光学字符识别(OCR)技术已广为人知,它如同为图像中的文字赋予“视觉”与“认知”能力,使机器能够读取并理解图文信息。而今天我们将聚焦其演进形态——多模态OCR。这不仅是简单的文字提取,更是一种能够同步处理并解析文本、图像、表格乃至音频等多源信息的综合性智能技术。要深入把握其核心价值及其将如何重塑信息处理模式,我们可以从以下几个维度展开探讨。
一、OCR技术基础:从“看见”到“读懂”
简而言之,OCR的核心使命是将图像或扫描文件中的印刷体或手写体文字,转换为计算机可编辑、可检索、可处理的文本数据。这项技术堪称计算机视觉领域中一项经典且关键的任务。
传统OCR流程通常遵循标准化处理步骤:首先对图像进行预处理,包括降噪、对比度调整、倾斜校正等,为识别做好前期准备;随后执行字符分割,将文本行拆分为独立字符单元;最终完成字符识别,把图像中的像素模式对应为具体文字符号。这套方法论在过去数十年间,为大规模文档数字化进程贡献了重要力量。
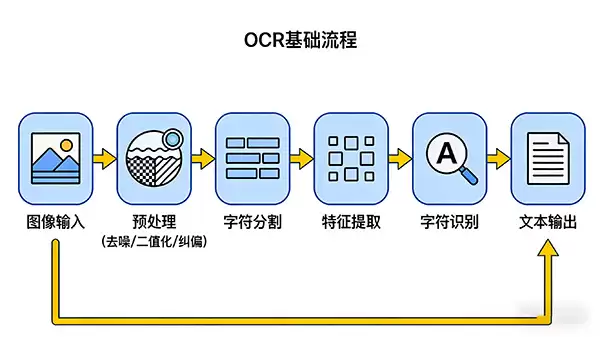
二、多模态OCR的特点与优势:不止于文字
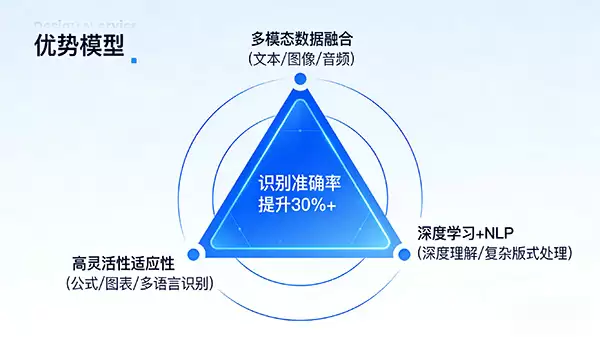
那么,多模态OCR的“多模态”体现在何处?其革命性在于突破了对孤立文本图像的局限,能够融合并协同处理来自不同形态的信息源,例如同一文档中的文字、插图、表格以及附加的音频注解。这种跨模态理解能力,使其足以应对真实场景中更为复杂多元的挑战。
其背后的推动力源于深度学习与自然语言处理(NLP)技术的深度融合。现代多模态OCR系统不再局限于“字符识别”,而是致力于“理解”文档的上下文与语义逻辑。无论是杂志的复杂版面、自然场景中嵌入的文字(如路牌、店铺招牌),还是图文混排的合同文件,系统都能更精准地解析其内在关联,从而大幅提升识别准确率与整体处理效率。
由此带来的是卓越的灵活性与场景适应性。当前前沿模型已能识别并处理数学公式、化学结构式、数据图表、音乐乐谱以及几何图形等特殊内容。这意味着OCR技术的应用边界正在被显著拓宽。
三、多模态OCR的应用场景:赋能千行百业
技术能力的跃升,直接催生了广泛的应用前景。
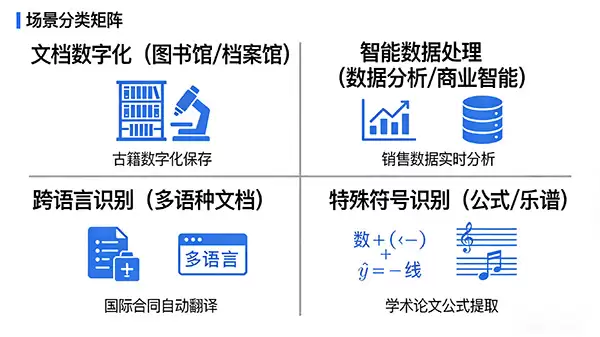
在文档数字化领域,例如图书馆与档案馆的历史文献抢救工程中,多模态OCR能高效处理包含丰富插图、手写批注、特殊符号的珍贵资料,不仅提取文字内容,更能理解图文之间的关联,极大提升了数字资源的检索效率与利用价值。
在商业智能与数据分析方面,该技术成为从海量非结构化数据(如报告、票据、表单图像)中提取关键信息的利器。系统可自动识别表格数据、解读图表含义,并将这些信息转化为结构化数据,为业务决策提供实时、精准的支持。
此外,在全球化协作背景下,跨语言识别也成为其重要舞台。多模态OCR支持多语种文本识别与实时翻译,结合图像上下文信息,能够更准确地处理多语言混合排版文档,有力促进了跨国界的信息流通与协作。
四、多模态OCR的发展趋势:未来已来
展望未来,多模态OCR的发展路径清晰且充满潜力。
首要方向是模型性能的持续优化与提升。随着算法演进与计算能力增强,未来的OCR解决方案必将更加精准、高效,并在应对模糊、遮挡、低质量图像时表现出更强的鲁棒性(即稳定性)。
更重要的是,其应用场景将不断拓展与深化。从自动驾驶车辆识别复杂路况信息,到智能家居设备理解带文字的说明书,再到医疗影像分析中提取诊断报告文本与标注,OCR技术正深度融入各行各业,成为推动产业数字化转型与智能化升级的关键基础设施。
总而言之,多模态OCR代表了文字识别技术向更智能、更综合方向演进的重要趋势。它通过整合多源信息,赋予机器更接近人类的“阅读理解”能力。随着技术持续成熟,必将在更广阔的领域释放价值,加速我们迈向全面智能化的信息处理新时代。





