腾讯混元SOAR技术让视觉大模型学会自我纠偏
视觉生成模型的后训练,始终面临一个核心挑战:如何在不依赖海量人工标注或稀疏奖励信号的前提下,有效提升模型的对齐能力与生成质量。是否存在一种方法,能让模型直接从数据中学习并实现“自我纠偏”?
近期,腾讯混元团队提出的HY-SOAR(Self-Correction for Optimal Alignment and Refinement)技术,为此提供了一种创新解决方案。该方法无需奖励模型、不依赖偏好标注数据、也无需构造负样本,而是直接从训练数据中挖掘轨迹级别的纠正信号,使模型在去噪过程中即具备自我反思与动态调整的能力。这为扩散模型与流匹配模型的后训练优化,开辟了一条极具潜力的新路径。
后训练的核心瓶颈:数据利用效率是关键
当前,扩散模型的后训练主要依赖于两种主流方法:监督微调(SFT)和基于强化学习(RL)的对齐。然而,深入分析会发现,两者在数据利用效率上均存在明显局限。
SFT遵循“学习标准答案”的思路。它在高质量数据上进行监督训练,但仅教会模型处理“理想轨迹”——即从真实数据通过前向加噪得到的标准中间状态。问题在于,模型在实际推理时遵循的是自身生成的轨迹。一旦早期去噪步骤出现微小偏差,后续状态就可能进入训练中从未覆盖的区域。数据本身蕴含的关于“模型可能如何偏离以及如何纠正”的宝贵信息,在SFT过程中被完全忽视了。
RL方法则走向了另一个方向,某种程度上“损失了信息密度”。它首先通过奖励模型将高质量数据转化为一个终端分数,再利用这个稀疏的信号去优化整个生成轨迹。这个过程本质上是一种有损压缩——数据中丰富的、轨迹级别的细节信息被压缩为单一的标量奖励,大量可用于纠正中间步骤的信号在此过程中丢失。更棘手的是,奖励信号的稀疏性还会导致信用分配困难,甚至可能诱发模型为“刷分”而产生奖励作弊行为。
可以这样理解:旗舰模型的最终性能 = 数据质量 × 数据利用率。当数据质量达到较高水平后,性能瓶颈往往就转移到了数据利用率上。RL方法在利用率上打了折扣,而SOAR技术的目标,正是要找回这部分被折扣的效率。

△ 图1:SFT仅在理想轨迹上训练,浪费了数据中的纠偏信息;RL将数据压缩为稀疏终端奖励,利用率受限;SOAR直接从数据中提取稠密的轨迹纠正信号。
SOAR原理:赋予生成模型自我反思与纠偏能力
回顾大语言模型的发展历程,其进化路径清晰可辨:预训练 → 监督微调(SFT) → 基于人类反馈的强化学习(RLHF) → 自我反思(以o1/o3为代表的self-correction)。视觉生成模型的发展似乎也遵循着相似的轨迹,而SOAR正是实现“自我反思”能力的关键一步。
它首次让扩散模型具备了“在生成过程中审视并修正自身行为”的能力。其工作逻辑清晰高效:首先,对真实样本执行一步无梯度的前向推理,模拟模型自身可能产生的轨迹偏离;接着,针对这个偏离状态重新施加噪声,构造出辅助的训练点;最后,以原始真实样本为锚点,计算出解析式的纠正目标。
整个流程,无需奖励模型,无需人工偏好标注,也无需负样本——所有的纠正信号,都完全从数据本身解析得出。
这带来了三个核心优势:
数据利用率最大化:能够从同一份高质量数据中,同时提取出“标准答案”和“纠偏信号”,避免了经过奖励模型转换造成的信息损失。
获得稠密监督信号:在去噪的中间步骤就能获得纠正指导,而不是等待整张图像生成完毕后,才得到一个迟来的、稀疏的终端奖励。
实现在线自适应学习:模拟的偏离状态来源于当前模型自身的推理,因此训练分布会随着模型能力的更新而自适应变化,始终紧贴模型当前的能力边界。
这不再仅仅是一种训练技巧的改进,它标志着生成模型从“被动执行指令”到“主动审视和纠正自身行为”的一次重要范式跃迁。
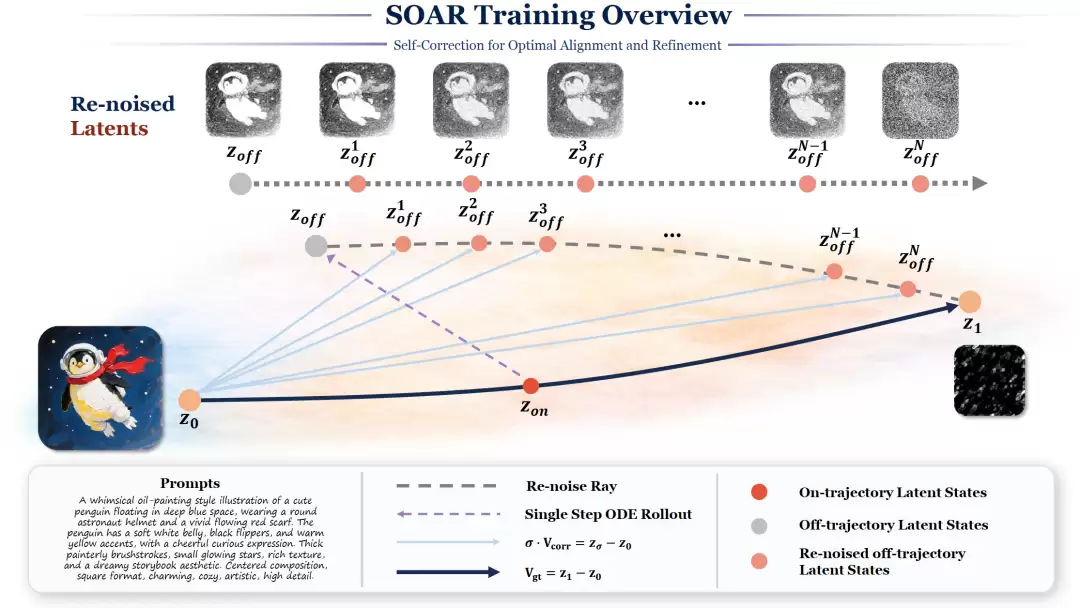
△ 图2:SOAR训练总览——从在轨状态出发模拟偏离,构造多尺度离轨辅助点,计算解析纠正目标。
实测效果:无需奖励模型,性能超越RL方法
实际效果如何?数据是最有力的证明。基于SD3.5-Medium模型,使用28.6万图文样本进行训练,且全程未使用任何奖励模型标注。实验结果显示,SOAR在所有报告指标上均显著优于传统的SFT方法:GenEval从0.70提升至0.78,OCR从0.64提升至0.67。在DrawBench评测集上,PickScore、HPSv2.1、Aesthetic、ImageReward等多项指标也实现了同步提升。

△ 表1:SOAR与SFT在SD3.5-Medium上的指标对比。SOAR在所有维度上均获得提升,且无需奖励模型。
更具说服力的对比出现在专项测试中。在高美学质量和高CLIP分数的数据子集上,SOAR不仅在目标指标上呈现稳定的单调提升,其最终数值甚至超过了直接优化对应奖励函数的Flow-GRPO方法(Aesthetic 5.94 vs 5.87;ClipScore 0.300 vs 0.296)。换言之,不依赖奖励模型的SOAR,其优化效果反而超越了使用奖励模型进行RL训练的方法——这正是更高数据利用率所带来的直接收益。

△ 图3:SOAR在目标指标上呈现稳定提升,最终超过SFT和Flow-GRPO。无奖励模型,却优于RL方法。
SOAR与RL的结合:构建更稳定的后训练流程
需要明确的是,SOAR并非旨在取代RL,而是为RL提供一个更稳定、更可靠的优化起点。
当前RL后训练面临的一个核心挑战是:基础模型本身的生成轨迹可能还不够稳定。此时直接使用稀疏的奖励信号驱动探索,模型容易在不稳定的区域做出过激的调整,导致在单一指标提升的同时,其他重要维度(如语义一致性、图像结构)发生崩塌。
SOAR可以先行一步,将模型的轨迹稳定性提升到一个更高的基线水平——确保语义不崩塌、结构不走形、文字渲染准确。在此基础上,再接入RL进行特定偏好的探索和微调,模型就能在一个更安全、更可控的区间内进行风格调整与质量优化。
可以打一个比方:这就像是先让模型学会稳健行走,再教导它根据指令变换步伐,而不是在它尚且步履蹒跚时,就被奖励信号拽着盲目狂奔。
可视化效果展示

△ 图4:美学奖励优化——SOAR在结构稳定性、色彩氛围和细节质量上持续提升。

△ 图5:CLIPScore奖励优化——SOAR在文字渲染准确性和构图保真度上表现出更强的语义遵循能力。

△ 图6:WebUI /设计生成——SOAR展示了准确的布局排版、文字层级和视觉结构一致性。
总结与展望
总而言之,SOAR为扩散模型的后训练提供了一种全新的思路:摒弃对奖励模型的依赖,转而直接从数据中挖掘轨迹级别的纠正信号,使模型学会在生成过程中进行自我反思与实时纠偏。
当数据质量已经达到较高水准时,决定模型性能上限的关键因素,往往不再是数据本身,而是训练方法能够从每一份数据中提取出多少有效的监督信号。
SFT只利用了数据中的“标准答案”,RL则将数据压缩成了稀疏的终端奖励,而SOAR致力于在轨迹层面,充分榨取数据每一分的纠偏价值。这种从“被动模仿”到“主动自纠正”的能力跃迁,有望成为图像生成、视频生成、3D生成乃至更广义的世界模型,迈向更高阶段智能化不可或缺的关键基础设施。
目前,HY-SOAR的相关研究论文与代码均已开源,为后续更深入的技术研究与应用探索敞开了大门。
热门专题







热门推荐

微信群里的接龙,方便是真方便,但整理起来,那叫一个头疼。手动复制粘贴,不仅耗时费力,还容易出错、遗漏,最后导出的表格格式五花八门,看着就心累。 有没有一种方法,能让这个过程自动化,让数据自己“跑”进表格里?答案是肯定的。借助一些工具,我们可以实现群内接龙数据的自动识别、解析和归档。下面,就来拆解一下

VineCoin(VINE币):重塑创作者经济的区块链新星 在数字资产的浪潮中,VineCoin(VINE币)正作为一个新兴项目崭露头角。它并非又一种简单的代币,其野心在于利用区块链技术,从根本上重塑内容创作与社交互动的经济规则。可以说,它致力于成为一个去中心化生态系统的核心引擎,目标是为全球的内容

ToClaw文件整理术:一键清理桌面杂乱文件的秘籍 | AI智能文件管理教程 利用AI智能助手整理电脑桌面文件,愿景虽好,但在实际应用中,你是否也遇到过分类不准确、指令执行失败,甚至文件被误移的困扰?请放心,这些问题往往源于几个关键的设置步骤尚未完善。掌握以下这套经过验证的ToClaw文件整理优化方

三星电子工会确认原定罢工计划未取消,但将遵守法院禁令,确保罢工不影响正常生产流程。劳资博弈进入微妙阶段,工会需在法律框架内施压,公司生产秩序暂获法律庇护,后续发展取决于双方谈判。

千问AI赋能社群自动化运营:一、关键词触发智能回复;二、定时任务精准推送;三、敏感词实时过滤预警;四、成员标签化智能分组。 社群运营工作繁杂,常常需要处理大量重复性任务,如解答常见问题、发布定时通知、监控群内动态等,这让运营者倍感压力。如何实现高效、智能的社群管理,解放人力?利用千问AI的强大功能,