DeepSeek V4 API正式上线 双版本支持百万上下文

百万字上下文,从此成为普惠标配。
万众期待之下,DeepSeek V4预览版,终于揭开了面纱。两个版本——V4-Pro与V4-Flash,全系标配百万字(1M)超长上下文,并同步开源了模型权重与技术报告。
五一假期前的这两天,大模型领域再次迎来密集发布潮。
就在前一天,腾讯混元Hy3预览版亮相,凭借2950亿参数的MoE架构与极具竞争力的价格,展示了其在规模化商用上的野心。紧接着,OpenAI面向付费用户上线了GPT-5.5,并官宣了API计划,主打Agent工作流,同时将上下文窗口拉升至百万tokens,定价也随之水涨船高。
表面上看,三家的路径各有侧重:OpenAI坚守高端闭源路线,不断抬高能力与价格的天花板;腾讯将模型深度融入自家生态,试图以性价比撬动市场;而DeepSeek则延续了开源普惠的传统,并将长上下文能力推向了新的临界点。
然而,一个共同的趋势也清晰浮现:Agent能力、超长上下文、代码与工具调用,这三个关键词在最新发布的模型中反复出现。行业的竞争焦点,正从单纯的“智力比拼”,转向谁能更稳定、更高效地处理复杂任务,真正嵌入工作流中“干活”。
DeepSeek V4的“实用主义”
DeepSeek此次发布,最核心的动作是将百万字上下文从“高端选配”变成了“基础标配”。在此之前,处理如此长的文本,往往是少数闭源旗舰模型的专属能力,其高昂的调用成本让大多数开发者和企业望而却步。
DeepSeek的策略非常明确:V4-Pro和V4-Flash两个版本,全部标配1M上下文长度。前者锚定极致性能,后者主打普惠经济,完整覆盖了从高端到轻量化的不同需求。这种“无差别下放核心能力”的做法,本质上是彻底降低了长文本处理能力的行业门槛。

其中,Flash版本瞄准的是极致低延迟与高性价比场景。它通过13B的激活参数、创新的token压缩注意力机制与DSA稀疏注意力架构优化,在保障接近Pro版核心推理能力的同时,实现了极快的响应速度。这对于实时对话、函数调用流水线等所有对响应速度敏感的场景而言,意味着体验上的本质提升。
更关键的是其极具竞争力的成本结构。根据官方API定价,Flash版本采用阶梯计费:缓存命中的输入token低至0.2元/百万tokens,即便缓存未命中,输入成本也仅为1元/百万tokens,输出定价为2元/百万tokens。
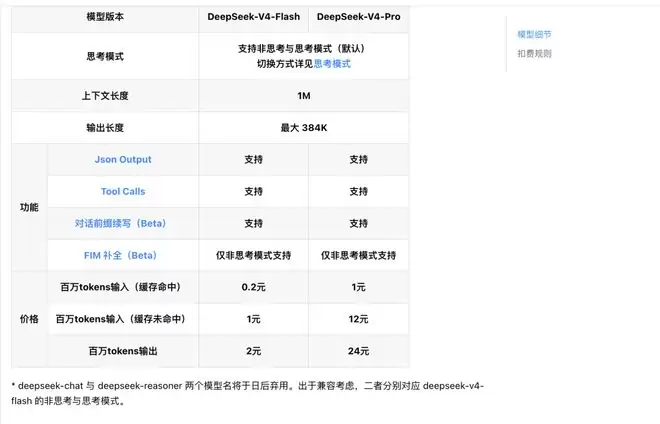
如此亲民的定价,叠加全系标配的百万字上下文,使得“单次调用成本”不再成为工程设计的核心约束。开发者可以更专注于产品体验与架构设计,而无需在调用次数与费用之间反复权衡。
如果说Flash解决的是“用得起、用得快”的普惠需求,那么V4-Pro则在回答另一个问题:开源大模型的能力边界,究竟还能被推到多高。
最直观的跃升依然是长上下文。模型上下文长度从上一代V3.2的128K,直接拉升至1M。配合底层架构的创新,它在大幅降低长上下文计算与显存需求的同时,保障了全窗口的性能无损。这意味着,开发者可以直接导入完整的代码库、超长行业文档或多轮项目档案进行端到端处理,无需额外搭建复杂的检索增强生成(RAG)系统,技术链路被大幅简化。
在底层架构上,Pro版本采用了总参数1.6T、激活参数49B的MoE架构,预训练数据量达33T。最新评测数据显示,其在数学、STEM、竞赛级代码等核心推理测评中,超越了当前所有已公开评测的开源模型,达到了比肩世界顶级闭源模型的水平。在Agent能力上,其交付质量已接近Claude Opus 4.6的非思考模式,内部反馈优于Anthropic Sonnet 4.5,成为了团队内部的主力Agentic Coding工具。
功能层面,V4全系列均同时支持非思考模式与思考模式,开发者可通过参数自定义思考强度,并全量支持Json输出、工具调用等能力。定价方面,Pro版本同样延续高性价比路线,显著低于海外同级别闭源模型。
API接入也做到了极致低门槛,开发者无需修改原有基础地址,仅需替换模型名称即可完成接入,同时兼容OpenAI与Anthropic两种主流接口格式。
这种“能力上探”与“成本下探”的组合拳,让顶级的大模型能力不再是少数厂商的专属资源。当行业竞争一度陷入参数军备竞赛的怪圈时,DeepSeek用全系标配百万上下文、全链路开源开放的选择,为AI的普惠化提供了一个新的范本。
继续开源,API全量开放
DeepSeek再次明确了其开源路线的决心,并直接全量开放了API调用。
目前,DeepSeek-V4的模型权重已同步在Hugging Face、ModelScope等平台开放下载,配套的技术报告也一并公开,支持开发者进行本地部署与二次开发。
值得注意的是,与部分厂商“开源阉割版,闭源完整版”的行业惯例不同,本次开源的两个版本,完整保留了与最新云端API一致的全量能力——包括非思考/思考双模式、百万字超长上下文无损处理、Agent专项优化与全量工具调用能力,没有任何功能上的缩水。
这意味着,无论是中小创业公司、个人开发者还是科研机构,都能零门槛获取到具备百万上下文、顶级推理与Agent能力的大模型底座,无需再为高端模型能力支付高额的闭源接口费用。
为了进一步降低落地门槛,DeepSeek同步开源了模型微调、量化、推理加速的全流程工具链,并完成了对vLLM、TGI等主流推理框架,以及LangChain、LlamaIndex等主流Agent框架的“Day 0”原生适配。同时,也开放了国产算力平台的全栈部署方案,确保开发者在不同硬件环境下都能快速落地应用。
此外,官方也给出了清晰的模型迭代过渡方案:旧有的API接口模型名将于三个月后停止使用,当前阶段它们已自动指向新版本,为开发者留出了充足的平滑迁移时间。
坚定做AI“基建模型”
将这两天的密集发布连起来看,一个趋势已经非常明确:各家都在加速押注Agent能力。
过去两年,公众和资本市场对大模型的关注,很大程度上集中在模型的“聪明程度”。但现在,焦点已经转向了“谁更能稳定地把事情做完”。GPT-5.5的发布重点不在于多模态理解又提升了多少,而在于其在Agent编程、计算机使用等场景中的持续执行能力。腾讯混元Hy3的核心卖点也在于其在现实世界中的“行动能力”。DeepSeek V4则直接把Agent能力和长上下文处理作为主打,目标明确地指向实际工作负载。
这种转变的背后,是整个行业正在走向“模型效用”的竞争。用户和企业客户越来越不关心模型在某项评测里排第几,他们关心的是:这个模型到底能帮自己干好多少活儿?能不能稳定处理复杂文档?能不能在多步骤任务里不出错?能不能以合理的成本跑起来?

在本次发布的文末,DeepSeek引用了《荀子》中的一句话:“不诱于誉,不恐于诽,率道而行,端然正己”,以此锚定自身的技术路线。放在当下激烈的大模型竞争语境中,这句话的意味很明确——不被外界的评价和噪音干扰,专注于把事情做对。
回顾DeepSeek过去一年多的行动,确实在践行这一逻辑:用开源开放建立全球开发者生态影响力,用极致的性价比打破高端AI能力的使用壁垒,用扎实的底层架构创新解决开发者与企业用户最真实的痛点。
从R1推理模型的横空出世,到V4将长上下文能力第一次推向普惠区间,DeepSeek一直在用一种相对“慢”的方式,做一件更难的事:把顶级模型能力,从少数人的工具,变成更多人可以直接调用的基础设施。
相关攻略

想要基于DeepSeek V4构建一个能够精准理解产品手册内容的智能问答系统?这个需求非常贴合企业知识管理的实际场景。直接对大模型进行微调不仅成本高昂、周期漫长,对于需要即时准确响应的内部知识库应用而言,采用检索增强生成(RAG)架构无疑是当前更高效、更实用的技术路径。 然而,DeepSeek V4

想用上DeepSeek最新的V4 Pro版本,体验它那更强的推理能力?你可能已经接入了API,或者在网页端、APP端看到了相关功能,但感觉效果和预期有差距。这很可能是因为你的会话还运行在默认的“快速模式”上。要真正激活那个拥有1 6T参数、采用MoE 4 0架构并具备R1推理增强的深度模型,你需要手

当您在Ollama中尝试运行DeepSeek V4模型时,如果遇到进程卡死、无响应或直接报错退出的问题,请不要急于归咎于您的硬件设备。这很可能源于一个关键原因:截至目前,DeepSeek V4模型尚未在Ollama的官方模型库中正式发布。更重要的是,其公开发布的原始权重格式(通常是Hugging F

将DeepSeek V4的原始PyTorch权重转换为AWQ格式,是在有限显存条件下实现低延迟、高精度推理的成熟方案。AWQ(激活感知权重量化)的核心原理非常巧妙:它并非对所有参数进行均等压缩,而是通过分析模型在前向传播中的激活分布,精准识别并保留对输出结果影响最显著的“关键权重”。这种方法使得模型

手头已经下载了DeepSeek V4的模型文件,但在llama cpp中直接加载却无法运行?这通常是因为模型尚未转换为llama cpp兼容的GGUF格式,或者没有针对您的硬件配置进行适当的量化优化。别担心,按照以下系统化的操作流程,您就能顺利解决这一问题。 一、确认模型原始格式并获取适配分支 目前
热门专题







热门推荐

为庆祝品牌投身赛车运动整整125年,斯柯达正式推出了晶锐Fabia Motorsport Edition特别版。这款车基于Fabia 130打造,设计灵感直接来源于征战赛场的Fabia RS Rally2拉力赛车,整体风格充满了对赛事历史的致敬意味。不过,得先说明白,它的升级重点主要落在了外观和底盘

Grayscale 通过其以太坊质押 ETF 质押了 102,400 个 ETH,价值 2 37 亿美元 先来看一组数据:资产管理巨头 Grayscale 最近通过其以太坊质押 ETF,一口气质押了超过10万个 ETH,价值约2 37亿美元。这个动作本身不小,但更有意思的是市场的后续反应——或者说,

劳斯莱斯库里南自问世以来,始终是超豪华全尺寸SUV领域的标杆。对于追求极致安全又不愿牺牲低调气质的高净值人士而言,如何实现“隐形”的顶级防护,一直是核心诉求。如今,加拿大专业防弹车制造商Inkas,以一款近乎“零痕迹”改装的库里南,给出了完美解决方案——一座移动的“隐形堡垒”。 区别于常见的外露装甲

新加坡维塔士工作室正考虑将《侠盗猎车手V》与《荒野大镖客:救赎2》移植至任天堂Switch平台。该团队拥有丰富的移植经验,曾成功负责多款游戏的跨平台适配。这两款作品全球销量巨大,若能登陆Switch,其便携特性可能成为新的市场增长点。

当高尔夫GTI迎来五十周年里程碑,传奇的纽博格林北环赛道成为其致敬历史与展望未来的最佳舞台。这里不仅铭刻了燃油性能图腾的巅峰时刻,也正式开启了电动GTI的新纪元。近日,大众汽车正式宣布,高尔夫GTI 50周年版在纽北创下全新纪录,荣膺最快前驱量产车称号;与此同时,品牌首款纯电动GTI车型——ID