许多开发者在初次接触MMU(内存管理单元)时,都会产生一个根本性的疑问:内存地址为何需要翻译?直接访问物理地址不行吗?
这种困惑非常普遍,因为我们对“内存映射”的认知,通常局限于mmap()这类将文件映射到虚拟内存的API。

(内存映射机制原理图解)
然而,现代计算系统的现实要复杂得多。无论是Linux中通过malloc申请的内存、网卡执行DMA写入的数据、NVMe SSD发起的直接I/O、GPU访问CPU内存、虚拟机中的VFIO设备直通,还是容器运行AI推理时使用的固定内存(pinned memory)——所有这些操作的底层核心,都离不开“地址映射”机制。
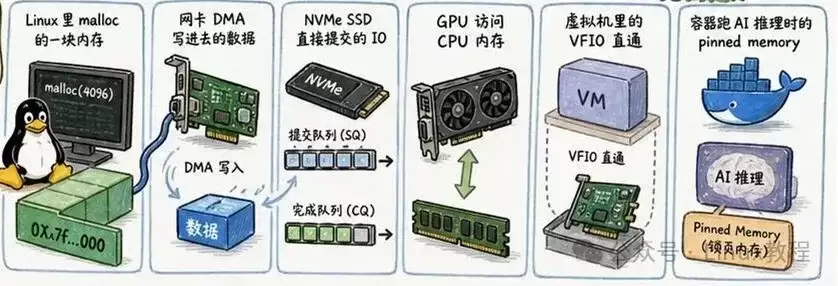
更精确地说,是“地址翻译”。
CPU在执行翻译,外设在进行翻译,IOMMU(输入输出内存管理单元)也在翻译,甚至PCIe设备自身也具备翻译能力。层层翻译之下,整个系统的内存访问路径变得异常复杂。
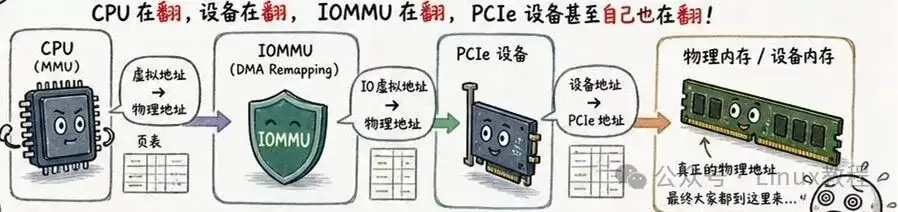
回到最初的问题:为什么地址需要翻译?这类似于询问:“人就是人,为什么需要身份证?”
答案在于系统的复杂性与多目标需求。CPU需要高效有序的内存访问,操作系统需要实现内存保护,虚拟化环境需要隔离不同租户,外设希望直接进行DMA,而GPU则追求绕过CPU直接访问内存。各方诉求交织,地址翻译便成为维持秩序、实现安全隔离与高效共享的技术基石。
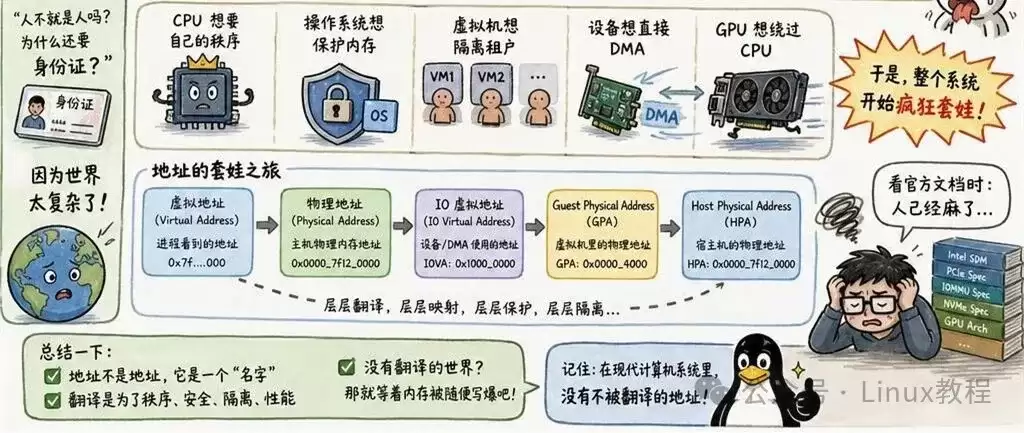
于是,Linux系统中涌现出多种地址概念:虚拟地址(VA)、物理地址(PA)、I/O虚拟地址(IOVA)、客户机物理地址(GPA)、宿主机物理地址(HPA)。阅读最新内核文档时,极易被这些术语困扰。
本文将从真实的数据流出发,彻底厘清内存地址翻译的完整脉络。
一、起源:从“地址空间不足”到虚拟内存
故事始于32位系统的经典瓶颈:4GB内存上限。即便物理内存扩容至8GB,系统也只能识别4GB,根本原因在于2^32 = 4GB的地址总线宽度限制。
这引出了三个核心需求:进程间如何安全共享内存?如何防止程序越界访问?如何让每个进程都拥有独立的、从零开始的连续地址空间幻觉?
MMU应运而生。其核心理念可概括为一句话:CPU发出的地址,并非真实的物理内存地址。 这听起来有违直觉。
考虑这段代码:
int *p = malloc(4);
*p = 123;CPU并非直接访问物理地址。它发出的是虚拟地址(VA),在触及DRAM之前,必须由MMU翻译为物理地址(PA)。基本流程如下:
CPU
↓
Virtual Address (VA)
↓
MMU (Translation)
↓
Physical Address (PA)
↓
Memory为何必须增加这层抽象?本质上是操作系统精心设计的“全局骗局”。其目标是让每个进程都认为自己独占完整的、从零开始的线性地址空间。这便是虚拟内存的核心思想。
许多应届生在面试时常被问到:“malloc调用后是否立即分配物理内存?”常见的错误答案是肯定的。在Linux中,malloc通常仅预留一段虚拟地址范围。真正的物理页分配往往延迟到首次访问该内存时,通过触发缺页异常(Page Fault)来完成。
示例:
char *buf = malloc(1024 * 1024 * 1024); // 申请1GB虚拟地址空间系统并未立即划拨1GB物理内存。操作系统仅记录:“该进程拥有1GB虚拟地址区间的使用权。”
直到执行首次写入:
buf[0] = 1;CPU发现页表中无此映射,触发Page Fault。内核此时才分配物理页、更新页表、刷新TLB,随后恢复程序执行。整个过程堪称CPU与操作系统为应用程序联袂上演的“魔术”。
二、性能关键:页表、TLB与大页内存
1. 页表演进:从单级到多级
最初的页表结构简单,是一个虚拟页号到物理页号的直接映射数组。但随着内存容量激增,问题凸显。假设采用48位虚拟地址、4KB页大小,虚拟页数量高达2^48 / 2^12 = 2^36个。若每个页表项占8字节,仅页表就将消耗2^36 * 8 = 512GB内存,这显然不现实。
因此,多级页表诞生。x86_64架构经典采用四级页表:PGD -> PUD -> PMD -> PTE。后续Intel推出了五级页表扩展。学习内核时,pte_offset_map()、pmd_offset()等函数如同在迷宫中寻路。
2. TLB:地址翻译的缓存
深入研究页表后,线上性能问题却可能依然存在。真正的瓶颈往往是TLB(转换后备缓冲区)。
TLB本质上是地址翻译的高速缓存。由于页表遍历(Page Walk)速度缓慢,CPU无法每次访存都查询多级页表。因此,MMU将最近的翻译结果缓存于TLB中。优化后的访问流程为:CPU发出虚拟地址 -> 优先查询TLB -> 命中则直接获得物理地址 -> 未命中则触发耗时的页表遍历。
挑战在于TLB容量极小,比L1缓存更为珍贵。一旦TLB未命中率升高,性能将急剧下降。曾有一个Redis实例优化案例:CPU利用率不高,但吞吐量上不去。使用perf分析发现,TLB-load-misses指标异常高。原因是业务使用了一个巨大的哈希表进行随机访问,内存局部性极差,导致CPU频繁进行页表遍历。最终启用HugePage(大页)后,TLB未命中率骤降,吞吐量显著恢复。
3. HugePage大页:性能救星
大页为何能显著提升性能?标准页大小为4KB,而大页通常为2MB或1GB。页尺寸增大后,同等数量的TLB条目可覆盖更大的内存范围。
举例说明,假设TLB有1024个条目:
- 使用4KB页:覆盖范围
1024 * 4KB = 4MB - 使用2MB大页:覆盖范围
1024 * 2MB = 2GB
覆盖范围存在数量级差异。当前AI训练尤其青睐大页,因为大模型参数量巨大,TLB难以承受。尤其在GPU统一内存场景下,页面迁移频繁,TLB刷新(shootdown)开销可能拖垮整个系统。
然而,TLB的最大挑战并非未命中,而是多核同步。每个CPU核心拥有独立的TLB。当某个核心修改页表后,其他核心的TLB缓存即告失效,必须通过处理器间中断(IPI)进行广播刷新。这种TLB同步在高并发场景下代价高昂。
三、IOMMU与虚拟化:设备的内存管理
CPU侧问题解决后,外设提出了新诉求。网卡需要DMA,SSD追求零拷贝,GPU希望直接读取用户态内存。设备DMA的核心特点是绕过CPU,因此设备无法感知CPU的虚拟地址空间,只能识别物理地址。

早期驱动开发异常繁琐:驱动程序需申请连续的物理内存,获取物理地址后,再告知设备DMA目标地址。此过程不仅复杂,且安全性极低——设备若DMA至错误地址,可能破坏整个系统内存。
于是,IOMMU(输入输出内存管理单元)登上舞台。
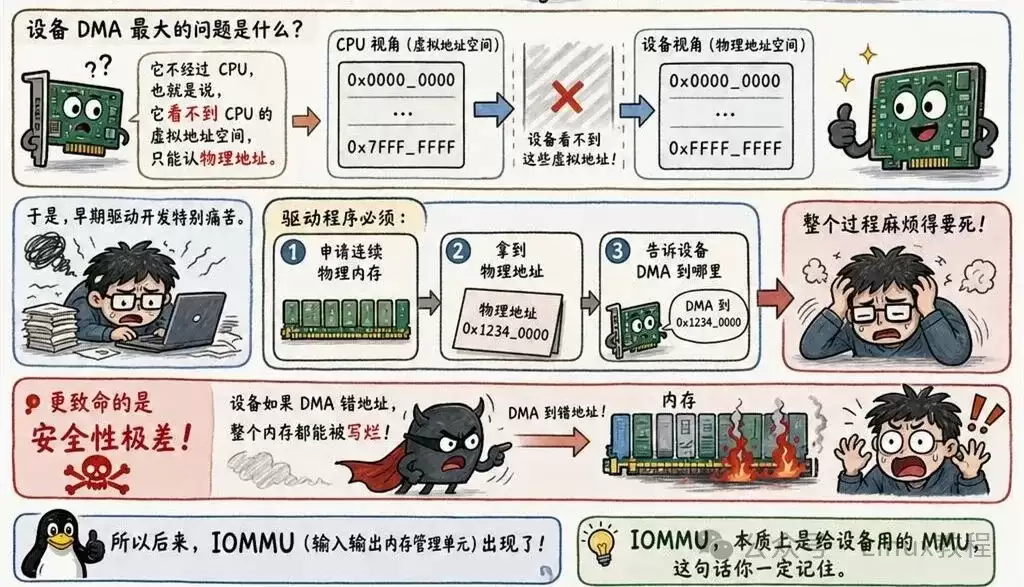
请牢记核心概念:IOMMU本质上是为设备服务的MMU。
- MMU为CPU翻译地址。
- IOMMU为设备翻译地址。
两者逻辑完全一致。

原本设备直接访问物理地址:Device -> Physical Address。引入IOMMU后,链路变为:Device -> IO Virtual Address (IOVA) -> IOMMU -> Physical Address。其核心仍是页表,仅服务对象从CPU变为PCIe设备。
在虚拟化时代,IOMMU变得至关重要。在裸机环境中,设备DMA错误最多导致系统崩溃。但在云计算场景中,若租户虚拟机直通了一块网卡,且设备可任意DMA,则可能读取宿主机内存、窃取其他虚拟机数据,甚至篡改内核数据结构。这已超越漏洞范畴,构成灾难性风险。
因此,Intel VT-d、AMD-Vi等技术广泛普及。IOMMU为每个设备建立独立的地址空间,例如:网卡1仅能访问虚拟机1的内存,网卡2仅能访问虚拟机2的内存。设备如同被置于“笼子”中,活动范围受到严格限制。
VFIO为何依赖IOMMU?许多人认为VFIO技术神奇,能使虚拟机直接使用物理GPU且性能无损。关键在于IOMMU。VFIO的核心是将设备的DMA权限限制在客户机内存范围内。整个链路呈现嵌套结构:
Guest Virtual Address (GVA)
↓
Guest Page Table
↓
Guest Physical Address (GPA)
↓
Host IOMMU
↓
Host Physical Address (HPA)可见,客户机操作系统自认为访问的是物理地址,实则仍是“虚拟”地址。虚拟化技术的精妙之处在于所有参与者均被“欺骗”:CPU、客户机操作系统乃至设备本身。
四、性能极限:DMA与地址翻译开销
DMA为何会成为性能瓶颈?许多人误以为DMA必然高速。DMA的核心优势在于数据搬运不占用CPU,但地址翻译本身存在开销。
设备执行DMA时,IOMMU同样需要查询页表。因此,设备侧也出现了自身的TLB,即IOTLB。假设一块100Gb网卡每秒执行数千万次DMA,IOMMU的页表遍历能否承受?答案是否定的。大量PCIe设备的性能受限于IOTLB未命中。
AI集群将IOMMU问题急剧放大。前些年许多公司搭建AI训练集群时,发现GPU间通信延迟波动剧烈,尤其在RDMA场景下。最终排查发现,问题根源在于IOMMU。GPU的DMA请求过于猛烈,在大规模参数同步时,若未启用PCIe ATS(地址翻译服务),IOTLB未命中率将飙升,导致延迟如心电图般波动。许多运维工程师的第一反应是怀疑网卡故障,实则问题出在地址翻译体系不堪重负。
此时,ATS(地址翻译服务)登场。名称听起来像某种云服务,实则是PCIe协议中的地址翻译机制。其核心思想极为简单:让设备自身缓存地址翻译结果。 这与CPU的TLB思路如出一辙。
传统设备DMA流程:设备发起请求 -> IOMMU查询页表 -> 返回物理地址。启用ATS后,设备本地具备ATC(地址翻译缓存),命中则可直接DMA。本质上,这又是一层缓存。计算机领域的许多高端技术,剖析后核心仍是缓存。
ATS为何意义重大?因为PCIe设备日益“智能化”。早期设备仅是简单数据搬运工,现代GPU支持页迁移,智能网卡(SmartNIC)可运行协议栈,DPU负责虚拟化卸载,NVMe设备支持点对点DMA。设备行为越来越接近CPU,因此必须降低地址翻译开销。尤其在AI时代,GPU每秒吞吐高达数TB,若每次DMA都需询问IOMMU“此地址对应何处?”,总线早已堵塞。ATS的意义在于赋予设备部分MMU能力。
ATS工作流程简洁:设备首次DMA某地址时,向IOMMU发起翻译请求并缓存结果;后续访问同一内存页时,直接命中缓存,效率极高。
当然,ATS也引入新挑战:缓存一致性。缓存永远面临失效同步问题。CPU TLB存在shootdown,ATS亦然。若页表更新,设备的翻译缓存必须失效。PCIe协议专门定义了无效化请求(Invalidate Request),设备收到后需清除对应翻译缓存,否则可能导致DMA至错误地址,此问题极为严重。
五、演进形态:SVA、PASID与统一内存
1. PASID:进程地址空间标识
若ATS仅是缓存,设备如何区分“此地址属于哪个进程”?于是,PASID(进程地址空间ID)出现。传统设备DMA仅有一个地址空间,但现代GPU、DPU、NVMe均需直接访问用户态内存,因此设备必须支持多进程、多地址空间。PASID本质上是地址空间的编号。设备DMA时,除虚拟地址(VA)外,还需携带PASID,以便IOMMU查询对应进程的页表。
2. 共享虚拟地址(SVA)
SVA(Shared Virtual Addressing)出现后,CPU与设备终于开始共享同一套虚拟地址空间。以往CPU使用VA,设备使用IOVA,需要来回映射。现在,GPU可直接使用进程的虚拟地址,例如malloc分配的缓冲区,GPU可直接DMA,无需额外的固定(pin)操作或中转缓冲区(bounce buffer)。这正是现代异构计算的核心。
3. CUDA统一内存的幕后
首次接触CUDA统一内存(Unified Memory)时,许多人惊叹于NVIDIA的黑科技——CPU与GPU共享同一指针,甚至无需cudaMemcpy。看似神奇,背后实则是IOMMU、ATS、PASID以及页错误重放(Page Fault Replay)等一系列技术协同的结果。
简言之,当GPU访问某地址时,若对应页不在本地显存中,将触发页错误。随后驱动自动迁移页面、更新地址映射,GPU重新执行访问。此机制初看令人难以置信,因为GPU行为已愈发接近CPU。
4. PRI:页请求接口
PRI(页请求接口)使设备在发现页不存在时,能主动请求操作系统补页。是否越来越像CPU的Page Fault?没错,设备正逐步获得完整的虚拟内存能力。
六、实战经验与性能调优
1. Linux内核中的iommu_map()
先看代码,这是Linux IOMMU子系统的核心函数之一:
int iommu_map(struct iommu_domain *domain,
unsigned long iova,
phys_addr_t paddr,
size_t size,
int prot)其本质是建立IOVA到物理地址的映射。设备DMA时访问IOVA,由IOMMU负责翻译。这与CPU的页表映射完全同构:VA -> PA。理解系统的最佳方法之一,正是寻找此类“同构关系”。
2. DPDK为何常要求关闭IOMMU?
此问题非常经典。许多新手首次运行DPDK时,会在内核参数中添加intel_iommu=off,并产生困惑:IOMMU不是更安全吗?为何关闭后性能反而提升?
原因在于老旧设备不支持ATS,每次DMA均需经过IOMMU,性能损耗显著。尤其在早期40G网卡时代,IOTLB压力巨大。因此许多公司选择关闭IOMMU,直接采用大页配合物理地址DMA,方法简单粗暴但速度快。然而,当前情况正在改变,新一代智能网卡、GPU、NVMe广泛支持ATS,IOMMU的开销正被逐步消化。
3. SR-IOV的本质亦是地址空间隔离
许多人认为SR-IOV仅是“网卡虚拟化”,其底层核心仍是映射。
- PF(物理功能):物理功能
- VF(虚拟功能):虚拟功能
每个VF拥有独立的DMA空间、队列、中断及地址空间,最终依赖IOMMU实现隔离。因此,SR-IOV与IOMMU基本绑定,缺乏IOMMU,许多VFIO场景根本不敢上线。
4. NUMA使地址翻译更复杂
许多性能调优仅关注CPU,实则NUMA(非统一内存访问)才是真正的性能“陷阱”。尤其在双路服务器中,内存并非统一,每个CPU插槽拥有自己的内存控制器。因此,地址翻译后还需决定访问哪一块物理内存。跨NUMA节点访问将导致延迟显著上升。
AI训练中最恐怖的场景之一:GPU挂载在NUMA0节点,但内存分配在NUMA1节点。结果导致PCIe流量绕远,带宽直接腰斩。曾有一个案例,客户斥资数百万购置GPU集群,性能仅为理论值的40%,最终发现仅是NUMA绑定配置不当,现场气氛一度凝重。
5. 页表遍历(Page Walk)成本高昂
许多人低估了Page Walk的开销。一次TLB未命中,可能意味着:多次内存访问(遍历多级页表)、缓存未命中、以及流水线停顿。现代CPU为加速Page Walk,甚至专门设计了页表遍历缓存(Page Walk Cache)。你会发现,整个CPU架构愈发“魔幻”,处处是缓存套缓存:TLB缓存页表项,Page Walk Cache缓存页表遍历中间结果,L1/L2/L3缓存数据……最终,整个芯片几乎由各种缓存构成。
6. CXL为何日益重要?
近年来CXL(Compute Express Link)备受关注,许多人视其为“一种新型总线”。其核心在于内存语义的共享。CPU、GPU、FPGA、DPU均希望共享同一套内存语义,这导致地址翻译复杂度再次飙升。CXL Type-3内存设备本质上使外设成为“内存的扩展”。这意味着什么?意味着设备不再仅是设备,而是系统内存的一部分。在此背景下,ATS、PASID、SVA等技术将愈发关键。
七、完整链路梳理
许多人学习内核数年,仍对内存映射感到困惑,因为资料过于零散。某本书讲解MMU,另一本剖析PCIe,还有一本探讨虚拟化,但缺乏完整链路串联。
以往指导实习生时,最常提问:“GPU DMA一个用户态缓冲区,究竟经历了几次地址翻译?”许多同学听后茫然。此问题能立即检验你对系统的理解深度,而非仅停留在API层面。
以下完整梳理该链路:
用户态:
buf = malloc(4096);CPU访问时: CPU通过MMU,将虚拟地址(VA)翻译为物理地址(PA)。
GPU DMA时: GPU发起携带PASID的虚拟地址访问 -> 先查询自身ATC缓存 -> 若未命中,则请求IOMMU -> IOMMU将其翻译为宿主机物理地址(HPA)。
若页不在内存中: 触发页错误 -> 操作系统执行补页 -> 更新页表 -> 无效化相关ATS缓存 -> GPU重试DMA。
可见,现代系统已复杂到设备与CPU共同维护虚拟内存。
计算机发展至今,本质仍在搬运数据。大学时期,教授反复强调算法复杂度,令人误以为CPU是世界的中心。工作十年后发现,真正折磨人的往往不是计算,而是数据的移动。CPU等待内存,GPU等待PCIe,网卡等待DMA,SSD等待队列……整个系统都在“等待”。而地址翻译,正是这场漫长等待中的核心环节。




