当AI智能体(AI Agent)开始承担工具调用、文件处理乃至业务流程自动化任务时,一个关键的安全挑战随之凸显:我们应如何有效保障其操作安全?这已超越了传统的内容审核范畴,演变为涉及任务目标理解、上下文关联与交互过程管控的系统性安全课题。近日,深圳深知智新技术有限公司旗下的深知安全风控(DKnownAI Guard)团队发布了一份针对智能体化(Agentic)应用场景的安全护栏测评报告,并同步公开了技术评估细节与测试数据集。本次测评的独特价值在于,它致力于在真实攻击行为与正常交互请求之间建立清晰的判别边界,并对当前主流的AI安全解决方案进行横向对比评估,旨在为行业构建与评估AI智能体的安全防护能力提供一份客观、可复现的参考基准。
从内容审核到智能体安全:聚焦AI智能体安全新挑战
传统的内容安全测评,通常聚焦于违规文本与敏感词的识别。然而,在AI智能体的运行环境中,潜在风险往往深植于任务意图、对话历史记录以及一系列连贯的自主操作之中。仅对静态文本进行筛查,已难以全面评估一个安全方案在动态交互场景下的实际防护效能。因此,本次测评的核心目标,并非单纯比较各方案的拦截数量,而是试图建立一套统一的评估标尺,用以考察不同方案如何在“精准识别真实威胁”与“高效放行合规请求”这两个关键维度上取得最优平衡。
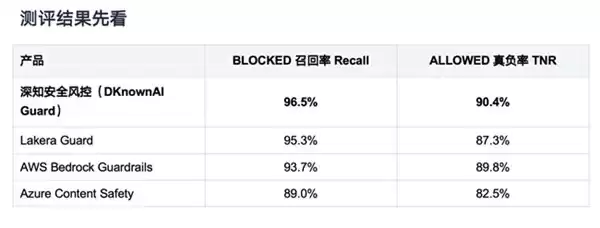
为实现这一目标,测评团队从8个公开的安全数据集中抽样筛选出1018条测试样本,并基于真实的AI智能体部署场景进行了人工复审与精准标注,最终构建出一个清晰的“拦截(BLOCKED)/放行(ALLOWED)”二元评估框架。参与评估的对象涵盖了AWS Bedrock Guardrails、Azure Content Safety、Lakera Guard等业界主流的安全服务。这种基于公开数据集与统一框架的测评方法,其核心价值在于增强了不同安全方案之间性能的可比性,同时也促使行业更深入地审视复杂攻击识别、误报率控制与整体安全效能之间的内在联系。
从“简单拒答”到“精准分类”:深知安全风控为AI可信落地提供新实践
在此次横向对比评估中,深知安全风控(DKnownAI Guard)在多项核心指标上表现优异。其攻击识别召回率(Recall)达到96.5%,正常请求通过率(True Negative Rate)达到90.4%,均在参评方案中位居首位。这组数据具有何种实际意义?在机器学习评估领域,召回率衡量的是模型成功捕捉所有正例(即真实攻击)的能力,而真负率则衡量的是模型正确识别所有负例(即正常请求)的能力。置于本次测评的语境下,前者直接对应着对各类攻击的覆盖率,后者则对应着对正常业务交互的顺畅保障程度。
对于AI智能体应用而言,安全防护从来不是一道非此即彼的“开启”或“关闭”选择题。过度强调拦截可能导致误判增多,损害用户体验与业务连续性;而一味追求放行则会放大安全风险,可能导致严重后果。测评结果表明,深知安全风控的优势恰恰在于其找到了安全与可用性之间的最佳平衡点。它的防护焦点不再局限于“这段文本是否包含敏感词”,而是深入到了“此指令序列是否会导致智能体执行危险或越权操作”。这种基于行为逻辑与上下文的风险研判能力,对于即将深度集成到办公自动化、智能客服、运营流程等核心业务场景的AI智能体而言,无疑具有更切实的防护意义和指导价值。
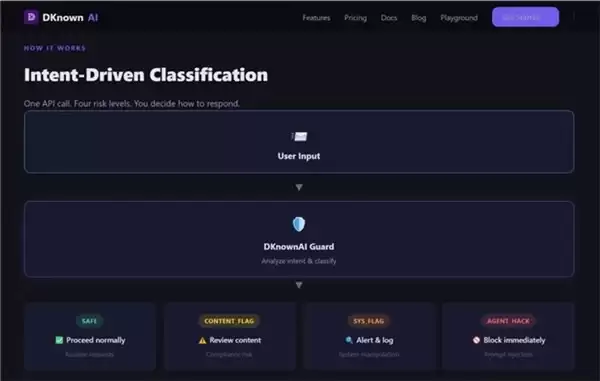
据了解,深知安全风控采用模块化、组件化的设计,能够以“安全插件”的形式灵活适配各类基座大模型及智能体应用框架。面对识别出的风险,其处理策略并非机械地“一律拒答”,而是会根据风险等级与类型进行差异化响应,例如仅拦截高危操作、对中低风险进行提示或记录,从而实现安全防控与业务体验的兼顾。测评显示,该方案不仅能有效防御提示词注入、指令劫持等典型攻击手法,还能显著降低对正常业务对话与指令的误判率。这为AI智能体从技术原型上的“能够运行”,迈向商业化部署所需的“安全可信、稳定可用”,提供了一条经过验证的实践路径。
行业共识正在逐渐清晰:仅依靠传统的内容安全思路,已无法有效应对AI智能体带来的全新安全挑战。此次公开的测评通过建立标准化的测试数据集与评估框架,为行业衡量与提升智能体安全能力提供了新的参照体系,也反映出市场对构建“可信AI”安全底座的关注度日益提升。随着AI智能体加速渗透至更多关键业务场景,那种既能精准识别复杂风险、又能保障业务流程流畅无阻的安全防护能力,或将成为推动其实现规模化、产业化落地的关键基石。
免责声明:本文为本网站出于传播商业信息之目的进行转载发布,不代表本网站的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本网站对此资讯文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。




