具身智能仿真框架:高吞吐并行与高保真渲染驱动规模化训练
在具身人工智能(Embodied AI)快速发展的今天,视觉感知正成为机器人理解与交互物理世界的核心入口。作为信息最丰富、最符合人类直觉的交互模态,视觉是解锁通用机器人智能、实现从虚拟仿真到真实物理世界无缝迁移的关键技术路径。
然而,构建以视觉为中心的机器人仿真训练平台面临巨大挑战:追求高保真视觉渲染往往带来难以承受的计算与内存开销;依赖人工建模则效率低下、成本高昂;而现有平台的兼容性与性能局限,更是束缚了技术迭代与创新的步伐。
为系统性解决这些瓶颈问题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,正式发布了GS-Playground——一个面向视觉中心机器人学习的新一代通用多模态仿真框架。
GS-Playground首次实现了高吞吐量并行物理仿真与高保真视觉渲染的深度融合。它在保证物理仿真精度与稳定性的同时,为大规模视觉驱动策略的训练与仿真到现实(Sim2Real)迁移,提供了前所未有的高效环境与基础设施支持。该研究成果已被机器人领域国际顶级会议RSS 2026录用。

Figure 1. GS-Playground Overview
通用全场景原生兼容:打造统一的具身智能仿真训练底座
GS-Playground定位于通用型全场景仿真平台。其核心搭载了自研的跨平台并行物理引擎,原生支持CPU/GPU双后端,并可在Windows、Linux、macOS全操作系统上流畅运行。这意味着,无论是四足机器人、全尺寸人形机器人,还是多自由度工业机械臂,主流机器人形态均可实现开箱即用的原生适配,无需繁琐的二次开发。
平台全面覆盖机器人运动控制、自主导航、高精度灵巧操作三大核心任务场景。其API接口全面兼容行业标准的MuJoCo MJCF格式,使得现有仿真项目能够实现零成本、快速迁移,极大降低了研究者的学习与适配门槛。
自研高性能并行物理引擎:为接触密集型任务提供稳定动力学
对于视觉驱动的机器人学习而言,“看得清”是基础,“动得稳”才是关键。仿真系统能否在复杂的接触、摩擦、碰撞等密集交互中,提供稳定、可信的物理反馈,直接决定了训练策略能否成功迁移至真实世界。
针对这一核心需求,GS-Playground从底层自研了一套高性能并行物理引擎。它采用广义坐标下的速度-冲量动力学公式,将接触与摩擦统一建模为混合互补问题(MCP),并通过投影高斯-赛德尔(PGS)求解器进行稳定求解。相比依赖软接触正则化的传统方法,该设计更强调静摩擦保持、高刚度约束与大时间步稳定性,特别适用于足式运动、机械臂抓取等涉及密集接触的高动态任务。
为支撑大规模并行训练,团队创新性地引入了约束岛并行化与接触流形热启动机制。前者将相互独立的刚体交互系统拆分为多个“约束岛”并行求解;后者则利用上一帧已收敛的接触冲量作为当前帧的迭代初值,从而将稳定堆叠场景中的PGS迭代次数从50次以上大幅降低至10次以内,显著提升了复杂接触场景的求解效率。
实验数据充分验证了自研物理引擎的稳定性与性能优势。在Franka Panda机械臂的动态抓取摇晃测试中,GS-Playground的CPU后端在0.002s与0.01s两种时间步下,均实现了90/90的完整保持成功率,表现显著优于MuJoCo、IsaacSim与Genesis等主流方案。在包含27自由度人形机器人的复杂多体交互基准测试中,当单环境扩展到50个机器人并行时,GS-Playground的CPU后端仍能保持1015 FPS的稳定吞吐,相比MuJoCo实现了32倍加速,相比MjWarp提升约600倍。
自研内存高效Batch 3DGS渲染技术:打破保真与效率的“不可能三角”
如何同时渲染数千个高保真的3D高斯溅射(3DGS)场景,而不耗尽内存与算力,是视觉驱动机器人大规模训练的核心瓶颈。
团队首先为刚体仿真环境设计了专属的高效剪枝策略。该策略能将场景中的高斯点数量减少90%以上,同时峰值信噪比(PSNR)的下降幅度不足0.05——这种视觉差异几乎无法被视觉运动策略感知。从而在大幅降低显存占用的同时,近乎无损地保留了场景的视觉质量。
在此基础上,团队研发了面向批处理深度优化的批量3DGS渲染器,实现了多场景、大规模高斯渲染的并行处理。在单张NVIDIA RTX 4090 GPU上,该渲染器在640×480分辨率下可实现最高10000 FPS的突破性吞吐量,最多能同时渲染2048个场景。这不仅显著提升了单位算力的渲染效率,更能完美适配大批次强化学习的训练工作流,让大规模并行训练不再受限于渲染性能。
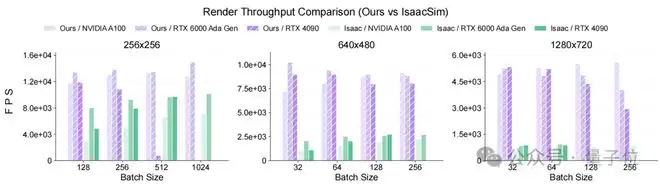
Figure 2. Rendering throughput comparison between GS-Playground and Isaac Sim’s ray-tracing renderer across varying resolutions
此外,团队提出的刚性连杆高斯运动学(RLGK)机制,将3D高斯簇与物理引擎中的对应刚体进行精准绑定,确保了视觉表征与物理对象的位姿能够实时同步更新,实现了零额外开销的状态同步。即便在机器人快速运动、频繁接触的动态场景中,渲染器也能实现无伪影的画面输出,从根源上解决了动态场景的渲染时间一致性与视觉伪影问题,保障了训练数据的稳定性与可靠性。
自动化“Sim-Ready” Real2Sim工作流:降低数字孪生构建门槛
传统仿真场景的构建,始终是机器人研发中效率低、成本高的环节。人工建模难以完全复刻真实环境的视觉细节与物理特性,感知与物理的双重鸿沟成为制约Sim2Real迁移的核心障碍。
针对这一痛点,GS-Playground设计了一套全自动化的“图像到物理”Real2Sim工作流。仅需输入单张RGB图像,即可在数分钟内完成“仿真就绪(Sim-Ready)”数字资产的全流程创建,实现从真实场景到高保真数字孪生的快速转换,同时保证视觉真实感与物理一致性。
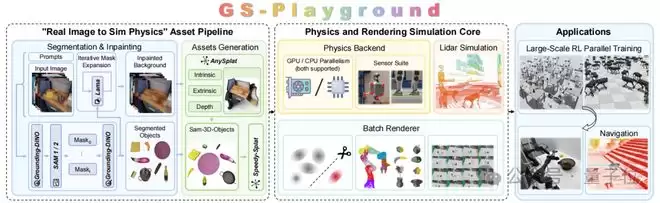
Figure 3. GS-Playground System Architecture
(左:自动化图像到物理仿真管线,通过目标分割、背景补绘、三维高斯溅射/网格重建,从RGB输入构建可直接用于仿真的资源。中:物理与渲染仿真核心,包含CPU/GPU物理后端、集成传感器与激光雷达仿真,以及经过剪枝优化与刚性连杆运动学适配的批量三维高斯溅射渲染。右:下游应用,包括操作任务、导航任务以及大规模并行强化学习。)
基于这套成熟的自动化工作流,团队构建了Bridge-GS数据集。该数据集在Bridge-v2的基础上,补充了场景与物体级的3DGS表征、物体级网格模型、6D位姿数据与校准后的相机参数,为行业提供了标准化的高质量仿真数据集。同时,团队在InteriorGS数据集上完成了完整的泛化性验证,证明了该管线对不同室内场景的强适配能力。
全链路端到端验证:实现零微调的无缝仿真到真实迁移
基于上述三大核心技术的深度协同,GS-Playground构建了从真实场景重建、大规模并行训练到真机部署的全链路端到端闭环,真正实现了“重建即训练、训练即部署”的研发流程革新。
在策略训练与真机迁移方面,平台可稳定支持数千个并行环境同时运行,为四足、人形、机械臂等全品类机器人提供大规模视觉强化学习训练支撑。关键在于,仅在GS-Playground仿真环境中完成训练的视觉驱动策略,无需任何额外微调,就能直接部署到真实机器人上稳定运行:四足和人形机器人的运动策略均可实现零样本(zero-shot)真机部署;视觉导航任务同样实现了零样本的真机直接部署;机械臂抓取任务在零微调前提下,真实场景成功率达到了90%。

Figure 4. Real-world deployment of policies trained in GS-Playground
这一系列实验结果,充分证明了平台实现了真正无壁垒的仿真到真实迁移,验证了其在弥合具身智能感知与物理跨域鸿沟上的核心价值与实用性。
开源赋能:与全球社区共同推动具身智能创新
GS-Playground作为行业内首个实现高吞吐量并行物理仿真与高保真批量3DGS渲染深度融合的全栈仿真框架,从根源上突破了长期制约视觉驱动机器人学习的算力、显存与资产生成三大瓶颈。其自动化Real2Sim工作流,大幅降低了高保真仿真环境的构建成本;全维度的实验验证也表明,平台在足式运动、自主导航、机器人操作等主流任务中,能够同时弥合物理与感知层面的仿真到现实鸿沟,实现真正的零微调真机部署。
未来,GS-Playground将持续迭代优化,拓展能力边界。清华大学智能产业研究院DISCOVER Lab始终致力于推动具身智能领域的前沿研究与技术创新。我们将正式开源GS-Playground的全栈框架,旨在为全球研究社区与产业界提供一套高性能、易使用、高泛化性的核心基础设施,助力大规模端到端视觉驱动机器人策略学习的快速发展与广泛落地。
项目主页:
https://gsplayground.github.io
论文链接:
https://arxiv.org/abs/2604.25459
仓库链接:
https://github.com/discoverse-dev/gs_playground
相关攻略

“我们的谐波减速器订单已经排到2027年了。两年前的交货周期还能稳定在4周以内,但从2025年4月开始,直接延长到了8周以上。”在近期的一场行业峰会上,绿的谐波相关负责人向外界透露,公司产品供不应求,产线满负荷运转。 这个深植于机器人关节的核心精密部件,正乘着具身智能产业的东风,迎来前所未有的需求井

通用飞行智能正处爆发前夜,智能飞行机器人是具身智能重要分支。其发展面临数据稀缺、场景复杂、零容错及机载算力限制等挑战。当前研究聚焦环境感知、本体规控、端侧决策、群体协同与飞行操作一体化。关键技术包括端到端强化学习、跨载体泛化决策、分布式集群架构及从观察到操作的飞。

具身智能正推动无人机向自主飞行智能体演进,使其具备感知、决策与执行的闭环能力,能在极端环境下完成任务。其依托集群协同与世界模型等技术,已在巡检、测绘等高危场景验证应用。尽管面临模型效率与部署等挑战,该领域正从实验室探索走向实际应用与价值夯实。

首届人形机器人半程马拉松在京举行,引发对行业泡沫的讨论。千寻智能解浚源认为,领域仍处规模定律早期,硬件迭代是主要瓶颈。技术路径已收敛至端到端的视觉-语言-动作模型,核心在于数据采集的工业化。相比大模型,机器人数据具私有壁垒且能形成数据飞轮,商业潜力显著。依托中国供。

香港大学李弘扬团队与智元机器人合作推出具身智能数据集AgiBotWorld,聚焦灵巧操作、视触觉融合与多机协同。该数据集旨在验证数据多样性的价值,推动规模定律研究,并计划于2025年发布全量数据及举办挑战赛,以建立行业基准,促进算法公平比较与协同创新。
热门专题







热门推荐

在全球紧张局势下,美国国防部将比特币重新定义为国家安全资产,反映出其战略价值提升。美国国库持有大量比特币,大国博弈中加密货币已成为国家安全筹码。市场普遍认为这一身份转变将增强机构需求,推动价格上涨。后续需关注美国政策动向、地缘政治变化及相关监管动态。

当Windows系统遭遇蓝屏时,那些含义不明的错误代码往往令人困扰。例如代码0x00000012 (TRAP_CAUSE_UNKNOWN),其官方解释为“内核捕获到无法识别的异常”。这就像一个笼统的系统警报,提示底层发生了问题,但并未指明具体故障点。此类错误通常不关联特定系统文件,反而更常见于新硬件

必须安装JDK并配置JA VA_HOME与Path环境变量;先下载JDK 17 21 LTS版本,安装时取消“Add to PATH”,再手动设置JA VA_HOME指向安装目录,并在Path中添加%JA VA_HOME% bin,最后用ja va -version等命令验证。 在Windows 1

对于Mac用户而言,从图片中提取文字其实无需额外安装第三方OCR软件。macOS系统自身就集成了强大的光学字符识别功能,它基于苹果自研的Vision框架与Core ML机器学习模型。最大的优势在于完全离线运行,所有图片处理均在本地完成,无需上传至任何云端服务器,充分保障了用户的隐私与数据安全。本文将

数据库长连接在静默中突然断开,是很多运维和开发都踩过的坑。你以为启用了TCP Keepalive就万事大吉?真相是,如果应用层、内核层和基础设施层的配置没有协同对齐,这个“保活”机制基本等于形同虚设。 问题的核心在于,一个完整的TCP Keepalive生效链条涉及三个环节:你的应用程序或连接池是否