AI股票分析工具:8小时研究压缩至2分半钟
当大家还在争论哪个聊天机器人更聪明时,真正拉开差距的,其实是它背后那套流程化的体系。
想想看,过去一家公司要完成深度分析,分析师得在彭博终端、Excel、EDGAR数据库和各类新闻网站之间来回切换,花上6到8个小时。这还没算上每年2.4万美元的彭博终端费用。最终,在诸多固定假设下,往往只能得出一个单一的“目标价”。
而现在,情况完全不同了。只需要输入一条指令,大约2分半钟,一份详尽的分析报告就能生成。数据来自免费的公开API,而且是实时更新的。每运行一次,边际成本几乎为零。结果也不再只是一个孤零零的数字,而是同时给出乐观、基准、悲观三种情景,并附带完整的压力测试。
促使我思考这一点的,是看到一位朋友花了一整天,只为更新一个DCF模型。那些本应充满判断力和洞察的分析工作,被大量机械、重复的劳动淹没了。
于是,我动手搭建了一套系统,目的就是把那些重复劳动从核心工作中剥离出去。
它运行在我的笔记本电脑上,却能把分析师原本需要数小时完成的工作,压缩到大约150秒内跑完。
下面就是实际使用它的过程。
为发现真实错配而生的市场扫描器
我打开开发环境,启动代码解释器,然后输入一条简单的命令。
python3 models/market_scanner.py --scan-all
90秒后,结果呈现在眼前:
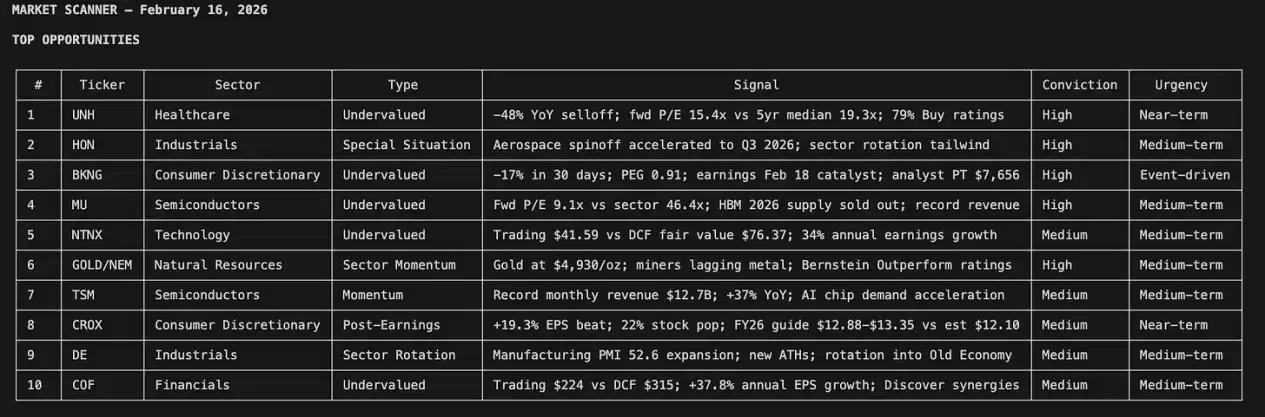
系统扫描了六个行业,精准标记出估值存在错位的机会,浮现出特殊情境投资的线索,并识别出内部人集中买入的信号。每一个被标记的机会,都会经过三道质量筛选:多来源数据交叉验证、可识别的催化因素,以及可量化的竞争优势。
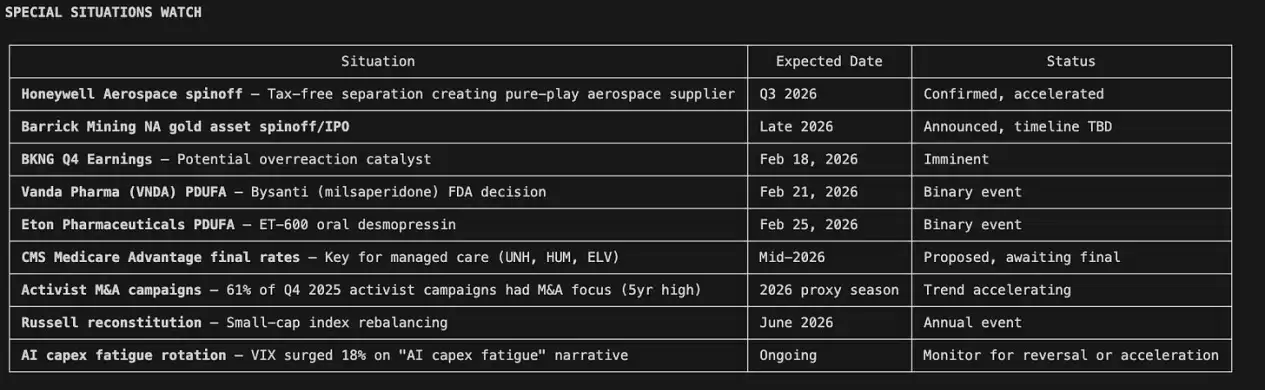
这个市场扫描器会主动搜索被低估和高估的股票,识别包括并购、分拆、激进投资者行动、指数再平衡在内的特殊情境机会,同时捕捉行业轮动的早期信号。然后,它会依据机会的确定性和紧迫性进行排序。底部的行业热力图,则清晰地揭示了资金真实的流向。
单就这一套工具而言,它已经能替代人们使用彭博终端时相当一部分的日常工作。

更重要的是,当某个标的引起我的注意时——比如一只半导体股票被标记为低估15%,同时还出现了内部人集中买入——我不再需要手动打开电子表格。只需输入第二条命令:
python3 models/research.py NVDA
几分钟后,一份完整的研究包就生成了,内容包括:
- 实时财务数据
- 包含敏感性分析的三情景DCF模型
- 来自多个来源的另类数据信号
- 基于历史数据训练的机器学习诊断结果
- 蒙特卡洛压力测试
- 因子暴露分析
- 仓位配置与风险上限建议
- 巴菲特/芒格式的定性检查
所有结果都会被自动保存到结构化的目录中,方便后续随时查看与复核。
构建这套系统的初衷
就在几个月前,我还在用传统方式做研究:从股票筛选器里拉取财务数据,手动更新Excel里的DCF模型,翻阅EDGAR文件,用Google搜索市场情绪,最后把所有内容拼贴到报告里。
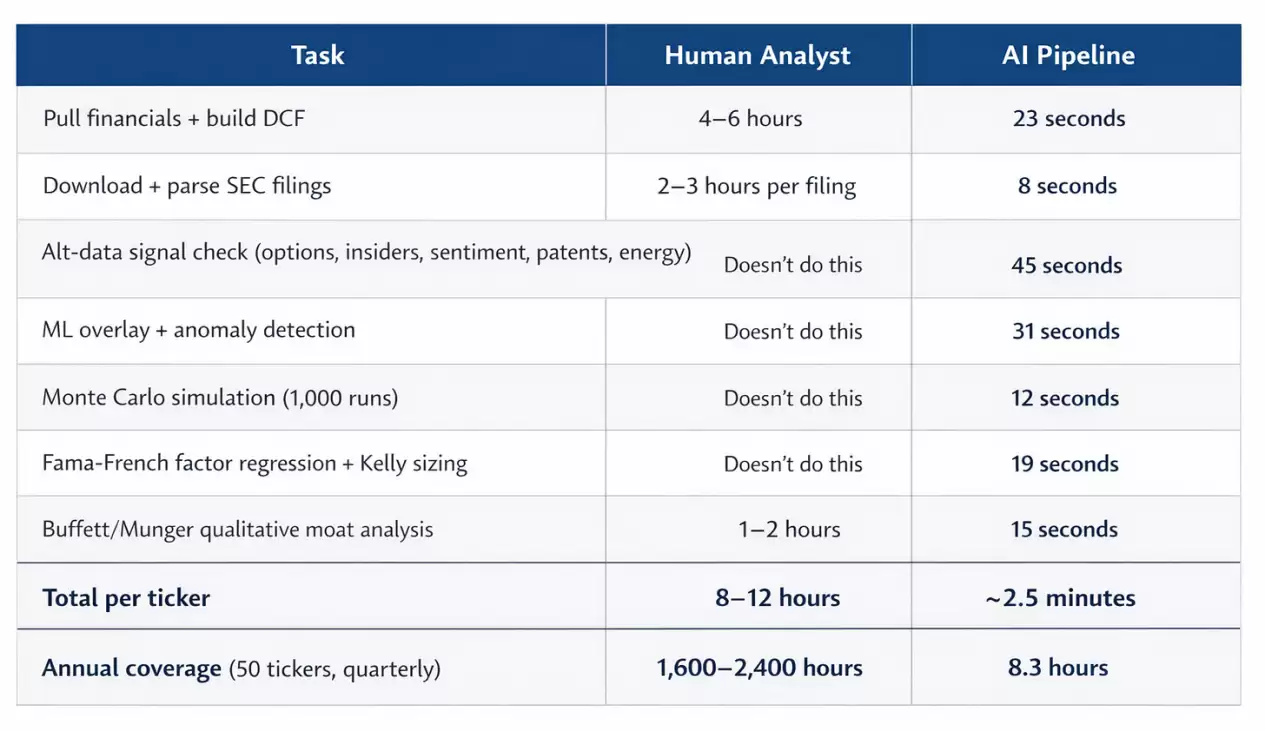
后来我专门计了一次时。认真做完一家公司的深度分析,大概要花八个小时。而且这还没有包括蒙特卡洛模拟、因子回归,也没有引入任何另类数据。
于是我开始思考:如果从全市场扫描,到单只股票的深度研究,整条流程都能端到端自动完成,中间不再需要人工介入,会发生什么?
经过几轮迭代、六个核心Python模块,以及大量代码重构之后,答案变得清晰起来。自动化版本不仅更快,而且比手工流程更完整、更严谨。这不是因为它更“聪明”,而是因为它永远不会漏掉任何一个预设的分析步骤。
这背后的经济账
算一笔经济账就明白了。一名股票研究分析师的年薪中位数大约是10.8万美元,而一个优秀分析师的实际综合成本(薪资、福利、办公空间等)通常达到20万到25万美元。
作为回报,你通常能得到的是:覆盖大约15到20只股票,每个季度更新一次模型,以及分析师有限的注意力和难以避免的认知盲区。
如果再算上每年2.4万美元的彭博终端费用,真实成本往往比大多数人愿意承认的更高。
而这套系统,只需要一台笔记本电脑就能运行,数据源是免费的公开API。它带来的真正杠杆,不在于某一次判断有多么神奇,而在于其无与伦比的稳定性和可规模化性。
五阶段研究流水线
除了全市场扫描,这套系统在单只股票尽调上的能力,是目前见过最完整的。它的核心是一条五阶段研究流水线,每个阶段的结果都会传递给下一阶段,由总控程序按顺序统一调度。
整体流程如下:

第一阶段:数据采集
系统会并行抓取以下多维数据:过去五年的完整财务报表及所有明细科目;基于原始数据计算的ROIC、自由现金流转换率及杠杆水平;根据行业动态自动识别的可比公司;从清洗后的SEC Form 4文件中提取的内部人交易记录;空头持仓相关指标;以及原始的10-K和10-Q文件。所有数据均按股票代码分类,整齐存储。
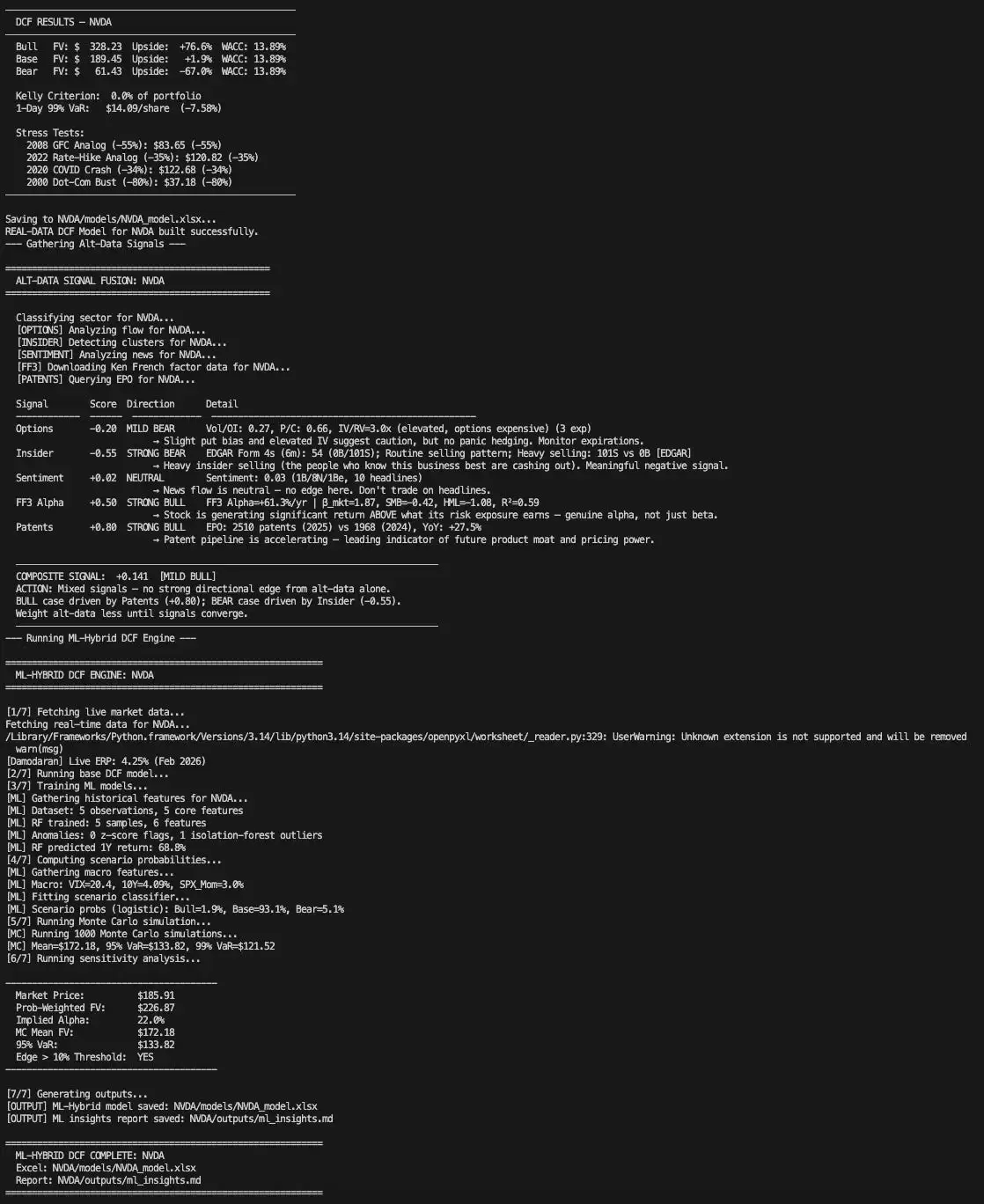
第二阶段:一个经得起推敲的DCF模型
大多数散户搭建的DCF模型,问题往往出在僵化的假设上:使用固定的增长率,忽略加权平均资本成本(WACC)对估值的关键影响,最终只输出一个“希望看到”的目标价。
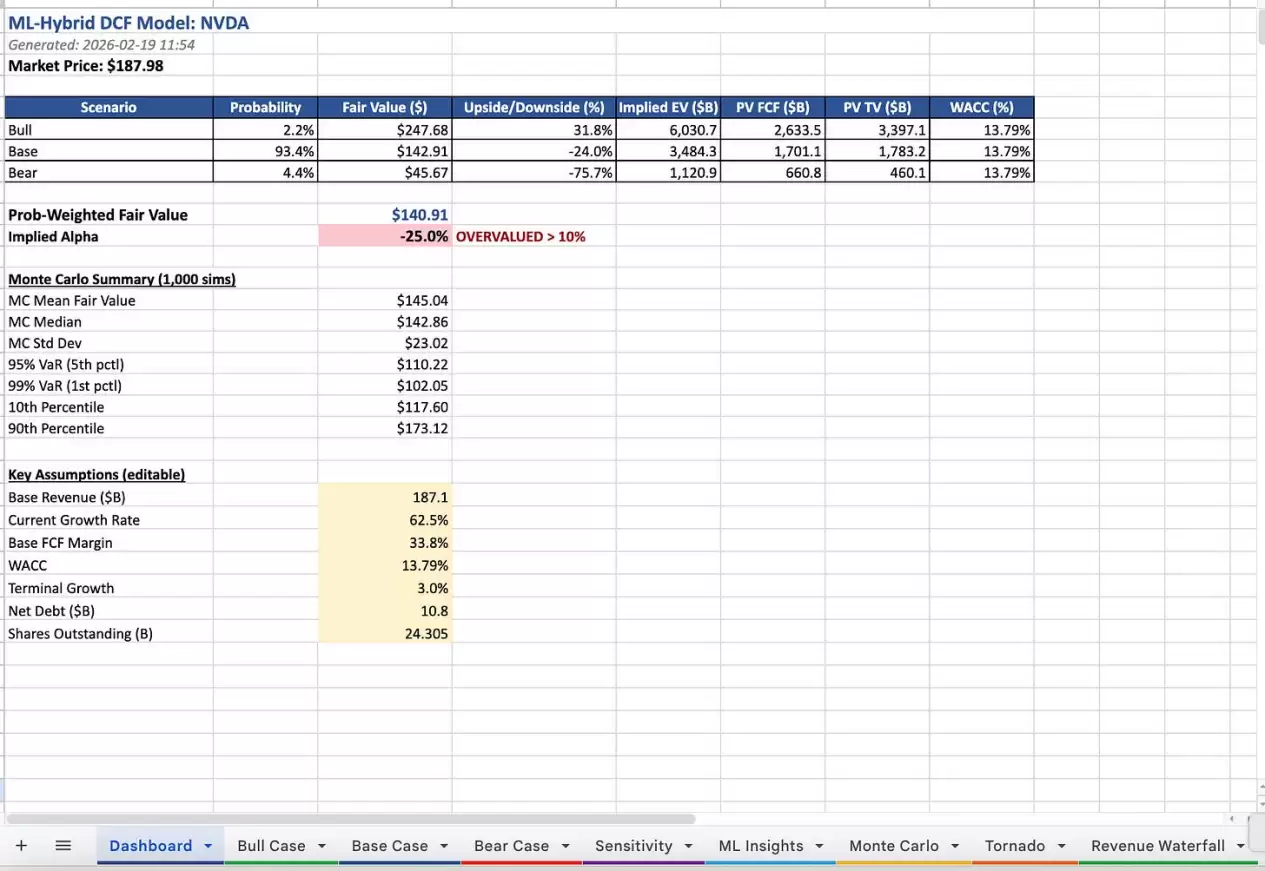
而这套DCF建模器截然不同。它摒弃静态假设,采用动态逻辑:使用实时的10年期美债收益率作为无风险利率输入WACC;采用股票真实的Beta值和有效税率;结合行业特征的增长率衰减曲线;同时运行乐观、基准、悲观三种情景;并输出完整的WACC与永续增长率敏感性矩阵。最终生成的是一份可直接用于投资决策报告的Excel模型。
关键区别在于数据的实时性。它不是写死一个利率,而是动态获取:
tnx = yf.Ticker('^TNX')
rf = tnx.history(period='1d')['Close'].iloc[-1] / 100
其中,`tnx.history` 对应的是CBOE的10年期美国国债利率实时数据。
结合行业特征的增长率衰减逻辑至关重要,也是多数人容易犯错的地方。一家收入增速40%的公司,不可能在未来十年一直保持40%的增长;但它的增速也不应瞬间暴跌至3%。系统采用了更合理的衰减策略:对于增速超过30%的高速增长公司,假设竞争会较快侵蚀优势,增长率较快回落至约4%的永续水平;对于增速在10%-30%的中等增速公司,采用标准收敛方式,逐步回落至约3%;对于增速低于10%的低速增长公司,只做小幅衰减,因其已接近成熟阶段,最终趋近于约2.5%的永续增长率。这有效避免了DCF中两个常见错误:对高增长公司过度乐观,或让中等增速公司过早跌至永续水平。
第三阶段:另类数据信号融合
信号融合引擎将五类另类数据源整合为一个综合Alpha分数。
1. 期权流向分析:不止看成交量高低。系统会分析前三个期权到期日,识别异常交易(成交量达未平仓量5倍以上通常预示信息押注)、方向偏好(Put/Call比率低于0.7偏多,高于1.3偏空)以及不确定性定价(隐含波动率高则降低结论确定性)。这是一种类似机构期权团队的多到期日分析思路。
2. 内部人情报:分为两层。首先直接查询SEC EDGAR,统计过去6个月的Form 4文件数量;然后与市场数据交叉核对交易方向和金额。打分并非一刀切:对于超大市值公司,大量Form 4文件若无买入,可能只是常规薪酬兑现卖出,系统给出轻微负面判断;但对于中型公司,若出现3次以上、金额超100万美元的内部人集中买入,则视为高置信度正面信号。
3. 基于NLP的情绪分析:抓取最近15条新闻标题,通过自然语言处理模型进行情感打分。系统不会简单平均分数,而是加入置信度权重:将原始分数削弱20%以避免噪声干扰;若看多与看空标题比例达2:1或更高,则加入共识加分。最终情绪分数反映的是相对真实的市场叙事。
4. 专利速度:针对科技和医药公司,调用欧洲专利局(EPO)API,统计专利申请量同比变化。若公司拥有500件以上专利且申请量同比增长超20%,通常意味着较强的创新护城河。若无EPO API,则使用研发支出增长数据作为替代。
5. 能源暴露:查询EIA.gov的API,获取天然气和电力价格趋势。能源成本上升对数据中心、制造业等能源密集型公司构成逆风,下降则形成顺风。
综合分数:每类信号有权重(期权20%,内部人20%,情绪15%,专利30%,能源15%)。加权后的综合分数揭示了这些非公开、非显而易见的数据是在支持还是矛盾于基本面叙事。分数高于+0.4为强烈看多信号,低于-0.4则为看空信号。这正是系统提供差异化优势的一层。
第四阶段:机器学习混合引擎
这一阶段是系统开始捕捉那些人工分析容易遗漏的微妙模式。它在基本面分析之上,叠加了一层机器学习。
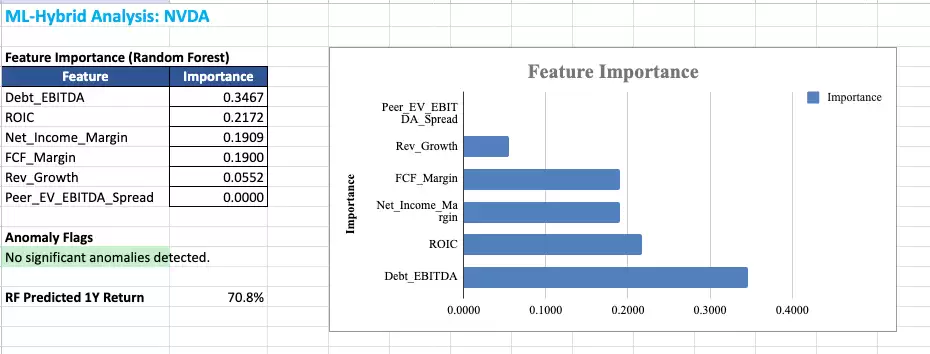
随机森林模型:作为一个决策引擎,它用过去10年的季度财务数据训练,关注净利率、自由现金流率、收入增长、债务/EBITDA、ROIC及相对估值六个关键因素,学习它们历史上如何预测公司回报,并指出当前哪些因素最为重要。
孤立森林 + Z分数异常检测:用于标记异常数据点,如收入增长出现超过2个标准差的拐点、利润率跳升或ROIC显著变化。这些季度往往意味着基本面变化,而大多数分析师可能错过。
逻辑回归情景概率:系统不依赖主观判断给出“乐观情景30%概率”。它会用过去5年的月度VIX指数、10年期美债收益率和标普500动量数据训练逻辑分类器,学习何种宏观环境对应何种结果,输出经过校准的概率。
蒙特卡洛模拟:在合理输入范围内对DCF模型进行1000次压力测试。每次模拟都会扰动关键变量(增长率±10%,WACC±1%,自由现金流率±2.5%,永续增长率±0.5%),最终输出公允价值的概率分布及5%和1%分位上的在险价值(VaR)。
Alpha计算:将三种情景下的概率加权公允价值与当前市价比较,计算隐含Alpha。简单说,就是回答:从数学结果看,这只股票还有多少上行或下行空间?隐含Alpha超过10%会被标记为“优势超过10%门槛”,低于-10%则标记为“高估超过10%”。
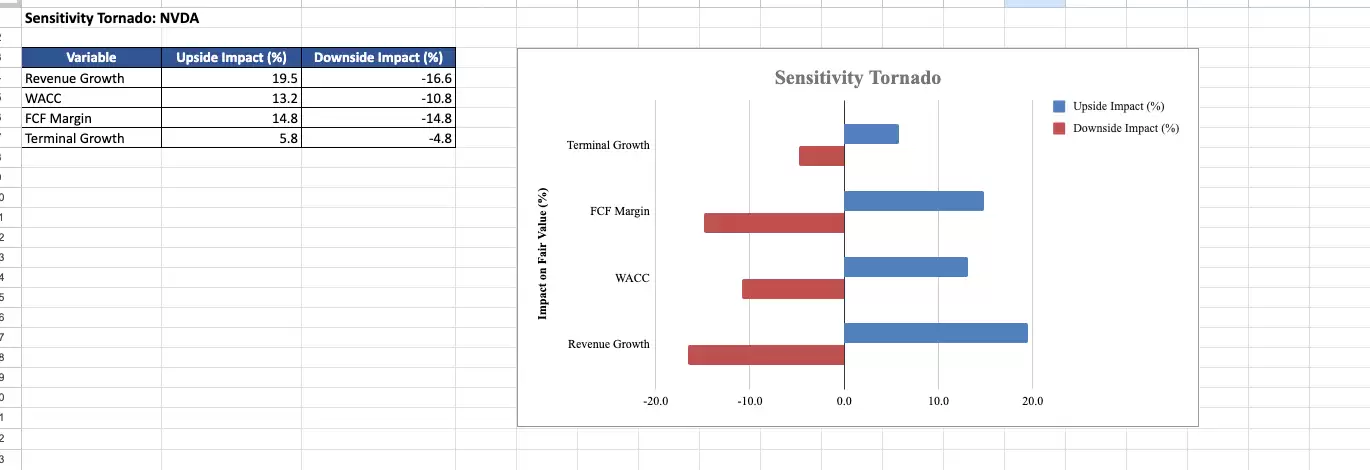
最终输出是一份完整的Excel工作簿,包含仪表盘、三种情景分析、敏感性分析、机器学习洞察页面(带特征重要性柱状图)、蒙特卡洛结果直方图以及敏感性龙卷风图。

第五阶段:多智能体验证
真实基金的投资流程通常包含多方验证:分析师提出观点,风险经理、投资组合经理和一个专门唱反调的角色会共同审视,试图推翻它。好的想法经得起拷问,差的想法被淘汰。这套系统用三个专用智能体模拟这一过程。
智能体1:风险:运用凯利公式根据概率加权空间计算最优仓位(上限5%);计算99%历史在险价值(VaR);通过Fama-French三因子模型回归分析识别隐藏的因子暴露;并进行压力测试,套用历史及假设冲击情景(如2008年式下跌55%,2024年加息式下跌66%,催化因素失效下跌30%)。
智能体2:基准比较:基于60日动量、RSI(14)及相对行业ETF的强度构建Alpha信号,用过去3年样本外数据回测“分数高于0.6时买入并持有90天”的策略(计入10个基点交易成本),并比较该策略与买入持有、行业ETF的总回报、夏普比率和Alpha。
智能体3:优势衰减:根据信号自相关函数拟合指数衰减曲线,计算优势半衰期(以交易日计);模拟四种市场状态切换(加息50基点、衰退概率升至30%、VIX飙升、成长转价值风格)下的韧性;结合半衰期、不同市场状态下的韧性及历史类似情景持续性,计算“优势可持续性分数”。
三个智能体随后展开“辩论”:若其中2个或3个给出“DEPLOY”信号,则放行该仓位并给出具体配置与止损建议;若2个或3个给出“NO-GO”,则否决该投资想法;若结论为“CONDITIONAL”(有条件通过),则标记出来交由人类最终复核。
巴菲特/芒格加分项:没有定性判断的量化分析是危险的。为此加入了“护城河通道”模块,运行四个支柱分析:
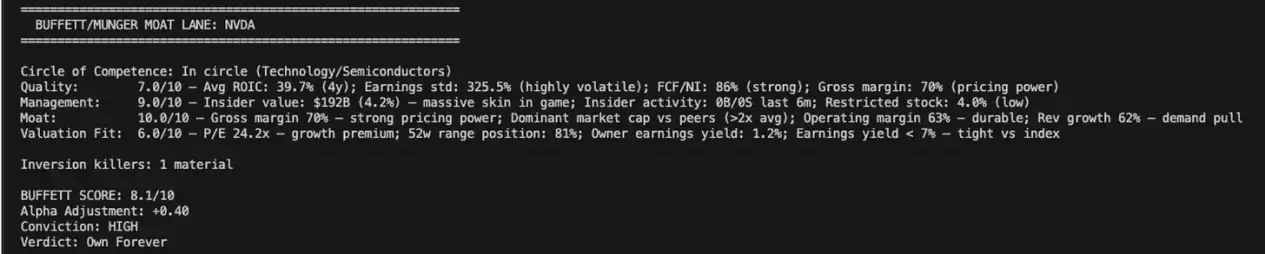
随后,系统执行“芒格式反向思考”:评估三个“杀手因素”各自的发生概率和影响程度。只要任何一个因素的发生概率超过30%且影响程度超过30%,巴菲特分数就会被强制封顶在6.0/10,没有例外。
最后,系统应用五个心智模型:能力圈、安全边际(经PEG调整)、多因素叠加效应、激励导致的偏见以及市场先生。
最终输出包括:一个满分10分的巴菲特分数、一个正向或负向的Alpha调整值、一个置信度等级(HIGH, MODERATE, LOW, A VOID)以及最终判断(长期持有、加入观察、放弃、规避)。
你会得到什么
当你运行 python3 models/research.py NVDA 后,你的目录中会出现一整套完整的研究材料。
这就是一份适用于任何上市公司的完整研究包。整个过程,不到5分钟。不妨先感受一下这件事带来的效率变革。
自己动手:30分钟体验版
你不需要编写一行代码,也能获得类似系统中80%的价值。下面这个方法,利用现有AI工具,通过自然语言交互即可实现。
第一步:搭建你的AI研究工作区
打开Claude、ChatGPT或Gemini。接下来,它将作为你的研究副驾驶。全程只需用自然语言提问。
第二步:拉取实时财务数据
将以下提示词粘贴到你的AI工具中:
拉取NVDA最新的财务数据。我需要:当前股价、远期市盈率、收入增长率、自由现金流率、ROIC,以及Debt/EBITDA。其中,ROIC请按EBIT × (1 - 税率) ÷ 投入资本计算。同时,请列出同行业最接近的5家可比公司,并给出它们当前的P/E和EV/EBITDA,用于对比。
30秒后,你将得到一张可比公司估值表。这在过去可能需要分析师在Excel里花费2小时整理。
第三步:快速运行一个DCF模型
继续输入:
现在为NVDA做一个三情景DCF。使用当前10年期美国国债收益率作为无风险利率,使用这只股票真实的beta,并采用4.2%的股权风险溢价。预测未来10年的自由现金流,并加入增长率衰减逻辑:高速增长公司快速衰减,成熟公司缓慢衰减。请给出乐观、基准、悲观三种情景下的公允价值,并提供一张5×5的敏感性分析表,展示WACC与永续增长率变化下的估值结果。
这样你得到的DCF,将不再是MBA教材里那种使用固定“4% WACC”的静态模型,而是一个基于实时市场数据、带有合理动态假设的估值模型。
第四步:检查另类数据信号
这一步能让你超越95%的散户投资者:
请检查NVDA的另类数据信号:期权流向(Put/Call比率偏多还是偏空?有无异常成交量?);内部人交易(过去6个月是净买入还是净卖出?对应金额?);新闻情绪(总结最近10条新闻标题,给出整体偏多、中性或偏空的判断);最近是否有值得注意的专利活动?
第五步:形成最终判断
汇总以上所有信息:
基于以上所有信息,包括基本面、DCF公允价值区间、可比公司估值对比,以及另类数据信号,请给出:概率加权后的公允价值;相对于当前价格的隐含上行或下行空间;可能推翻这条投资逻辑的前三大风险;置信度等级:HIGH / MODERATE / LOW / A VOID。
只需这四段提示词,耗时约30分钟。现在,对于一只股票,你掌握的信号深度已经超过大多数散户投资者一周的整理成果。如果在周日晚上对10只股票运行此流程,你将得到一份接近机构质量的观察名单。
那么,这与完整系统的区别何在?完整系统会自动完成上述所有步骤,并额外加入蒙特卡洛模拟、机器学习异常检测、多智能体验证辩论,以及巴菲特/芒格式的定性分析层。而且它耗时不是30分钟,而是2分半钟。
但这个手动版本,已经是一个强有力的起点。手动提示AI与运行全自动系统之间的差别,本质在于:前者需要你逐步提问和整理,后者则将数百小时的开发成果压缩为一条命令,并在3分钟内执行完毕。
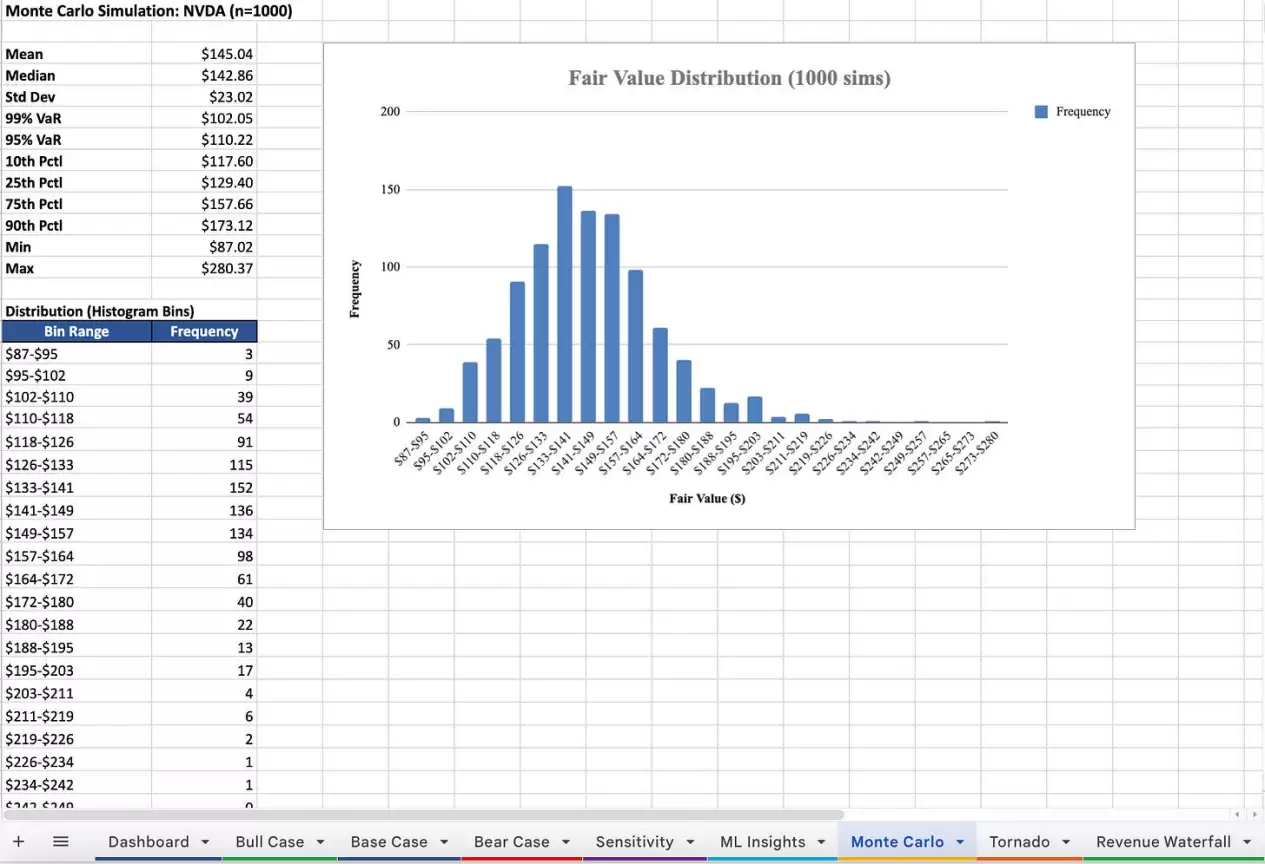
至此,你已经了解了这套系统的能力及其有效性背后的逻辑。
完整的系统,即“Alpha Terminal”,正是将上述所有流程封装起来的全自动解决方案。只需一条命令,它便会执行全部流程。系统内置错误处理机制,在数据缺失时会优雅降级,能够动态发现可比公司,并在整个流程中应用结合行业特征的判断逻辑。
相关攻略

数据质量是决定AI模型成败的核心要素,它直接关系到模型输出的精准度与可靠性。那么,如何系统性地评估数据,并确保其真正“适用”于AI训练呢?这需要一套严谨的评估框架与保障策略。 一、数据质量评估的核心维度与方法 评估数据质量不能仅凭主观判断,必须从多个关键维度进行客观“体检”,每个维度都有对应的量化方

AI浪潮正重塑传统菜市场。互联网巨头转向智能定价、无人仓储与配送系统,以更低成本、更高效率改造生鲜零售。AI的固定投入与趋零边际成本有望大幅压缩履约费用。尽管菜市场人情味短期难替代,但随着年轻消费习惯改变与AI终端普及,传统模式面临深刻挑战。

初次接触CapybaraAI的用户,常常会下意识地寻找搜索框,却发现界面中并没有传统意义上的“快捷搜索”按钮。这并非设计疏漏,而是源于其根本定位的差异。 您的观察完全正确。CapybaraAI本身并未集成类似浏览器的“一键搜索”功能。它并非一个输入关键词、返回网页列表的搜索引擎。其核心定位是一个强大

在软件开发的代码质量保障体系中,单元测试是不可或缺的核心环节。它不仅是验证代码逻辑正确性的首要防线,更是提升软件可维护性、保障长期开发效率的关键实践。然而,编写与维护高质量的单元测试用例,往往需要开发者投入大量时间与精力。那么,是否存在一种方法,能让单元测试工作变得更高效、更智能? 答案是肯定的。借

如果你的 Hermes Agent 已经部署完成,但在处理基于个人文档的提问时频繁出现“答非所问”或“无法回答”的情况,问题根源很可能在于知识库的导入环节——AI 尚未真正“理解”你的专属数据。无需担忧,这类似于为新员工配备了电脑却未提供工作手册,只需补充相应资料即可。以下五种高效方法,总有一种能帮
热门专题







热门推荐

广东无人机适飞空域扩大16%至10 24万平方公里,覆盖全省57%陆地面积,滨海、郊野、工业园区及非核心城区公园等区域开放,深圳市区新增连片适飞区。飞行需通过民航局UOM平台提前申请,严禁“黑飞”,违者将受处罚。平台已升级,实现全国规则统一与分钟级空域更新,支持低空物流与巡检等应用。

杭州Costco门店因iPhone17系列手机引发抢购热潮,数百人排队致迅速断货。抢购源于官方降价与地方补贴叠加:iPhone17Pro全系直降千元,同时当地青年消费补贴可再减10%,最高省千元。双重优惠下,256GB版iPhone17Pro到手价低至7172元,较电商平台便宜近千元,吸引本地及周边消费者。目前门店仍处缺货状态,补货时间未定。

5月17日晚,长征八号运载火箭在海南商业航天发射场点火升空,成功将千帆星座第九批组网卫星送入预定轨道。此次发射是该发射场启用以来的第15次成功发射,也是今年第5次发射,体现了我国商业航天发射能力的日益成熟和常态化运营的稳步推进。

七彩虹新款iGameM15 M16Origo2026款游戏本已发售,起售价11499元。M15为15 3英寸黑色机身,配备2 5K300Hz屏,最高可选Ultra9处理器与RTX5070显卡。M16为16英寸白色款,屏幕规格相同,处理器性能更强,电池容量更大。两款均提供多种配置,享受国家补贴后价格更具竞争力,面向中高端游戏玩家与创作者。

联想在北美市场推出新款ThinkPadT14Gen7商务笔记本,支持用户自行更换LPCAMM2内存。该机型提供多款英特尔酷睿Ultra处理器选项,内存可选16GB至64GB,电池与屏幕亦有多种配置,其中顶配版搭载OLED屏幕。产品起售价为1618美元,高配版本价格超过3700美元,主要面向商用及专业办公市场,兼顾性能、可升级性与不同预算需求。