人类专家能力超越AI:新基准测试揭示大模型性能短板
相信不少朋友都有过这样的体验:用多模态大模型看视频,乍一看它好像什么都懂,能说会道。可一旦深究细节,或者让它分析一段稍长的剧情,回答就开始变得似是而非、答非所问。这不禁让人疑惑:那些在各大视频理解榜单上名列前茅的模型,真实能力到底如何?
最近,Video-MME团队推出的新一代评估体系,或许给出了一个残酷而清晰的答案。这套体系通过一种严苛的分组连贯性测试,彻底堵死了模型靠“碎片化识别”和“瞎蒙猜题”来刷高分的捷径,精准地勾勒出了当前多模态模型的真实智力边界。

要知道,Video-MME基准在2024年一经推出,就因其对跨时长视频理解能力的系统性考察,迅速成为包括Gemini和GPT在内的众多顶级模型的“试金石”。经过近一年的迭代,这个全新的v2版本,可以说是把“考场纪律”提升到了前所未有的严格程度。
撕掉榜单遮羞布
过去的视频理解评测,问题往往出在“考题”本身。很多基准测试只聚焦于特定、零散的任务,很难系统性地评估模型真正的理解深度。这就导致了一个尴尬的局面:面对一段几十分钟的视频,模型可能只是侥幸认出了某几帧里的关键物体,就能在单项选择题里蒙对答案,给使用者营造出一种“全知全能”的假象。
要测出真本事,就得回归本质,重新拆解“理解视频”这件事到底需要哪些能力。新的基准将测试维度清晰地划分为三个循序渐进的层级,就像一场从易到难的晋级考试。


最基础的一层,是“多点信息聚合”,考验的是模型最基本的“找信息”能力。系统会考察它对视频帧、音频、字幕等分散线索的检索与提取功夫扎不扎实。
往上走一层,就进入了“时序信息理解”的领域。视频不同于静态图片的核心就在于其动态性,模型需要能准确解析画面中的状态变化、动作序列以及事件之间的逻辑关联。
而最高的一层,直接指向“时序复杂推理”。模型不仅需要感知和理解多模态的时序信息,还得结合现实世界知识和社会常识,进行多步骤的推理,以应对真实场景中的复杂挑战。
通过这三层架构,系统能把每一道考题都分门别类,精准地定位到模型的能力短板究竟在哪里。
拒绝瞎蒙与背题
有了好的考题,怎么“判卷”更是直接决定了评测的含金量。传统的评测范式下,每道题独立计分,互不影响,模型靠运气蒙对几题的概率不小。新基准彻底碘伏了这种做法,引入了“分组式评估”机制。
具体来说,系统会把问题按照能力一致性与推理连贯性,组织成多个包含4道小题的“任务组”。
在“能力一致性”任务组里,考核的是模型对单一能力的真实掌握度。系统会围绕同一个核心知识点,从局部到全局进行连环发问。比如,要测试视频计数能力,题目会依次询问:单帧里有多少运动员?单个片段里有几种动作?跨片段中同一个动作执行了多少次?最后再问:整个视频总共有几个片段?
计分规则非常有意思:系统统计模型答对的小题数量N,最终得分是 (N/4)²。这意味着,靠运气蒙对一两题只能拿到极低的分数,只有全部答对才能拿到满分。这种非线性增益的计分规则,极其直白地奖励了稳定且一致的“真本事”,让“半吊子”无所遁形。
而“推理连贯性”任务组,则更像是一场逻辑严密的审讯。系统不再只看最终答案的对错,而是在整个推理链条的关键节点上设置递进式考点。例如,针对一段“剧中人物假死”的情节,系统会按顺序提问:能否识别出表明“死亡”的表象线索?有没有捕捉到其中反常的细节?据此推断人物假死的目的是什么?最后才让模型给出终局结论。
这个组别的计分规则更为残酷,引入了“首错截断”机制。只要模型在推导过程中的任意一个节点出错,后续就算侥幸猜对了最终答案,也不再计分。这样一来,逻辑断裂导致的“伪正确”被彻底清理出局。
在如此严苛的审视下,各路前沿大模型的真实水平暴露无遗。
模型性能排名:

即便是强如Gemini-3-Pro,距离人类专家90.7分的碾压级表现,依然有很长的路要走。
魔鬼藏在细节里
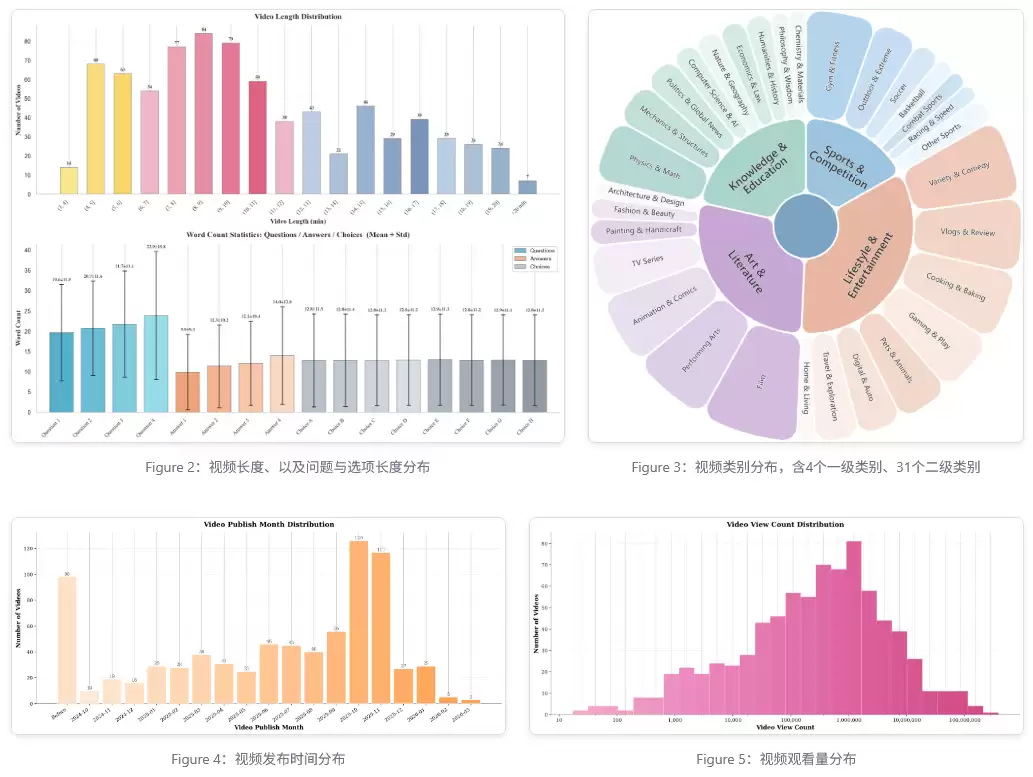
为了保证考题的纯净,不被大模型自身的先验知识“污染”,构建这个包含800个视频的数据集,耗费了惊人的3300个人工时。
数据源头经过了极致精细的筛选。超过80%的视频发布于2025年及以后,其中近40%更是发布于2025年10月之后。团队人工剔除了所有经典影视作品和头部博主的热门内容,彻底掐断了模型依靠“记忆效应”或“网上剧透”来作弊的途径。
视频素材覆盖了体育竞技、生活娱乐、艺术文艺、知识教育四大类,衍生出31个二级类别,平均长度约10.4分钟,其中53%在10分钟以内,保证了测试的广度和深度。
不仅内容要新,质量门槛也极高。84.3%的视频观看量超过1万次,均值高达483万次,从源头就过滤掉了低劣的噪声数据。
12名人类专家负责全流程标注,不仅要设计问题,还要为每道题精心打磨8个选项。每个问题除了常规干扰项,还会专门针对正确答案,量身定制极具迷惑性的“陷阱”选项,逼迫模型展现出细粒度的辨析能力,而非笼统的猜测。
问题设计完成后,50名独立专家入场,开启车轮战式的交叉盲测。质检团队会使用Gemini-3-Pro在纯文本模式下做题,只要发现某道题“不看视频,光靠读题和选项就能猜出答案”,就会立刻将其打回重造。历经多轮交叉复核、盲测与修正,最终确立了难度梯度极其统一的考题,问题与选项的长度在四道连环题中呈现完美的递增规律。
真实的智力边界
新规则一出,高分泡沫应声破裂。数据显示,Gemini-3-Pro和Gemini-3-Flash在传统的“逐题平均准确率”下,分别能拿到66.1%与61.1%的及格分数。可一旦切换到更严苛的“非线性计分”体系,成绩瞬间腰斩至49.4%与42.5%。
Non-Lin Score与A vg Acc对比:

这两个分数的比值,直接揭示了模型的鲁棒性。一些小模型,如LLaVA-Video-7B,该比值仅为40%左右,极容易在同一个问题组里出现零散命中,根本无法稳定输出。
随着题组测试的深入,模型的“底牌”也被彻底看穿。在能力一致性测试中,强模型的准确率曲线相对平稳,展现出较好的稳定性。但在推理连贯性测试中,随着问题从“线索定位”向“因果解释”步步紧逼,所有模型的准确率均呈现平稳下降的趋势。而较弱的模型则干脆显示出极高的随机性,答题表现起伏不定,如同“抽卡”。

一个有趣的发现是关于大模型热门的“思考”模式。数据证明,在文本模态(如有字幕)的环境下开启思考模式,通常能有效激发模型的推理能力,获得稳定的性能增益。然而,一旦抽掉字幕,仅靠纯视觉画面去“思考”,很多模型不仅没有进步,反而出现了严重的性能倒退。这清晰地表明,当前多模态大模型的“思考”机制,仍然极度依赖显式的语义线索,纯视觉推理依然是一个巨大的能力盲区。

系统还将模型的底层能力抽象为三大块:全模态信息聚合、长上下文理解与复杂推理能力。同时具备这三项能力的大型模型,自然全面占据了榜单高位。不过,庞大的参数规模也能产生奇妙的“代偿效应”。例如,Qwen3.5-397B-A17B-Think虽然在设计上并不显式具备全模态能力,但凭借其巨大的参数规模所带来的长上下文处理与推理优势,依然拿到了39.1分,超过了某些能力配置更完整但参数较小的模型。
模型能力画像与得分:

此外,模型能处理的视频帧数同样至关重要。Qwen3.5-397B在512帧设定下的得分,比64帧设定足足高出8.5分。这再次印证了一个直观的道理:对于视频理解,“看得越多,懂得越深”。
最后,各大模型的能力雷达图更是将它们的“偏科”情况展现得一目了然。Gemini-3-Pro在音频融合与长视频时序推理上遥遥领先,跨模态对齐能力出众。而其他一些模型则在细粒度动作语义建模与物理规律理解等维度上得分甚至不足30分,表明它们连一些基本的物理常识都未能完全掌握。

总而言之,当剥去榜单高分的华丽外衣,当前最聪明的AI,在面对需要连贯逻辑的视频推理任务时,依然表现得像个步履蹒跚的学徒。这项研究如同一面镜子,清晰地映照出现有技术的边界。通往通用人工智能的道路上,还有无数这样的硬骨头,等待被啃下。
相关攻略

人工智能技术正迎来一个关键的爆发节点。根据人民网5月11日的最新报道,国产大模型技术正以前所未有的速度迭代升级,应用场景也在持续拓宽,已成为全球人工智能创新版图中不可或缺的核心力量。尤其在编程开发、知识问答与专业内容处理等领域,AI展现出的能力已无限接近甚至超越人类专家水平,其对社会整体生产效率的潜

在信息爆炸的数字时代,消费者的信任已成为品牌最核心的无形资产。然而,当人工智能逐渐成为用户获取信息与决策的关键入口时,品牌在AI生成内容中的“存在感”与“准确性”变得至关重要。一旦品牌信息在AI回答中缺失或被误述,长期建立的信任可能迅速流失。因此,GEO优化的深层价值,远非单纯的技术调整,它本质上是

随着中国品牌出海步伐的不断深入,一个全新的挑战浮出水面:如何在ChatGPT等全球性AI平台中,塑造准确且积极的品牌认知。传统的GEO优化,其战场已从中文互联网扩展至全球范围。这对服务商提出了更高要求——不仅要精通AI技术,更需深刻理解跨境传播的复杂生态。基于对服务商跨境语境适配能力与全球AI生态布

想在本地部署大语言模型,但只有一张8GB显存的显卡?这完全可行。关键在于精准选择模型与量化方案,在有限的硬件资源下实现最优性能。本文将为您详细解析适配8G显存的各类主流模型及其具体部署运行方案。 一、4-bit量化模型部署指南 对于RTX 3060、RTX 4060等主流消费级显卡,4-bit量化是

2026年4月,小米大模型团队重磅推出新一代原生全模态智能体系列——MiMo-V2 5。该系列并非单一模型,而是一个强大的能力矩阵,致力于将多模态感知与自主行动深度结合。简而言之,它赋予AI“能看、能听、能读、能执行”的一体化智能,并标配高达100万token的超长上下文窗口,专为应对复杂的智能体任
热门专题







热门推荐

为庆祝品牌投身赛车运动整整125年,斯柯达正式推出了晶锐Fabia Motorsport Edition特别版。这款车基于Fabia 130打造,设计灵感直接来源于征战赛场的Fabia RS Rally2拉力赛车,整体风格充满了对赛事历史的致敬意味。不过,得先说明白,它的升级重点主要落在了外观和底盘

Grayscale 通过其以太坊质押 ETF 质押了 102,400 个 ETH,价值 2 37 亿美元 先来看一组数据:资产管理巨头 Grayscale 最近通过其以太坊质押 ETF,一口气质押了超过10万个 ETH,价值约2 37亿美元。这个动作本身不小,但更有意思的是市场的后续反应——或者说,

劳斯莱斯库里南自问世以来,始终是超豪华全尺寸SUV领域的标杆。对于追求极致安全又不愿牺牲低调气质的高净值人士而言,如何实现“隐形”的顶级防护,一直是核心诉求。如今,加拿大专业防弹车制造商Inkas,以一款近乎“零痕迹”改装的库里南,给出了完美解决方案——一座移动的“隐形堡垒”。 区别于常见的外露装甲

新加坡维塔士工作室正考虑将《侠盗猎车手V》与《荒野大镖客:救赎2》移植至任天堂Switch平台。该团队拥有丰富的移植经验,曾成功负责多款游戏的跨平台适配。这两款作品全球销量巨大,若能登陆Switch,其便携特性可能成为新的市场增长点。

当高尔夫GTI迎来五十周年里程碑,传奇的纽博格林北环赛道成为其致敬历史与展望未来的最佳舞台。这里不仅铭刻了燃油性能图腾的巅峰时刻,也正式开启了电动GTI的新纪元。近日,大众汽车正式宣布,高尔夫GTI 50周年版在纽北创下全新纪录,荣膺最快前驱量产车称号;与此同时,品牌首款纯电动GTI车型——ID