近日,全球权威AI模型评测平台Artificial Analysis的文生图榜单迎来一匹匿名“黑马”。它以代号“Peanut”参与盲测,最终在开源模型类别中强势登顶。如今,这匹黑马的身份正式揭晓——它正是智象未来最新发布的原生全模态大模型HiDream-O1-Image。更令人瞩目的是,这个表现卓越的模型,参数量仅为80亿(8B)。
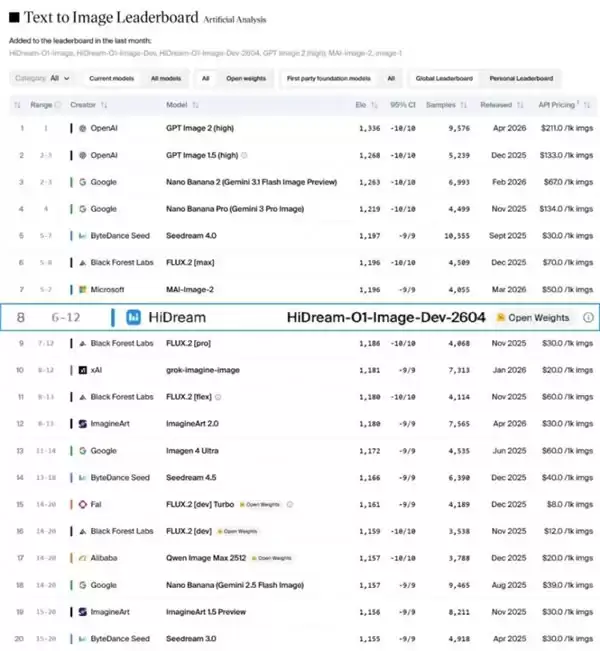
Artificial Analysis的Text to Image Leaderboard之所以备受业界关注,在于其评测机制更贴近真实用户场景。平台采用匿名对比、用户投票和ELO动态排名系统,旨在最大程度剥离品牌光环对结果的影响,而非仅仅考核固定题库的分数。在这场“硬碰硬”的开放评测中,HiDream-O1-Image在超过3000个样本的对比中取得了1187的ELO高分,成功问鼎开源文生图模型榜首。
回顾2025年第三季度以来的开源图像生成赛道,头部格局一度趋于稳定:FLUX.2 [dev]、Qwen-Image Max与Z-Image分别代表了高参数能力、开源标杆与轻量高效三大方向。此后数月,市场鲜有全新架构的挑战者出现。HiDream-O1-Image的横空出世,无疑打破了这份平静,为开源图像生成领域注入了新的活力。
在本次盲测竞技场中,隐藏身份的HiDream-O1-Image不仅冲入了总榜前列,更一举超越Z-Image Turbo、Qwen-Image、FLUX.2 [dev]等主流开源模型,成为新的领跑者。其开源当日,便在Hugging Face模型趋势榜上迅速跻身前三,社区热度持续攀升。
摒弃VAE与独立文本编码器,率先跑通像素级统一Transformer(UiT)架构
当前,主流顶级文生图模型普遍采用“模块化”的生成路径:先由独立的文本编码器处理语言信息,再通过VAE将图像压缩至潜空间进行生成。这条技术路线虽成熟,却难以避免高频细节丢失与图文语义错位的问题。
HiDream-O1-Image选择了一条更为彻底的革新路径。它在开源领域首次成功实现了端到端的原生统一架构,将原始图像像素、文本标记(Token)及各类控制条件,直接映射到同一个“共享标记空间”中。这一根本性变革,旨在从源头上消除不同模态之间的转换损耗,实现更精准的图文对齐。
具体而言,该模型由一种新型的像素级统一Transformer(UiT)驱动,不依赖任何分离的VAE或预训练文本编码器。所有多模态输入都能在这一统一的Transformer架构内,以端到端的方式协同处理。这种原生编码范式,使得多样的图像生成和编辑任务被统一视为一个连贯的上下文视觉推理过程,而非需要专门模块处理的孤立问题,从而促进了更深层次、更灵活的多模态交互与理解。
智象未来联合创始人兼CTO姚霆博士指出,图像是世界建模的重要空间基础。在UiT原生统一架构下,图像与视频的训练能够实现更高程度的协同,这为模型进一步演进为统一的多模态基础能力提供了坚实支撑。基于此架构,智象未来超千亿参数的图像模型也已呼之欲出,无限时长视频生成应用即将上线。
不止是图像生成:HiDream-O1-Image引入“先推理、后生成”机制
要训练一个能同时胜任文生图合成、指令编辑和主体驱动个性化等复杂任务的通才模型,高质量、大规模的训练数据至关重要,其需求远超标准的图文对数据。为此,团队构建了一个专用的数据引擎,将异构的原始数据源,高效转化为高质量的图文对、编辑三元组和主体-参考样本。整个流水线涵盖了源数据收集、去重、质量与安全过滤,以及基于先进视觉语言模型的提示词构建。
其中,最具突破性的设计,是针对传统生图模型高度依赖用户“提示词工程”的痛点。HiDream-O1-Image首次在图像生成底座中,系统性地引入了基于Gemma 4的“推理智能体”。在正式生成图像前,该智能体会自发启动思维链推理,深度解析用户指令中隐含的空间布局、物理逻辑与主体属性,从而将模糊的用户意图,自动重写为高精度的控制指令。这一“先推理、后生成”的机制显著增强了模型的指令遵循与意图理解能力,大幅降低了专业级图像生成的门槛。
姚霆博士对此评价道,HiDream-O1-Image展现出原生全模态架构在生成质量、复杂任务统一建模和规模扩展上,具备比传统DiT架构更高的潜力天花板。随着其图像及视频能力的持续开源,智象未来正将领先的原生全模态架构能力,转化为更开放、更普惠的AI行业基础设施。




