在人工智能与计算科学的前沿领域,两类核心工具正在重塑我们解决问题的范式:一类是专注于数值模拟的“求解器”,另一类是拥有海量参数的“大模型”。表面上看,前者侧重于经典计算,后者代表了新兴的机器学习,二者似乎界限分明。然而深入探究便会发现,它们之间的关系远比表面更为紧密,正逐步形成一种相互依存、彼此驱动的共生生态系统。
一、定义与功能:基石与架构
首先,我们需要明确两者的基本定位与核心功能。
求解器,堪称数值模拟领域的“计算引擎”。它的核心任务是对已建立的数学模型进行高效、精确的数值求解。具体而言,当用户设定好一个物理、工程或优化问题的条件(例如材料属性、边界约束、目标函数)后,求解器会调用相应的算法(如有限元法、计算流体动力学模型、优化算法),通过一系列标准化的计算步骤——包括模型抽象、控制方程选取、参数设定、边界与初始条件赋予——最终输出问题的定量数值解。它是将理论数学模型转化为具体可量化、可应用结果的关键技术桥梁。

而大模型,通常指参数规模巨大、结构复杂的机器学习模型,尤其是指基于深度神经网络构建的模型。其参数量可达数十亿乃至万亿级别。这种“大规模”并非简单的数量堆砌,其根本目的在于显著增强模型的表征能力与泛化性能,使其能够从海量数据中学习极其复杂的模式(如自然语言语义、图像特征、跨模态关联),并完成更抽象、更通用的预测与生成任务。

二、相互关系:驱动与反哺
那么,这两者是如何产生深度交集的?关键在于,大模型的“训练”与“推理”过程,本质上就是规模空前的数值优化问题。
大模型因其极其复杂的网络架构与海量的可调参数,其训练过程需要处理天文数字级别的计算操作。此时,高效、稳定的数值求解器就变得至关重要。可以说,求解器的性能直接决定了模型训练的“速度”、“效率”与“最终精度”。一个先进的求解器能够更快、更稳健地找到损失函数的全局最优解或高性能近似解,从而显著缩短模型训练周期,并提升最终部署模型的性能与可靠性。没有底层高效求解算法的支撑,大模型的潜力将难以充分释放。
反过来,大模型的迅猛发展及其对算力日益增长的需求,也成为了求解器技术持续创新的核心驱动力。为了适应更大规模、更复杂结构的模型求解需求,传统的优化算法与数值计算技术必须不断演进,例如:更高效地利用GPU、TPU等异构计算资源;设计更适合大规模分布式训练的优化器(如AdamW、LAMB);有效应对训练过程中的梯度消失、梯度爆炸、损失函数地貌不平等数值稳定性挑战。这种来自上层应用的需求,正持续推动计算数学、优化理论与高性能计算领域的边界向前拓展。
三、技术挑战:效率与稳定性的平衡
当然,为大模型提供底层求解支持面临着显著的技术挑战。首当其冲的是计算效率与可扩展性。如何极致地优化CPU、GPU及专用AI芯片的利用率,实现计算任务的并行化、流水线与内存访问优化,是求解器设计的核心课题。
此外,还需专门应对大模型训练中的独特难题,例如:超大规模稀疏数据的处理、损失函数超曲面极端复杂性(存在大量鞍点和平坦区域)导致的收敛困难,以及由数值精度限制和误差累积所引发的训练不稳定性。求解器必须在追求快速收敛的同时,确保整个迭代过程的数值鲁棒性和最终模型输出的可靠性,这需要精妙的算法设计与工程实现。
四、应用领域:合力赋能千行百业
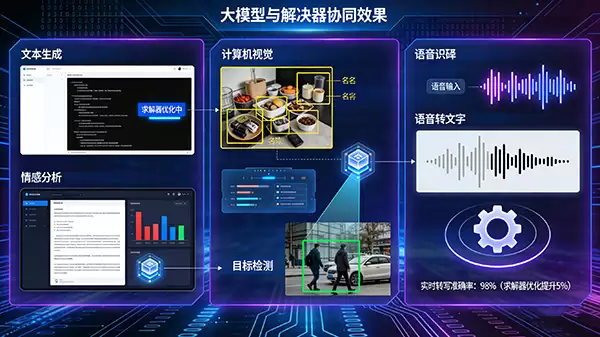
“求解器+大模型”的技术组合,已在众多行业展现出强大的赋能价值。在自然语言处理领域,大模型驱动着智能对话、文本生成、情感分析、高精度机器翻译等应用;在计算机视觉领域,它赋能图像识别、目标检测、视频内容理解与生成;在语音识别与合成领域,它显著提升了人机交互的准确度与自然度。而在所有这些智能应用落地的背后,都离不开求解器在默默执行高效的模型训练、调优与推理计算,将原始数据转化为可用的智能。
综上所述,求解器与大模型之间,构成了一种典型的底层基础设施与上层智能应用之间的深度耦合关系。求解器为大模型的实现与高效运行提供了根本的计算可能性和效率保障,而大模型则不断提出新的、更苛刻的计算挑战,反哺并驱动求解器技术的持续演进。随着人工智能技术向更深层次、更广场景发展,这种共生共荣的协同关系将愈加紧密,共同构成推动相关领域技术突破与产业创新的核心双引擎。