ICML 2026论文解读:TGO标量反馈对齐视觉生成模型
生成模型的偏好对齐,可能正在进入一个新的阶段。
过去几年,大模型在训练后优化(post-training)最主流的方法,是让模型从“成对偏好”中学习。无论是经典的RLHF,还是后来更简洁的DPO,都绕不开同一个前提:反馈必须成对出现。
但在真实世界里,反馈往往不是这样。用户给一个结果打分、系统记录一次点击停留、或者奖励模型输出一个标量分数——这些才是更常见的监督信号。它们都是独立的、点状的,而不是配好对的。

面对这个矛盾,新加坡国立大学的研究团队提出了一个更直接的解法:Threshold-Guided Optimization(TGO)。这是一种不依赖成对偏好数据,直接利用独立样本的标量评分进行模型对齐的新范式。
思路很直观:从所有样本的分数分布里,估计出一个阈值(比如中位数)。高于这个阈值的样本,就被视为“伪正例”;低于阈值的,则是“伪负例”。训练时,模型的任务就是提高伪正例相对于参考模型的生成概率,同时降低伪负例的概率。
不仅如此,TGO还引入了一个巧妙的权重机制:样本分数离阈值越远,说明这个“好”或“坏”的判断越确定,它在训练中的权重也就越大。反之,那些在阈值附近徘徊的“模糊样本”,对模型更新的影响则较小。
目前,这项研究已被ICML 2026接收。它的核心价值在于,让生成模型的对齐不再只纠结于“哪个更好”,而是开始直接利用“这个有多好”的信息。

DPO的优雅,源于成对数据
DPO能成为偏好对齐领域的代表方法,关键在于它做了一次漂亮的数学转换。它将原本复杂的、带KL约束的强化学习目标,改写成了一个可以直接用分类损失来训练的形式。
这样一来,模型既不需要显式训练一个奖励模型,也省去了像PPO那样费时费力的在线采样。只要有离线的偏好对数据,就能完成策略优化。
其背后的数学原理很清晰:在KL正则化的对齐目标下,最优策略有一个闭式解,但这个解里包含一个需要对所有可能输出求和的归一化项(partition function),这通常是无法计算的。
DPO的巧妙之处在于,当你在同一个提示词下,比较一个“优选”输出和一个“劣选”输出时,这个难算的归一化项会在奖励分数的差值中被抵消掉。也就是说,DPO的简洁性,很大程度上是“成对比较”这个数据结构所赋予的。两个输出一比,难题就消失了,问题转化为了一个相对概率的分类问题。
然而,这个优势也成了它的限制。一旦监督信号不再是成对的“胜负”,而是单个样本的标量分数,那套靠“两两相减”来抵消归一化项的办法就不灵了。
实践中常见的应对策略,是把标量分数强行转换成偏好对。例如,在一个批次内排序,把高分样本当赢家,低分样本当输家;或者对同一提示词下的多个候选结果进行两两组合,构造出虚拟的偏好对。
这种做法当然能跑通,但不可避免地会造成信息损失。想想看,一个9.5分的样本和一个7.5分的样本,在成对训练里可能都被视为“赢家”,它们之间的质量鸿沟被抹平了。而一个4.9分和一个4.8分的样本,可能被硬生生拆成一组“赢家”和“输家”,当评分噪声较大时,这种人为构造的偏好关系很可能是不准确甚至误导性的。
对于视觉生成任务,这个问题尤为突出。一张图像的好坏,很少是简单的二元判断。它可能审美出众但文本贴合度一般,也可能构图精准但风格不受欢迎。视频生成则更复杂,还要考量运动是否自然、主体是否稳定、时间是否连贯。很多时候,一个连续的分数,远比一个简单的“赢/输”标签更能反映真实的反馈。
三条路线,都在放松“成对”约束
事实上,TGO并非孤立出现。近期领域内的几项重要工作,都在回应同一个核心问题:偏好优化能否摆脱对成对数据的强依赖?
PMPO:接受不成对的正负反馈
首先是Google DeepMind的《Preference Optimization as Probabilistic Inference》。这项研究的出发点是,模型不一定非要看到严格配对的“正例/负例”才能学习。
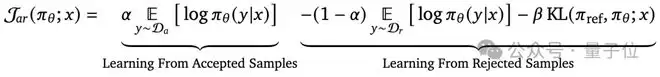
即使只有正例样本,或只有负例样本,甚至两者都有但不成对,优化依然可以进行。

方法上,它基于一种期望最大化(EM)风格的策略改进框架,将目标分解为三部分:提高正例样本的似然,降低负例样本的似然,同时保持新策略不要偏离初始策略太远。这条路线的核心优势在于反馈结构极其灵活,更贴合现实世界中数据收集的常态——我们常常只能得到“这个不错”或“这个不行”的孤立反馈,而非严谨的对比。
QRPO:直接拟合绝对奖励
另一篇论文《Quantile Reward Policy Optimization》则 tackling 了另一个方向:如果我们手握的是每个样本的绝对奖励值,能否直接进行策略拟合?
这里依然绕不开那个“拦路虎”——归一化项。

QRPO的解决方案是将原始奖励转换为分位数奖励。经过这番转换后,在参考策略下,分位数奖励的分布会变成均匀分布,这使得归一化项有了解析解。于是,模型可以通过一个简单的点态回归目标,直接拟合出KL正则化目标下的最优策略,无需再依赖成对比较来抵消归一化项。
TGO:为视觉生成设计的阈值方案
而本文介绍的TGO,回答的是同一问题的另一个切面。

如果说PMPO关心的是不成对的正负反馈,QRPO致力于解决绝对奖励的解析拟合,那么TGO则面向视觉生成模型,选择了一条更轻量、更直观的路径:基于阈值的引导优化。这三项工作的共同指向很明确:它们都在试图将偏好优化从“必须成对”的紧身衣中解放出来。
TGO的核心:用阈值近似那个不可算的基线
TGO的方法看似简单——设定一个阈值,然后分类训练。但其背后有严谨的理论推导,源自经典的KL正则化对齐目标。
这里的关键问题是:对于一个给定的样本,最优策略到底应该提高还是降低其生成概率?理论上,这取决于该样本的奖励值是否超过一个特定的、与实例相关的“神谕基线”。如果奖励高于基线,就应提高概率;反之则降低。
麻烦在于,这个“神谕基线”与难以计算的归一化项相关。DPO用成对比较让它抵消了;QRPO通过分位数变换让它可解析了;TGO则选择用一个从数据中估计出的全局阈值来近似它。
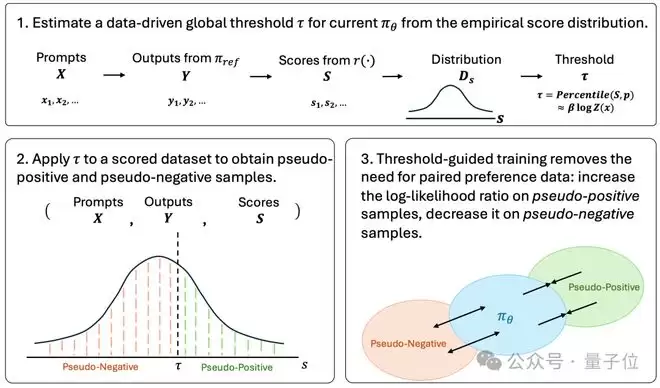
具体操作上,TGO首先从所有带分数数据集的分布中估计一个阈值(常用中位数)。分数高于阈值的样本被视为“伪正例”,低于的视为“伪负例”。训练时,模型学习调整其相对于参考模型的对数似然比:对伪正例提高,对伪负例降低。
更进一步,TGO引入了置信度加权。样本分数离阈值越远,意味着将其判为正例或负例的置信度越高,该样本对训练的贡献权重也就越大。分数紧贴阈值的“模糊样本”,权重则相应降低。这就形成了一套双层决策机制:阈值决定更新方向(向上或向下),距离决定更新力度(强或弱)。
这也是TGO与简单二值化方法的本质区别。后者只保留正负标签,丢弃了分数所包含的“确信度”信息。而TGO通过置信度加权,巧妙地将分数的幅度信息转化为了监督信号的强度。对于视觉生成这种评分噪声大、质量评判连续的任务,保留这部分信息至关重要。
当然,TGO并非万能。它并不能消除对反馈质量本身的依赖。如果打分器本身有偏差或噪声很大,那么基于此分数估计出的阈值以及产生的伪标签,也会继承这些偏差。TGO解决的是“如何更直接地利用标量反馈”,而非替代反馈建模本身。
为什么视觉生成尤其需要标量反馈?
在语言模型中,成对偏好很自然。比较两个回答哪个更好,对人类来说往往比直接打分更稳定。但在视觉生成的领域,情况有所不同。
一张图像的质量,是审美、语义对齐、构图、风格、色彩等多种维度的综合体现,很难用一个简单的“A胜过B”来概括。视频生成则更为复杂,还需评估运动合理性、时间一致性、主体稳定性等动态要素。
将这些多维度的、连续的评估信号强行压缩成非此即彼的二元偏好对,必然会损失大量有价值的信息。真实产品环境中的用户反馈,也更接近于标量或隐式反馈:一个分数、一次点赞、一段观看时长、或者对生成结果的编辑行为。这些信号天然不成对,却是模型迭代改进的宝贵数据源。如果对齐方法只能处理“赢家/输家”数据,就很难充分利用这些更自然的反馈形式。
TGO瞄准的正是这个缺口。它不要求每个提示词下都有多个候选结果进行对比,也无需人工构造偏好对。只要每个生成的样本有一个分数,就能直接用于训练。这让视觉生成模型的对齐过程,得以更贴近真实世界反馈的收集方式。
从图像到视频:TGO的广泛验证
研究团队在多种视觉生成范式上验证了TGO的有效性,包括基于扩散的模型(如Stable Diffusion v1.5, FLUX, Wan 1.3B)和基于掩码的生成模型(如Meissonic)。这表明TGO并非某种特定架构的“技巧”,而是一种通用的、适用于标量反馈的对齐框架。
在图像生成实验中,TGO在Pick-a-Pic、PartiPrompts和HPSv2等多个测试集上进行了评估,并使用了HPSv2.1、PickScore、ImageReward等多种奖励模型作为评价指标。
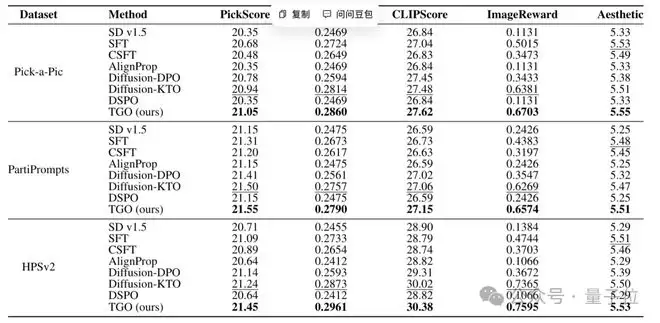
结果显示,与SFT、DPO及其变体等多种基线方法相比,TGO在多数设置下都能取得更高的奖励模型分数。更重要的是,它在多个不同的奖励模型上均有提升,这缓解了“奖励黑客”的担忧——模型并非仅仅过拟合某个特定打分器,而是在更广泛的视觉偏好维度上获得了真实改进。
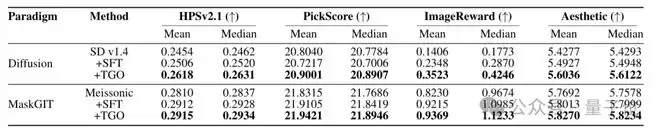
在视频生成任务上,采用LoRA适配的TGO方法也在Wan 1.3B模型上结合VideoReward进行了测试。结果不仅提升了整体视频奖励分数,在多个子组件指标上也有改善。这证明基于阈值的标量反馈优化,具备从图像扩展到更复杂视频生成的潜力。
不是取代,而是扩展:补上另一种反馈接口
需要明确的是,TGO并非要否定DPO的价值。成对偏好在许多任务中仍然是稳定且直观的反馈形式,尤其是当人类难以给出绝对分数,却易于比较两者优劣时。
但问题在于,成对偏好不应该是唯一的接口。随着生成模型深入更多真实应用场景,反馈形态正变得日益多样:语言模型有奖励模型分数、代码通过率;视觉模型有审美分数、人类评分;多模态系统还有点击、停留、编辑等用户行为信号。这些反馈大多是点状的、独立的。
如果对齐方法只能处理比较数据,就会与大量自然产生的监督信号失之交臂。PMPO、QRPO和TGO的共同意义,正在于将偏好优化从“成对监督”扩展到更一般的“反馈优化”。
PMPO证明了不成对的正负反馈可通过概率推断融入策略改进;QRPO证明了绝对奖励可通过分位数变换实现解析拟合;TGO则表明,对于视觉生成,一个经验阈值加置信度加权,就足以将标量分数转化为有效的对齐信号。
为什么现在这件事变得如此重要?因为生成模型越贴近产品,反馈形态就越复杂。早期的研究可以假设拥有干净的偏好对数据,但真实用户不会总是配合做A/B测试。更多时候,系统能捕获的只是一个分数、一次交互、一段行为日志。这些看似零散的信号,很可能构成下一代模型后训练的主要数据来源。
对于视觉生成,这一点尤其关键。图像与视频的质量本质上是多维且连续的。直接从标量反馈中学习,可能比先将其强行转换为成对偏好更为自然,也更具可扩展性。
TGO的价值正在于此。它没有将问题复杂化,而是以一种相当克制的方式,将标量反馈接入了KL正则化对齐的框架。理论上,它用经验阈值近似了不可计算的神谕基线;工程上,它仅需带分数的样本即可训练;实践上,它能同时覆盖扩散模型和掩码生成模型,并在图像与视频任务上带来稳定提升。

这或许标志着生成模型对齐进入了下一个阶段:模型不能只学会从“谁赢了”中学习,还必须学会理解“这个结果到底有多好”。
回顾过去,成对比较曾是偏好对齐的主流接口,它清晰有效,催生了DPO等一系列简洁方法。但当生成模型走向更广阔天地时,反馈本身正在变得多元。评分、通过率、行为日志……这些点状信号将越来越常见。
TGO给出的答案直接而实用:不必总将它们折叠成“赢家”和“输家”。对于视觉生成模型,找到一个合理的阈值,就能将标量分数转化为更新方向;再利用分数与阈值的距离,来衡量监督信号的可信度。这不是一个复杂的重型系统,而更像是在教模型更直接地“听懂”真实世界本就存在的丰富反馈。
如果说DPO让偏好优化摆脱了复杂的强化学习,那么TGO、QRPO和PMPO这类工作,正在让偏好优化进一步摆脱对“成对比较”的强制依赖。生成模型对齐的下一步,或许就在于让模型不仅能判断“哪个更好”,更能深刻领会:“这个,究竟好在哪里。”
参考文献:
[1] Preference Optimization as Probabilistic Inference, https://arxiv.org/abs/2410.04166
[2] Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions, https://arxiv.org/abs/2507.08068
[3] Threshold-Guided Optimization for Visual Generative Models, https://arxiv.org/abs/2605.04653
相关攻略

驾车经过惠山隧道入口时,许多驾驶员都曾对那组特殊的信号灯感到困惑。请务必注意——这并非传统的红绿灯,而是一套基于数字分车道的智能交通协调系统。 此处是惠钱路匝道与古华山匝道的交汇节点,以往两股车流同时汇入隧道时,极易因抢道引发交织冲突与安全隐患。为彻底解决这一交通瓶颈,交管部门在此创新部署了这套带有

想象一下,你正在学习投篮。一位经验丰富的教练站在场边,他关注的远不止“球进没进”,而是你手腕的角度、起跳的时机、身体重心的控制。这种对“动作完成质量”的直觉判断,是人类教练数十年经验的结晶,但对计算机而言,却曾是一个近乎无解的难题。 长期以来,计算机视觉的研究重心在于让机器识别“人在做什么”,例如区

隐式Null检查优化是JIT编译器提升性能的一种技巧,它通过CPU内存保护异常替代显式判空指令,减少分支开销。该优化需满足对象稳定、偏移固定等条件,依赖操作系统快速异常处理。虽能提升性能,但可能增加调试难度,并在某些安全环境中失效。

毛吉富团队研发出免缝合三维导电心肌补片,表面微米级导电“倒刺”可快速锚定心脏并重建电信号通路,动物实验中三天内改善心功能。团队还开发无线供电智能敷料等医用纺织材料,通过纤维材料创新解决心梗、慢性伤口等临床难题。

ADA 走强:鲸鱼交易频现与看涨信号浮现 最近,Cardano(ADA)的表现相当抢眼。一边是价格节节攀升,另一边则是链上大额交易异常活跃。这种“量价齐升”的局面,很难不让人多看几眼,市场信心似乎正在凝聚,未来的上升空间或许值得期待。 鲸鱼交易活跃度飙升 链上数据不会说谎。最新数据显示,Cardan
热门专题







热门推荐

机器人行业迎来里程碑式突破。以视频生成模型Vidu著称的生数科技,正式发布了名为Motubrain的“世界动作模型”。这并非一次普通迭代,而是被定位为机器人的“物理大脑”,其核心目标在于:用一个统一的通用模型,彻底取代以往依赖多个专用系统拼凑而成的复杂架构。 正如其“一个大脑,无限可能”的口号所揭示

xAI正式进军AI编程智能体领域,于近日发布了专为软件工程与复杂编程任务设计的Grok Build。 简单来说,Grok Build是一款能在终端里直接跑起来的AI编程助手。它被定位为一个具备智能体能力的命令行工具,开发者用自然语言告诉它要做什么,它就能生成代码,甚至帮你搞定一系列编程和自动化任务。

近日,谷歌对其搜索引擎的核心规则进行了重要更新,此次调整直指当前备受关注的AI搜索领域。具体而言,谷歌在其垃圾内容政策中新增了明确条款,正式将“操纵AI搜索结果”的行为列为违规操作,划定了新的质量红线。 根据权威行业媒体Search Engine Land的报道,本次谷歌算法更新的核心在于,将任何企

硅谷的科技巨头们或许曾以为,自己已经远离了AI数据中心带来的电力压力——毕竟,高昂的地价和电费早就把大型数据中心项目“赶”到了别处。但现实总是出人意料,这场能源危机的涟漪,正悄然涌向他们心爱的度假后院。 没错,说的就是太浩湖。这个湾区精英们钟爱的避世天堂,如今正站在一场电力风暴的边缘。距离它必须找到

这项由高通AI研究院(Qualcomm AI Research)主导的创新研究于2026年5月正式发布,论文预印本编号为arXiv:2605 07721。 研究背景:当AI越想越费内存,我们该怎么办 设想一下,手机导航应用会在出发前规划好整条路线,而一位真正智慧的向导则会边走边思考,遇到路障时灵活应