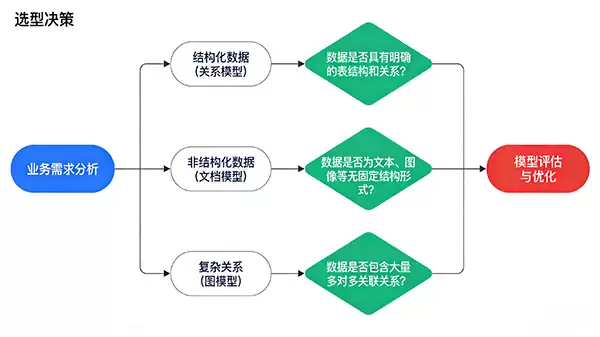
数据库常被视为技术黑箱,但支撑其高效运转的核心蓝图正是数据模型。数据模型定义了数据如何被结构化、关联与解读,是数据库设计的基石。理解不同数据模型的分类与特性,对于构建高效、可扩展的数据系统至关重要。

数据模型可以从多个维度进行分类,每种分类方式都揭示了其不同的设计哲学与应用场景。下面我们将从应用层次、数据结构以及新兴模型等角度,系统梳理主流数据模型的特点。
一、按照应用层次划分
在数据库系统设计与开发过程中,数据模型通常被划分为三个抽象层次,它们如同建筑蓝图,从宏观概念到物理实现逐级细化。
概念数据模型,也称为信息模型。它从业务视角出发,抽象出核心实体(如“客户”、“产品”、“订单”)及其相互关系,不涉及具体技术实现。常用的建模工具包括实体-关系(E-R)模型和面向对象模型,其核心目标是构建一份清晰、无歧义的“业务概念地图”。
逻辑数据模型是连接业务与技术的桥梁。它将概念模型转化为特定数据库管理系统(如关系型、层次型或网状型数据库)所能理解的结构。这一层定义了数据的逻辑结构、约束和关系,是数据库设计的核心输出。
物理数据模型关注数据在存储介质上的具体实现细节。它涉及文件组织方式、索引策略、数据分区、存储引擎选择等,与数据库软件、操作系统及硬件性能紧密相关,直接决定了系统的存取效率。

二、按照数据结构划分
从数据自身的组织方式和关系结构来看,传统的数据模型主要分为三大类,它们代表了不同的数据管理范式。
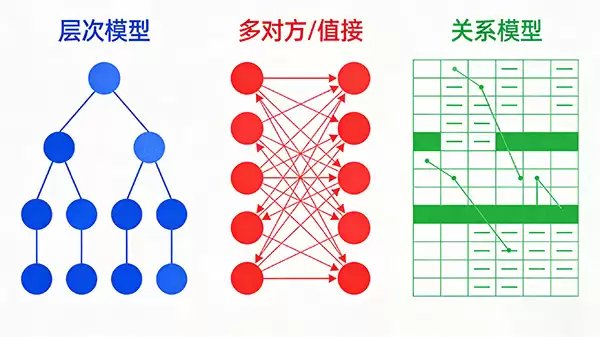
层次模型采用树状结构组织数据,每个子节点仅有一个父节点,形成清晰的层级关系。这种模型结构简单、查询路径固定,非常适合描述具有天然层次结构的数据,如公司组织架构或文件系统目录。
网状模型允许节点之间存在多对多的复杂关联,形成一个灵活的网状结构。它能更直观地表达现实世界中复杂的实体关系,但随之而来的是数据操纵语言复杂和结构维护难度较高。
关系模型是当今最主流的数据库模型。它使用二维表格(关系)来存储数据,并通过主键、外键等机制建立表与表之间的联系。其强大的理论基础(关系代数)、清晰的结构和标准化的查询语言(SQL),使其成为企业级应用的首选。
三、其他数据模型
随着互联网、物联网和大数据技术的发展,数据形态日益多样化,催生了多种针对特定场景优化的新型数据模型。
面向对象模型将面向对象编程思想引入数据库领域,支持对象、类、继承、封装和多态。它能够更自然地映射复杂的业务对象,广泛应用于CAD、多媒体等复杂数据领域。
文档模型以半结构化文档(如JSON、BSON、XML)为基本存储单元。每个文档包含键值对或嵌套结构,模式灵活,非常适合内容管理、产品目录和用户画像等场景。
键值模型结构最为简单,通过唯一的键来访问对应的值(值可以是任意数据类型)。它提供了极高的读写性能,常用于缓存、会话存储和配置管理。

列存储模型将数据按列而非按行进行组织和压缩存储。这种模型极大地提升了数据仓库和分析型查询(如聚合、扫描特定列)的效率,是大数据分析的重要技术。
图模型由节点(实体)和边(关系)构成,擅长处理高度互联的数据。它在社交网络分析、欺诈检测、知识图谱和推荐系统中有着不可替代的优势。
时序模型专为处理时间序列数据优化,数据点按时间戳顺序存储。它在物联网监控、金融分析、运维监控等领域应用广泛,支持高效的时间范围查询和聚合。
混合模型(或多模型数据库)融合了两种或多种数据模型的能力,旨在用一个数据库平台满足应用程序多样化的数据需求,简化技术栈。
总结而言,数据模型的选择是一项关键架构决策。从经典的关系型、层次型模型,到为现代应用而设计的文档型、图数据库及时序数据库,每种模型都有其最佳适用场景。深入理解各类数据模型的原理、优势与局限,是设计高性能、高可维护性数据系统的前提。决策者需综合考量数据结构特性、查询模式、一致性要求及扩展性需求,方能做出最优选择。