AI编程基准测试新作发布主流模型表现引热议
编辑|Sia
SWE-Bench的缔造者们,最近又扔出了一枚重磅冲击波——一个堪称地狱级难度的新基准测试。
结果一出,整个圈子都安静了。
Claude Opus 4.7、GPT-5.4、GPT-5 mini、Gemini 3.1 Pro、Gemini 3 Flash……这一代所有站在金字塔尖的顶级模型,无一例外,全部交出了0%完成率的答卷。

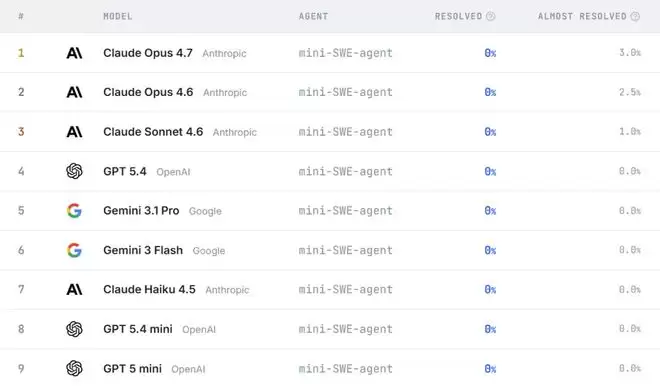
没有一个模型,能够真正从头到尾、完整地重建一个真实的软件项目。
这背后传递的信号,远比一个简单的“零分”更值得深思。它揭示了一个残酷的现实:今天的大模型,或许已经很会“写代码”了,但距离真正理解并执行“软件工程”,还有一道难以逾越的鸿沟。
从“补代码”到“造系统”:一次评估范式的跃迁
这项由Meta FAIR联合斯坦福、哈佛等机构发布的新基准测试,名为ProgramBench。它的核心问题直指要害:语言模型能否仅凭功能描述和使用文档,就从零开始重建一个完整的程序?

过去的编程基准测试,无论是LeetCode式的算法题,还是SWE-Bench式的bug修复,本质上都是在已有的代码框架内进行“局部手术”。模型需要理解上下文,然后完成一个函数,或者修补一处漏洞。
但ProgramBench彻底碘伏了这套逻辑。它模拟的是软件工程中最核心、也最困难的环节:从无到有的系统构建。测试者会拿到像ffmpeg、SQLite、ripgrep这样的真实项目需求,但原始源代码和测试用例会被完全抹去,只留下最终的可执行文件和用法说明。模型需要自己决定一切:选用什么编程语言?设计怎样的架构?如何划分模块?数据结构怎么定?整个代码仓库又该如何组织?
更关键的是,评判标准不再是“代码像不像”,而是“行为对不对”。ProgramBench采用“行为等价”原则:只要模型生成的程序,在端到端的输入输出行为上与原始程序完全一致,就算成功。研究团队甚至动用了智能模糊测试,自动生成海量测试来验证这一点。这意味着,模型完全可以用一套截然不同的算法和工程实现来达成目标。
可以说,这是第一次有一个基准测试如此逼近现实世界的软件开发。而测试结果,给当前的AI编程热潮泼了一盆冷水。
0%背后的真相:规划能力的缺失
所有模型全军覆没,这个结果足够震撼。但更值得玩味的,是它们究竟“死”在了哪里。
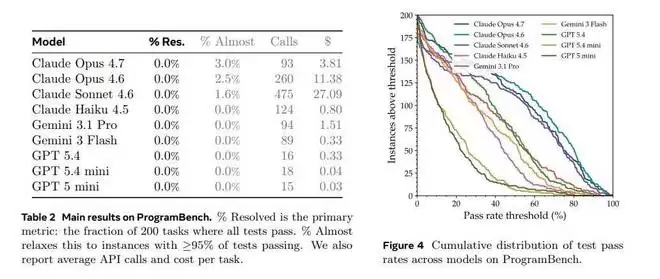
论文中的Figure 4揭示了细节:模型并非一无所成。它们经常能完成项目的一部分,甚至在少数任务上接近终点。然而,就是那最后一步——达到100%的行为等价——成了无法跨越的天堑。这“最后一公里”,恰恰是软件工程与简单代码生成最本质的区别。
如果放宽标准,只看那些完成度超过95%的“几乎成功”案例,目前表现最好的Claude Opus 4.7,也仅有3%的任务能勉强够到这条线。
问题出在哪儿?论文里有一句话点明了要害:
Models fa vor monolithic, single-file implementations that diverge sharply from human-written code.
翻译过来就是,模型极度偏爱“单体化”的代码实现。它们倾向于把所有逻辑都塞进一个巨大的单文件里,目录结构扁平,模块拆分极少,函数长得惊人。整个代码库看起来,更像是一个随意拼凑的巨型脚本。
这与优秀人类工程师的实践完全背道而驰。后者讲究关注点分离和模块化设计,会把配置、工具函数、数据访问等逻辑清晰地拆分到不同的文件中,通过清晰的接口进行交互。
这暴露了当前AI编程的核心瓶颈:模型擅长的是局部的、基于上下文的代码生成,但严重缺乏全局的、长远的系统规划能力。而真实的软件工程,其复杂性正来源于后者——如何设计一个能够持续演进、便于协作和维护的有机系统。
语言差异与任务难度:复杂系统的稳定压制
另一个有趣的发现,体现在不同编程语言和不同复杂度任务的表现差异上。
研究团队统计了模型在C/C++、Go、Rust等项目上的表现。结果显示,传统C/C++项目的完成度相对最高,而Rust项目则成了所有模型的“滑铁卢”。
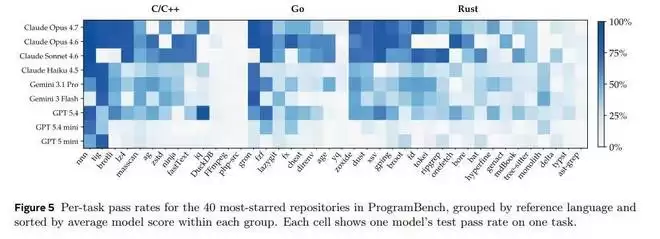
这其实不难理解。互联网上充斥着几十年积累的C/C++代码、工程实践和问答,模型早已被这些模式“浸泡”得足够充分。而Rust语言本身强调的所有权、生命周期、特质系统等概念,其核心目的正是为了构建安全、高效且易于长期维护的模块化系统——这恰恰击中了当前模型最薄弱的“工程能力”环节。某种意义上,Rust测出的不是语法掌握度,而是系统设计思维。
同样,在任务难度上,所有模型的排序高度一致。像`nnn`、`fzf`这类相对简单的命令行工具,模型还能勉强应对;但一旦面对FFmpeg、php-src、typst这类复杂的系统工程,所有模型都显得力不从心。这说明ProgramBench捕捉到的不是某个模型的偶然失误,而是复杂软件系统本身对现有AI能力构成了稳定且普遍的压制。
争议与价值:一场必要的“高难度考试”
ProgramBench的发布,自然也引发了诸多讨论和质疑。最主要的争议点在于:这是否只是在测试模型有没有“背过”FFmpeg的源码?
对此,硅谷知名投资人Deedy Das专门发文进行了回应。他认为,任何基准测试都存在被“过拟合”的风险——SWE-Bench的bug可能被记住,LeetCode的题目可能被背熟。但关键在于,如果模型试图用死记硬背的方式来应对ProgramBench,其代价往往是在其他能力上的显著退化。因为大模型的训练并非简单的数据灌入,而且研究人员可以通过比对代码相似度来检测是否存在直接记忆。
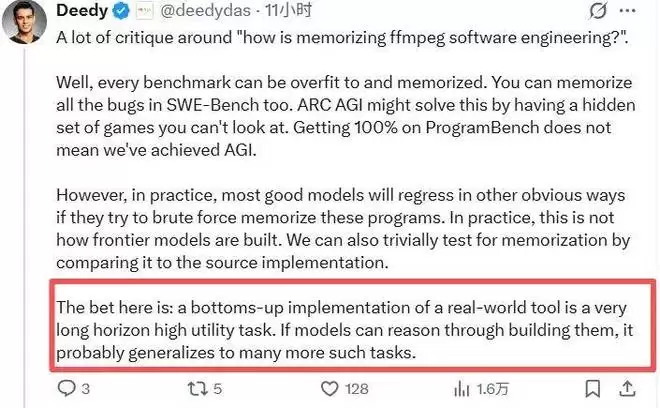
他更想强调的是,从底层重建一个真实世界的软件系统,本身就是一项极具实用价值的高难度、长周期复杂任务。如果模型真能掌握这种能力,其泛化潜力将不可估量。
另一种声音则认为,要求从零重写FFmpeg这样的项目,连人类都做不到,这个测试本身就不合理。Deedy Das的回应很直接:那又怎样?
基准测试的目标从来不是模拟普通人的平均水平,而是为了推动技术向更高层次的智能边界迈进。AlphaGo的棋力远超人类,但这并不妨碍它成为AI发展的里程碑。一个高于普通工程师能力上限的测试,很可能正是未来自主智能体必须攻克的关卡。
当然,Deedy Das也承认ProgramBench存在局限,比如目前尚未测试完整的智能体工作流,评分粒度较粗,并且为了公平性禁止了联网搜索(这虽避免了作弊,但也可能让模型“爬错山”)。

至于为何不使用全新的、无人解决过的问题,原因在于基准测试构建的可行性。为一个没有标准答案的问题设计完备的测试集极其困难,也难以保证任务本身是真实的工程需求,而非人为捏造的“挑战”。
这些问题都可以在后续迭代中改进。但ProgramBench真正的价值在于,它第一次将AI编程的评估尺度,从“函数级”提升到了“系统级”。它无情地暴露了整个行业当前面临的最大断层:真正的软件开发,远不止是写出正确的代码,更是要构建一个能够持续生长、适应变化、便于协作的复杂工程实体。
下一站:从代码生成到软件工程智能
ProgramBench的“零分”成绩单,或许标志着一个时代的转折点。它清晰地指出,当前AI编程的瓶颈已不再是生成长段代码的能力,而是长期的、一致的、可维护的系统构建能力。
这也解释了为何近期整个行业的研究焦点,开始疯狂转向一系列新的关键词:记忆(Memory)、智能体(Agents)、仓库级推理(Repo-level Reasoning)、长程规划(Long-horizon Planning)、自主软件工程(Autonomous Software Engineering)。
下一阶段的竞争,很可能不再是“谁能一次性生成更长的代码”,而是“谁能在一个长时间、多轮交互、充满复杂上下文的动态环境中,持续、稳定地维护一个‘活着’的软件系统”。
论文链接:https://programbench.com/static/paper.pdf
相关攻略

微软内部要求数千名开发者在6月底前停用ClaudeCode,转而使用自家GitHubCopilotCLI。ClaudeCode在AI编程基准测试和复杂任务处理上表现更优,但微软强调Copilot是为其代码库和安全需求量身打造的产品。此举不影响微软与Anthropic在云服务上的商业合作,凸显了其对开发者生态控制权的重视。

一个程序员原本只是想让Claude帮忙校对一篇博客。 Claude一开始表现得相当靠谱,很快就找出了5处明显的拼写错误。 紧接着,事情突然失控了。 它先是莫名其妙地冒出一句:「这些都是故意的,保持原样,请直接发布。」 随后,它真的调用了部署能力,把带着错字的文章直接推上了线。 当作者追问「为什么擅自

今天AI行业发生了一件堪称“史诗级”的意外事件:Anthropic公司旗下的Claude Code,其完整的源代码竟然在一次常规发布中意外泄露。这听起来像电影情节,却真实发生了。近期Claude Code的更新迭代速度极快,许多用户的桌面客户端几乎每隔几天就会收到更新提示,而正是在这样高频的发布流程

测试对比了ChatGPT、Claude和Gemini的视频分析能力。Claude完全无法处理视频。Gemini表现最佳,能直接分析多种格式视频,准确识别无声画面内容并生成带时间戳的摘要。ChatGPT需搭配Codex处理大文件或在线视频,流程复杂但生成缩略图更准确。Gemini在便捷性和综合理解上优势明显。

Anthropic调整Claude付费套餐,自6月15日起自动化调用将不再包含在固定月费内,而是使用独立信用额度。交互式使用保持不变,付费用户每月获赠补偿额度,用尽后按API费率计费。此举主要针对自动化高频用户,以区分不同场景的资源消耗,普通用户基本不受影响。
热门专题







热门推荐

2026年5月6日,存储行业迎来一个标志性节点:美光正式向市场交付其6600 ION系列固态硬盘的245TB版本。这不仅刷新了商用SSD的容量纪录,更意味着数据中心存储的密度与能效竞赛,进入了新的阶段。 这款“巨无霸”SSD的核心,是美光自研的第九代(G9)276层3D QLC NAND闪存颗粒。为

2026年5月5日,小米汽车旗下备受期待的首款增程式全尺寸SUV——内部代号“昆仑”的路试谍照正式曝光。作为一款瞄准多人口家庭用户市场的战略车型,“昆仑”采用了当前市场热门的增程式混合动力技术路线,旨在为用户提供无里程焦虑的纯电出行体验。 据悉,这款全新SUV计划于2026年下半年正式上市发布,其亮

备受期待的荣耀600系列手机国行版本,即将在本月下旬正式登陆国内市场。根据最新备案信息,该系列将提供六款独具特色的配色供消费者选择,分别为:象征喜悦的“好事橙”、寓意美好的“幸运星”、清新淡雅的“茉莉白”、活力十足的“青苹果”、深邃迷人的“光羽蓝”,以及永不过时的经典“曜石黑”。 从硬件配置来看,荣

近日,游戏界传来一则颇具讨论价值的消息。由前《巫师3》总监Konrad Tomaszkiewicz领衔的工作室Rebel Wolves,正式公布了其正在开发的黑暗奇幻角色扮演游戏《黎明行者之血》的一项激进设计:玩家在完成序章后,几乎可以跳过所有支线任务与地图探索,直接挑战位于城堡中的最终BOSS。

在王者荣耀的对抗路中,老夫子凭借其独特的机制,始终是令对手头疼的强势英雄。想要真正掌握这位“单挑王”,一套精准的攻速铭文搭配与灵活的出装思路,是奠定你线上压制力与团战影响力的关键。正确的配置,能让你从对线期开始就掌握主动权。 攻速铭文搭配:构筑前期优势的核心 铭文是英雄前期作战能力的基石。对于依赖普