在衡量企业级智能体是否具备持续服务与协同工作能力时,“长期记忆”功能常被视为一项关键评估指标。然而,我们必须明确一个核心认知:智能体的“记忆”与人类的记忆,在本质原理和应用边界上存在根本性差异。清晰理解这些区别,是企业安全、高效部署与应用该技术,并有效规避潜在风险的前提。
一、长期记忆:驱动智能体持续进化的核心引擎
智能体的长期记忆,本质上是指其能够突破单次会话的局限,持续存储并调用历史交互信息的能力。这绝非简单的聊天记录回溯,而是意味着智能体可以基于过往对话进行深度“学习”与“推理”,从而更精准地把握上下文语境,理解用户的个性化需求与意图。你会发现,一个具备优秀记忆能力的智能体,在多次交互后,其服务会变得更加贴心与高效。
在实际业务场景中,这项能力的价值尤为凸显。它使得智能体能够对信息与数据进行跨会话的关联分析、整合处理与智能筛选,从而保障项目执行的连贯性与决策的精准度。例如,一个搭载了长期记忆功能的客户服务智能体,若能记住用户上次咨询的问题详情及解决进展,便能实现服务的无缝衔接,用户无需重复描述,体验流畅度与问题解决效率均获得显著提升。
二、智能体记忆的明确边界:关键数据的筛选原则
技术可以持续迭代,但有一条基本原则不容逾越:即对用户数据与内容隐私的严格保护。这构成了智能体长期记忆不可动摇的安全边界。具体而言,以下三类信息通常不会被纳入长期记忆库:
第一,瞬时性与低价值的交互碎片。 例如对话中的问候语、感叹词等。存储此类信息不仅无助于提升对话质量,其参考价值极低,反而会徒增数据冗余与隐私泄露风险,因此必须在入口端进行过滤。
第二,完整的原始文档与多媒体文件。 面对一份长篇报告或视频,智能体通常不会直接存储原始文件。更优化的做法是,运用自然语言处理技术,提取其中的核心摘要、关键结论或结构化数据。这样做的目的很明确:在确保核心知识不丢失的前提下,极大提升后续信息检索的效率,并有效控制存储成本。
第三,系统底层的运行日志与实时状态数据。 智能体在运行过程中会产生大量高动态、临时性的底层日志与状态信息,这些信息通常与核心业务逻辑关联度不高,因此很少被长期记忆系统所收录。

三、智能体记忆的构建流程:从信息到知识的转化
智能体的记忆形成并非被动接收,其背后是一套主动的信息过滤与知识加工机制。这套机制如同一位严谨的“信息质检官”,确保只有安全、合规且具有长期价值的信息才能进入记忆库,从而从源头保障系统的安全性与效能。
整个流程可概括为三个核心环节:
第一步:输入过滤与清洗。 信息在输入阶段即接受初步筛查,系统会快速识别并过滤掉明显无关、敏感或无效的内容,为后续处理奠定干净的数据基础。
第二步:智能摘要与关键信息提取。 对于有价值但内容冗长的对话或文档,智能体会运用先进的语义理解技术,将其浓缩成精炼的摘要,或提取出关键实体、标签与关系。这类似于我们阅读时做读书笔记,记录的是核心思想与脉络,而非全文照搬。
第三步:分级存储与优化管理。 系统会根据信息的重要性、关联性、访问频率等多维度因素,制定差异化的存储策略:例如,打上多维标签以便于检索,设定不同的保存期限,或进行冷热数据分层存储。这种精细化的管理,确保了记忆系统既高效灵活,又经济可控。
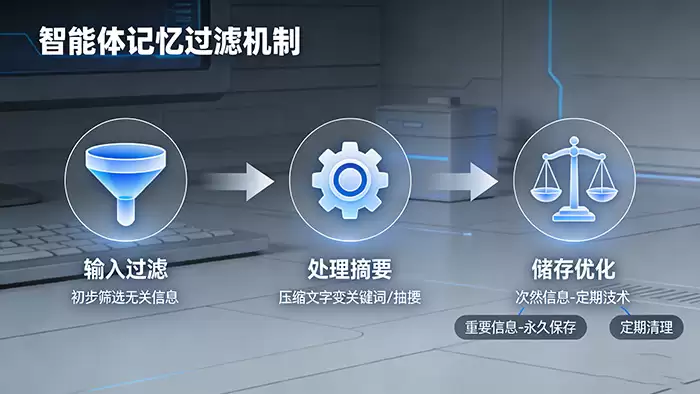
正是通过这套层层递进、严格把关的机制,智能体才得以变得既“聪慧敏捷”,又“安全可靠”。
四、潜在风险与系统性应对策略
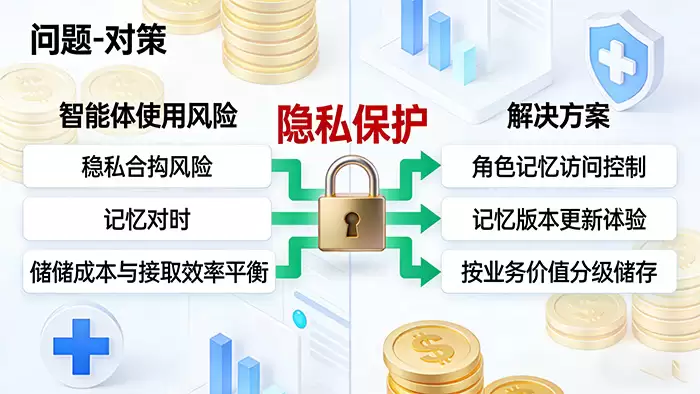
引入智能体长期记忆能力,在带来显著效益的同时,也伴随着必须警惕的潜在风险。企业需要未雨绸缪,建立相应的应对机制。
首要风险集中于隐私安全与合规性。 这在金融、医疗、法律等强监管领域尤为关键。一旦敏感数据被不当记忆或泄露,将引发严重后果。有效的应对策略是建立基于角色与内容的动态访问控制机制。智能体应能自动识别对话中的敏感信息(如个人身份信息、财务数据、健康档案),并依据预设的合规规则,决定是否存储、或如何进行脱敏、加密后存储,从技术层面根除泄露隐患。
其次是记忆信息的时效性与准确性问题。 智能体所记忆的“知识”可能随着业务规则、产品信息的更新而变得过时,直接调用可能导致输出错误信息。这要求配套建立记忆内容的版本管理与定期审计更新机制。如同维护企业知识库一样,需要对智能体的记忆进行周期性的校验、修订与更新,确保其与最新的业务现实保持同步。
最后是成本控制与系统效能的平衡挑战。 若不加区分地存储所有交互细节,不仅会带来高昂的存储与计算成本,海量数据还会导致检索速度下降,影响响应效率。解决之道在于实施与业务价值挂钩的差异化记忆策略。企业可根据数据的重要程度设计记忆规则:例如,对核心客户、高价值项目的交互,保存更完整、更长期的记忆;对于常规性、事务性咨询,则仅保留关键结论或模式摘要。从而实现资源的最优配置与投资回报最大化。
五、未来趋势:迈向更精准、更安全、更灵活的记忆系统
展望未来,智能体长期记忆技术将朝着更精准、更安全、更智能的方向持续演进。首先,上下文重要性评估将更加精细化,模型能更准确地区分核心信息与背景噪音,提升记忆的“含金量”。其次,隐私增强技术将深度内嵌于记忆生命周期,实现“隐私计算原生”,在保障数据绝对安全的前提下释放其价值。最后,记忆本身可能呈现模块化、可编排的发展趋势,如同乐高积木,可根据不同的任务场景灵活组合与调用特定的记忆模块,极大增强智能体的适应性与解决问题的能力。

常见问题(FAQ)
Q1:长期记忆容量有限,企业最该让智能体记住什么?
A1: 企业应依据业务价值设定记忆优先级:首要的是高频访问的核心业务知识(如产品规格、服务条款、合规政策);其次是用户的个性化画像与历史行为模式;再次是经过验证的成功案例与决策逻辑;最后是跨会话的项目上下文与协作状态。以智能客服场景为例,系统应优先记忆常见问题解决方案(FAQ)及VIP客户的服务偏好,而非存储每次对话的客套寒暄。
Q2:如果智能体遗忘了重要信息,还有办法补救吗?
A2: 是的,通常可通过管理后台进行干预与补救。主要方法包括:1. 手动更新与注入知识:管理员直接向智能体关联的知识图谱或数据库中补充、修正关键信息;2. 定向强化训练:通过投喂新的对话样本或专项数据集,对特定记忆模块进行再训练与优化;3. 优化检索与索引策略:调整向量化模型参数或检索算法,提升目标信息在记忆召回中的权重与优先级。当然,这一切的前提是系统架构本身具备良好的可管理性与可干预接口。




