外,如祺的合成数据引擎能够生成覆盖不同时段、多种天气条件与复杂座舱场景的数据,有效弥补了真实数据采集的盲区与长尾难题;而其多模态训练数据集全面覆盖图像、文本、音频、视频,可直接支持行业大模型的垂类微调与快速迭代开发。

商业化路径获得验证
依托真实场景的数据资产优势、全栈技术能力与规模化交付体系,如祺数据在AI数据服务赛道构建了差异化的核心竞争力。其服务已从智能驾驶领域,成功拓展至具身智能、大模型训练、消费电子、智慧医疗等多个高价值领域,形成了多赛道协同、相互促进的业务增长格局。
在商业化落地层面,如祺数据已与腾讯、小马智行、理想汽车、火山引擎、百度智能云、广汽集团等众多行业头部企业建立了深度合作关系,其商业模式与商业路径已得到市场初步验证。这一点在公司的财务表现上得到了直接体现。根据如祺出行发布的2025年财报,公司以AI数据服务为核心的技术服务业务营收达到1.60亿元,同比大幅增长487.4%,成为其增长最迅猛的业务板块。
相关攻略

模型训练,本质上就是赋予计算机“学习与思考”的能力。它通过神经网络等算法,让机器在海量历史数据中自主发现规律、优化内部参数,最终构建出一个能够进行智能预测或内容生成的“逻辑大脑”。 这个过程可以类比于培养一位顶尖专家。模型训练就如同专家通过大量案例分析(数据)来提炼方法论(模型)。如今,这一进程正飞

在使用Perplexity进行网络搜索时,若您希望确保个人搜索记录完全不被用于AI模型训练或服务优化,您需要主动管理其数据采集设置。平台默认可能会利用用户行为数据改进产品,但也为用户提供了清晰的隐私控制选项。以下是具体的操作指引。 一、关闭账户级AI数据使用权限 这一步至关重要,它能直接阻止Perp

在人工智能技术飞速发展的当下,大模型训练平台已成为开发者和企业构建智能应用的核心工具。这类平台集成了大模型开发、训练、优化、部署与运维的全套能力,将复杂的数据处理、算法训练、资源管理和模型服务流程一体化,其根本目标是显著降低大规模深度学习模型的构建难度,并大幅提升从研发到落地的整体效率。 一、核心功

最近,一项由威斯康星大学麦迪逊分校主导的研究,在AI训练领域投下了一颗“思想冲击波”。这项于2026年3月发表在arXiv预印本平台(编号:arXiv:2603 19987v1)的工作,直指当前大模型训练的一个根本性矛盾,并提出了一种看似“复古”却极为高效的解决方案。 想想看,我们是怎么教一个学生掌

当多个AI智能体需要像团队一样协作完成复杂任务时,如何让它们学会更好地配合一直是个棘手问题。来自新加坡南洋理工大学的研究团队最近在这个领域取得了重要突破,他们开发了一套名为Dr MAS的训练方法,专门解决多智能体大语言模型系统的训练不稳定问题。这项研究发表于2026年2月9日的arXiv预印本平台
热门专题







热门推荐

在流量日益分散的今天,把鸡蛋放在同一个篮子里,风险不言而喻。多平台推广,早已不是“要不要做”的选择题,而是“如何做好”的生存题。它的核心价值,可以概括为两点:实现“流量风险对冲”,以及构建“品牌触点全覆盖”。通过在不同生态位——无论是搜索、短视频、图文还是电商——建立内容矩阵,企业不仅能有效缓冲单一

DeepSeek知识库的核心,是运用RAG(检索增强生成)技术,将DeepSeek强大的大语言模型推理能力,与您的私有文档资源——包括PDF文件、内部代码库、标准操作流程(SOP)等——深度融合。其最终目标是实现基于特定垂直领域数据的精准智能问答,让AI的回答不再是通用泛化,而是具备专业依据、内容详

三大运营商推出Token套餐,将大模型调用量包装为类似流量包的产品,以降低AI使用门槛。中国电信推出个人与企业多档套餐,最低月费9 9元;上海移动推出1元购40万Tokens服务;联通则提供个人与团队版套餐。运营商凭借用户渠道和支付优势,推动算力消费向大众市场普及,可能重塑AI服务消费模式。

HermesAgent本地运行缓慢常因未量化的大语言模型占用资源过多。可通过AWQ量化模型、llama cpp后端加载GGUF模型、配置vLLM引擎提升并发吞吐、禁用非必要工具降低上下文开销,以及调整SQLite记忆检索阈值等方案优化。这些方法能显著降低延迟,提升响应速度。

随着AI智能体能力的持续增强,确保其行为始终符合预设目标与安全边界,已成为行业亟待解决的核心挑战。然而,当前主流的治理方案在防止智能体“失控”或“脱轨”方面,仍面临显著的实践瓶颈。 在之前的探讨中,我们分析了主流治理思路:部署多样化的对抗性验证器,构建一个多层次的安全审查网络。该方案的核心逻辑并非限