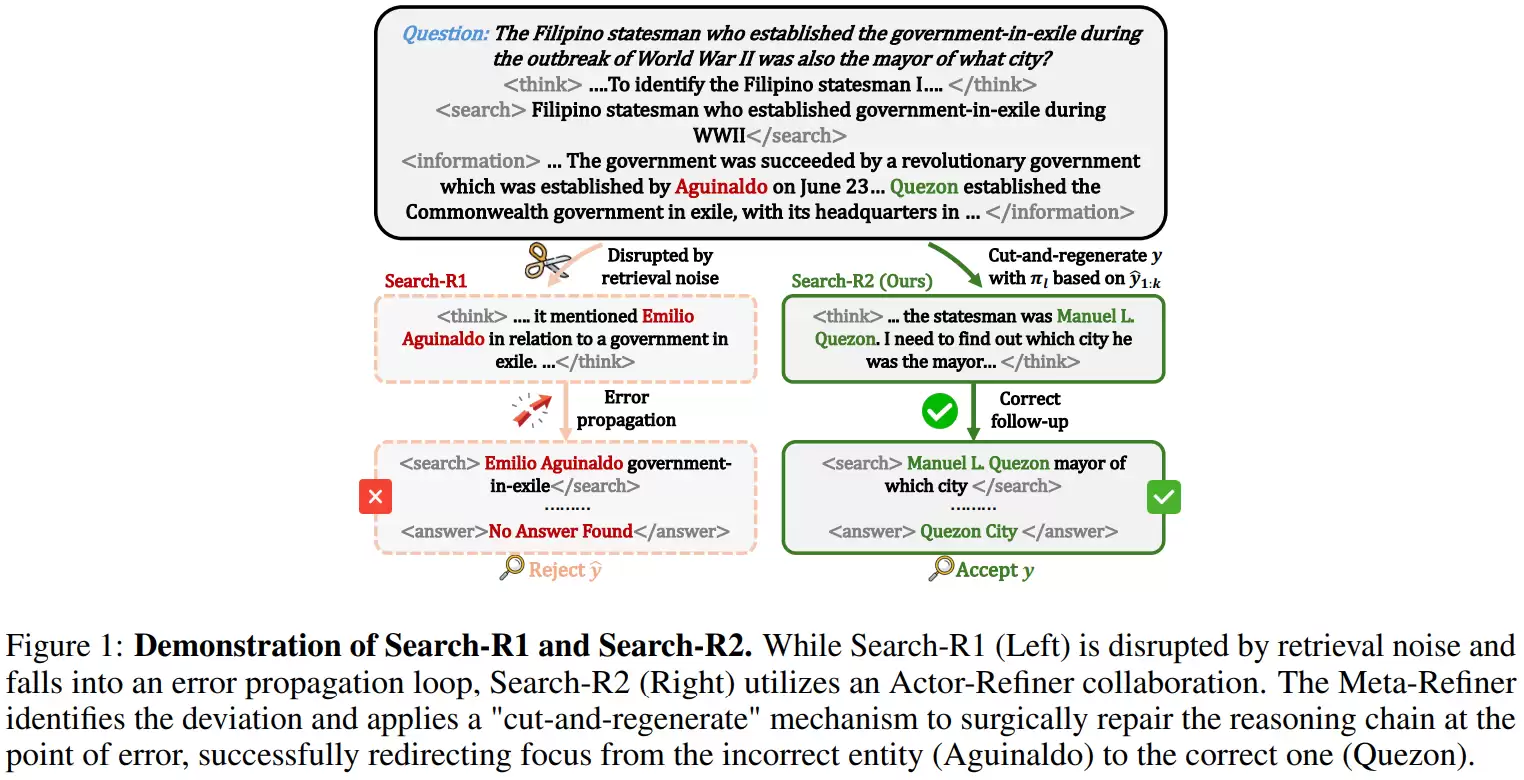
腾讯混元与MBZUAI新研究 Search-R2如何优化搜索增强推理
近年来,大语言模型的能力飞跃,很大程度上依赖于“规模效应”——通过增加参数规模和扩展训练数据来实现。然而,当模型从演示环境走向实际应用,承担起研究助理、智能搜索引擎乃至复杂决策支持等角色时,这种单纯依赖规模的增长路径便逐渐触及了天花板。
这些真实世界的复杂任务,往往要求模型在开放环境中进行多轮、交互式的搜索与深度推理,“搜索增强推理”因此成为主流技术范式。但这一范式也暴露出一个核心痛点:模型在长链条推理任务中失败,很多时候并非因为“逻辑推理能力不足”,而是无法有效应对和遏制错误在推理链条中的“产生”与“级联传播”。
现实世界的网络搜索不可避免地包含噪声和不确定性。一旦在早期检索环节采纳了有偏差或错误的信息,后续的推理过程就可能在错误的语义空间中越走越偏,最终生成一个逻辑自洽但事实错误的答案。更棘手的是,现有的主流训练方法通常仅以最终答案的对错作为优化目标。这导致那些凭借运气在最后关头拼凑出正确答案的轨迹,与那些每一步都严谨可靠的轨迹,获得了同等的奖励。长此以往,模型对推理中途的搜索质量与错误约束力反而被削弱了。这也解释了为何在多轮搜索、多跳推理等复杂任务中,性能下降往往呈现出系统性、难以挽回的特征。
正是为了突破这一关键瓶颈,来自MBZUAI、香港中文大学与腾讯混元团队的联合研究小组,提出了创新性研究成果《Search-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration》。
这项工作精准地瞄准了搜索增强推理中的两大核心挑战:长链推理中的信用分配难题,以及推理中途动态纠错机制的缺失。它通过将推理生成、轨迹质量判断与错误源头定位整合到一个统一的强化学习框架中,使得训练信号能够精确地回溯到错误首次发生的关键节点,从而从源头上抑制错误的扩散与放大。
在AI智能体正从“能力展示”迈向“任务承担”的关键转型期,这项研究的意义,不仅在于提供了一个精巧的工程解决方案,更在于为搜索型智能体指明了一种更贴近现实失败模式的学习范式:它不再假设推理过程天生完美可靠,而是坦然承认错误在所难免,并让模型在训练中主动学会如何与错误共存、如何精准定位并修正它们。

构建完整优化闭环,而非依赖单一技巧
从实验结果来看,该方法带来的优势并不仅体现在整体性能的平均提升上。更值得关注的是,在任务难度最高、错误最易累积和放大的复杂场景中,其表现尤为突出。
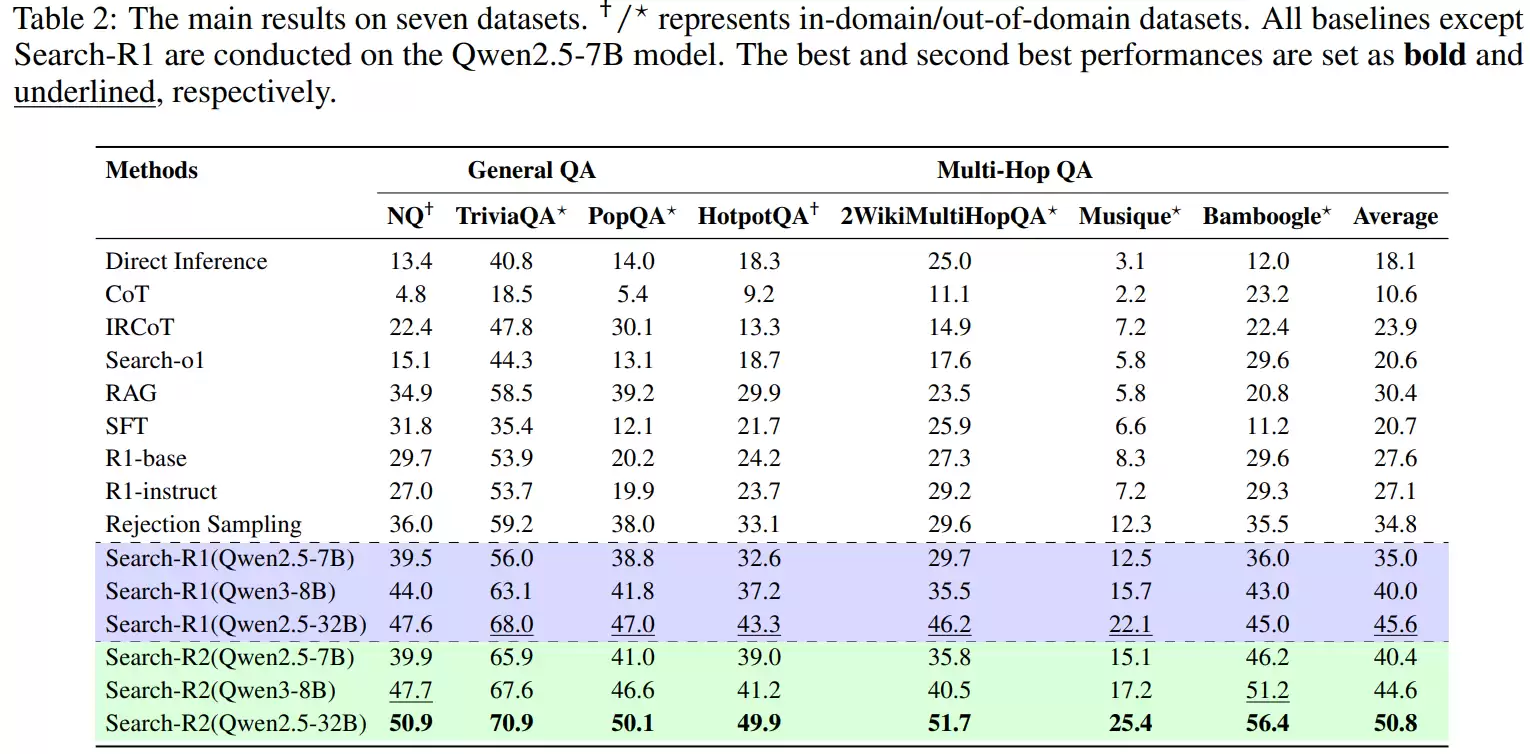
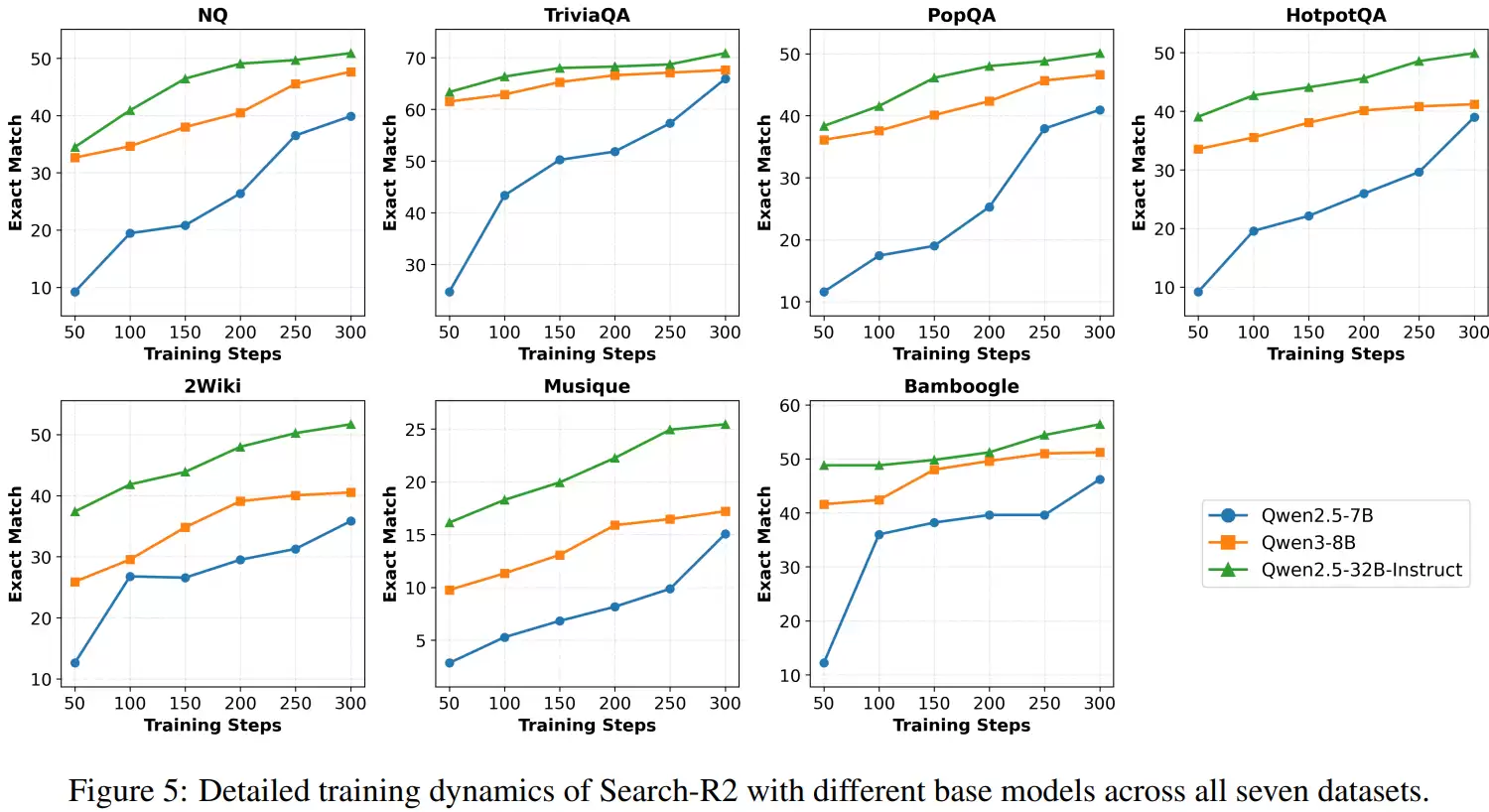
实验涵盖了简单事实型问答与复杂多跳推理问答两大类别。前者通常只需一两次精准检索即可完成,而后者必须经历多轮“搜索—推理—再搜索”的循环迭代,中间任何一步的微小偏差都可能在后续环节被指数级放大。
数据显示,该方法在两类任务上均取得了稳定的性能提升,但在多跳推理任务上的提升幅度显著更大。在HotpotQA、2WikiMultiHopQA和Bamboogle这类需要多轮检索协同推理的经典数据集上,相较于基线方法,带来了从数个百分点到超过十个百分点不等的准确率提升。其中,在Bamboogle数据集上的相对提升幅度甚至超过了二十个百分点。
这强烈暗示,其优势并非源于模型参数记忆能力的增强,而是源于对长链推理过程中错误传播路径的有效识别与阻断。研究人员指出,多跳推理的失败,往往并非因为模型无法生成最终答案,而是中途某次搜索引入了错误或无关信息,导致整个推理方向发生根本性偏移。此后即便继续搜索,也只是在已被污染的语义空间里无效打转。该方法正是针对这一典型的失败模式进行针对性设计,因此其优势在此类任务中被显著放大。
为了进一步验证其有效性,研究团队与经典的“拒绝采样”策略进行了对比实验。他们甚至大幅提高了基线方法的采样预算,允许每个问题尝试更多次搜索轨迹。但结果显示,即便在这种条件下,基线方法的整体性能仍然低于该方法在较小采样预算下取得的结果。
这一对比清晰地表明,性能提升并非来自“通过大量尝试博取偶然成功”的概率性收益。关键在于能否准确识别错误首次出现的关键位置并进行针对性干预。拒绝采样在生成失败后会丢弃整条轨迹从头再来,而该方法则认为,失败轨迹的前半部分往往仍然是正确且有价值的,真正导致崩盘的通常是某一次具体的、低质量的搜索操作。这次搜索引入的噪声会在后续推理中持续放大,从而使得两种策略在长链推理任务中的样本效率产生了数量级的差异。
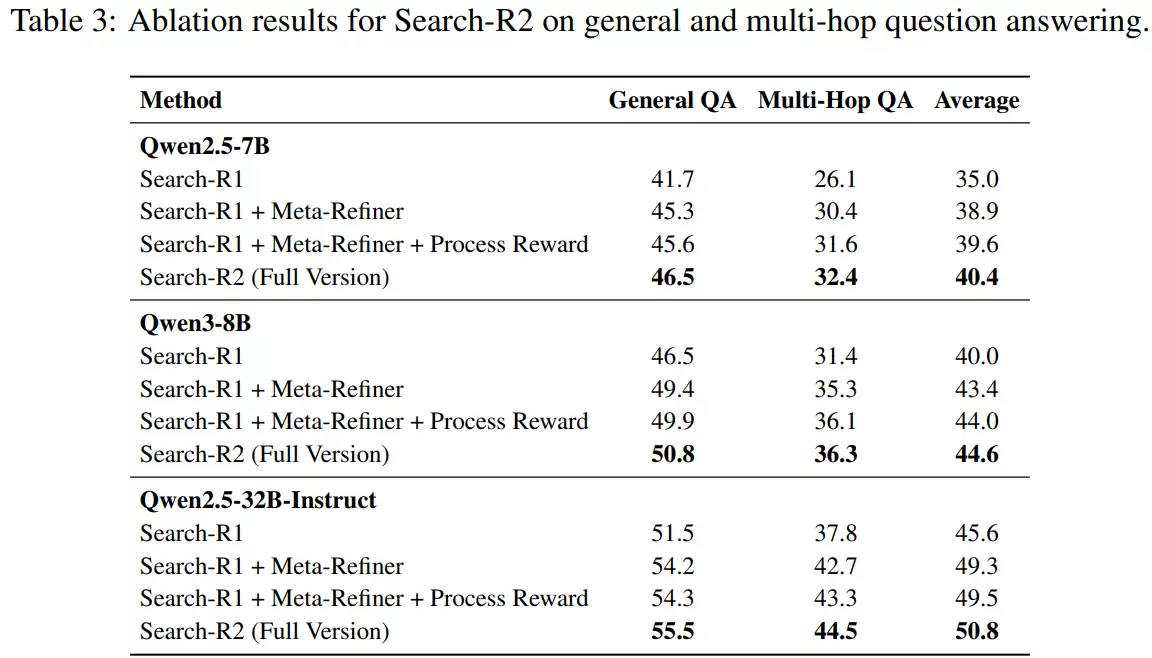
那么,性能提升的具体来源是什么?通过系统的消融实验,各个核心模块的作用被清晰地揭示出来:
仅引入中途纠错机制(而不加入过程奖励),模型在多个数据集上的性能就已出现显著提升。这说明,对推理过程中的关键性错误进行精准定位和修复,本身就能有效解决搜索增强推理的核心瓶颈问题。
在此基础上,加入用于衡量搜索结果信息密度与相关性的过程奖励后,模型性能得到进一步巩固与提升。这表明,显式地区分高质量搜索与低质量搜索,能为训练过程提供更稳定、更细粒度的优化方向指引。
最终,在对推理生成模块与纠错模块进行端到端联合优化的完整设置下,模型在所有评测数据集上取得了最优结果。这证明,纠错能力并非一套预设的静态规则,而是一种需要在训练过程中被逐步学习和内化的动态行为策略。
整体来看,该方法的性能提升并非源于某个单一技巧或额外计算资源的简单堆砌,而是由“中途纠错”、“搜索质量建模”和“联合优化”三大机制协同作用所构成的完整优化闭环带来的系统性收益。
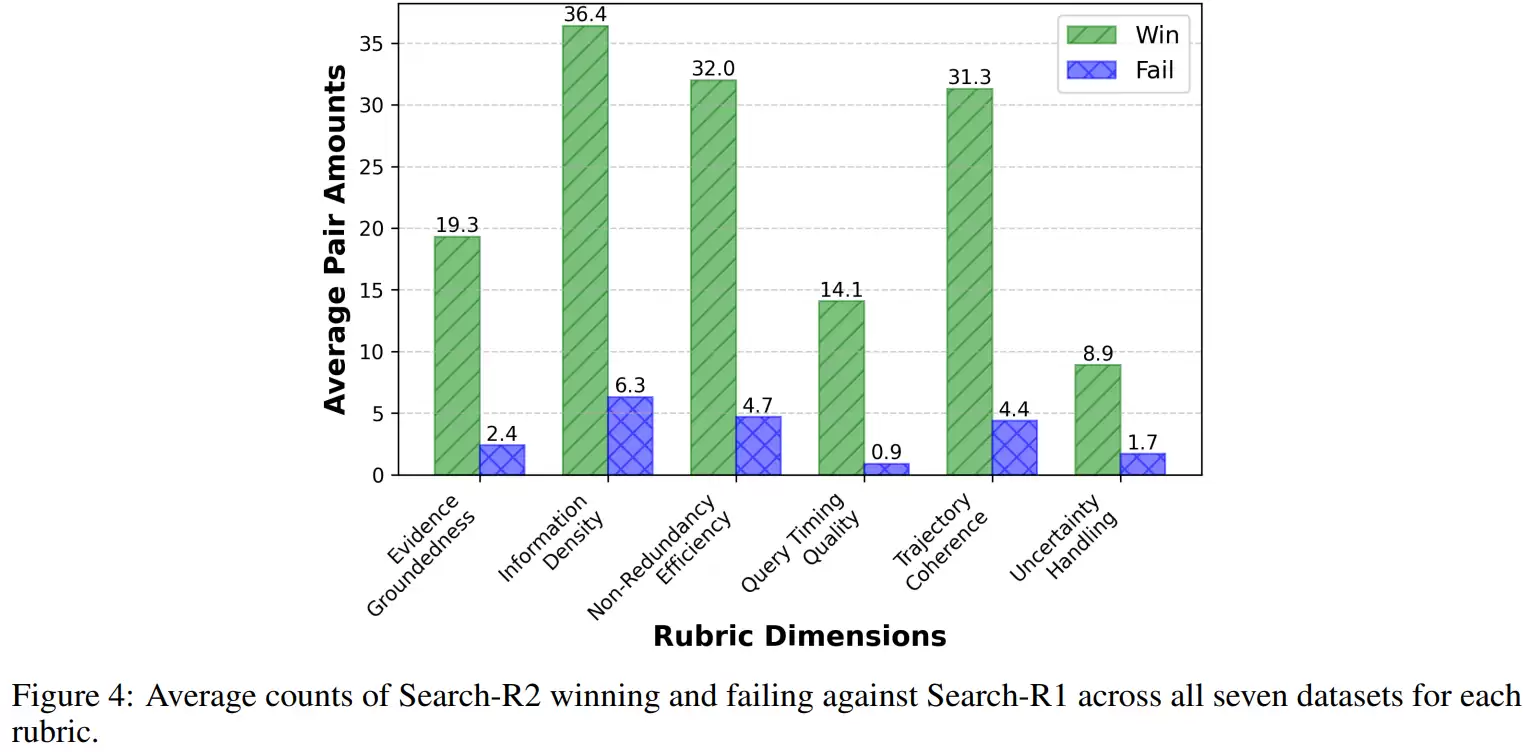
将纠错决策本身纳入可学习的策略空间
在方法设计上,研究团队首先指出了一个根本性问题:在搜索增强推理任务中,仅依赖最终答案的对错作为强化学习的稀疏奖励信号,会导致信用分配的系统性失效。
原因在于,在此类任务中,模型实际上需要连续做出多尺度、序列化的决策:是否发起搜索?搜索什么关键词?何时进行搜索?获得检索结果后,是否应该信任并使用这些信息?然而,传统强化学习只提供一个“最终答对或答错”的单一、延迟的反馈信号,根本无法区分这些中间决策的质量差异。其结果是,那些靠运气在最后阶段拼凑出正确答案的推理轨迹,与那些逻辑严密、搜索路径合理的优质轨迹,获得了完全相同的奖励。
经过长期训练,模型自然会学到一种投机策略:搜索行为可以随意展开,早期错误不会受到实质性惩罚,只要最终能生成一个看似合理的答案即可。这正是现有许多搜索增强方法在长链推理任务中容易发生系统性性能崩溃的根源。
基于这一深刻洞见,研究团队在方法中对不同功能模块进行了明确分工与协同设计:
推理生成模块(Actor)负责像常规方法一样,完整生成一条包含推理步骤与搜索行为的轨迹。这个模块被允许在生成过程中进行探索甚至犯错,不承担中途自检或即时修复的职责,从而保持生成的流畅性与多样性。
随后引入的纠错模块(Refiner),其首要任务是对整条推理轨迹进行全局质量判断。它关注的重点并非最终答案是否正确,而是推理过程是否始终围绕原始问题核心展开,是否出现了明显的实体偏移、主题漂移或证据错位。这一判断决定了轨迹是否值得继续修复——标准过于宽松,错误轨迹会被放过;过于严格,高质量轨迹又会被反复打断。这个接受与拒绝之间的最佳平衡点,并非由人工预先设定,而是通过强化学习过程自动、动态地习得的。
当轨迹被判定为需要修复时,系统会进一步精确定位推理过程中第一次发生实质性偏离的位置——即,具体是哪一次搜索或推理操作,将整个系统带离了正确的轨道。
一旦这个关键错误位置被识别,系统会完整保留此前已经生成的正确推理前缀,丢弃其后被错误信息污染的内容,并从该点重新生成后续的推理步骤。这样做,既避免了浪费已有的正确中间结果,又使得奖励信号能够精确回传至错误发生的具体位置,促使模型逐渐学会识别哪些类型的搜索错误最具破坏性并应主动避免。研究人员在理论分析中将这种错误定位能力形式化为“修剪能力”,并证明它是实现整体性能提升的必要条件。
为了防止模型学会“只修正最终输出而忽视错误根源”的投机行为,研究团队在训练中进一步引入了过程层面的奖励信号,用于量化评估检索到的证据中有多少比例是真正支持最终答案的有效信息,而非无关噪声。同时明确规定,该过程奖励仅在最终答案正确的前提下才会被激活。这就保证了,提升搜索质量是达成正确答案的必要条件,但不足以单独驱动模型的优化目标,避免了局部最优。
最后,推理生成模块、轨迹判断模块和错误定位模块并非相互独立,而是共享同一套底层参数,并在同一强化学习目标下进行联合优化。这意味着,“是否触发纠错”以及“在何处进行纠错”,本身都被视为模型策略决策的一部分。其结果是,模型在训练完成后,即便不显式触发多次修复循环,其初始生成的推理轨迹质量本身也得到了显著提升,具备了更强的“一次成功率”。
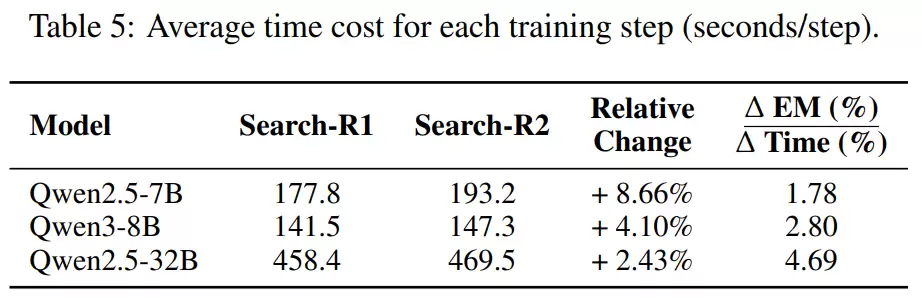
一种更贴近真实失败模式的学习范式
从强化学习的理论视角看,这项研究解决的并非某个单一模块或训练技巧的问题,而是搜索推理中长期存在的、棘手的信用分配难题。在长链决策过程中,模型需要在多个时间尺度上连续做出选择,而传统方法只能依据最终结果进行粗颗粒度的回报分配,导致无法有效区分高质量推理轨迹与依赖偶然性的成功轨迹。
研究团队通过引入轨迹筛选、错误定位和受控纠错三种核心机制,将原本难以处理的信用分配问题,拆解为一系列可操作、可优化的子学习目标。理论分析证明,只有当模型能够有效区分哪些轨迹值得保留、能够精准定位导致推理偏离的关键错误位置,并在训练过程中触发数量适当的纠错操作时,整体性能才会获得稳定且可解释的提升。这一结论并非简单的经验归纳,而是通过严谨的形式化分析给出的必要条件。
在方法论上,该研究进一步改变了以往“反思与修正”仅依赖人工设计提示词的做法,将“是否进行反思”以及“在何处进行修正”都纳入了模型的策略空间,使其成为可以通过强化学习直接优化的决策行为。这从根本上避免了人工提示难以学习、效果不稳定、泛化性差的问题。
更重要的是,这个方法的设计理念直接针对真实智能体任务中常见的失败模式:搜索结果本身存在噪声、推理过程依赖较长的决策链条、早期一次微小错误可能对后续产生不可逆的灾难性影响。通过在推理过程中显式地建模错误传播路径,并提供动态的中途干预机制,这项研究为搜索型智能体在复杂、开放域任务中的稳定、可靠运行,提供了一种更具针对性、实用性和可扩展性的解决思路。
Search-R2 的研究者们
这篇论文的第一作者是何博威,他目前在MBZUAI的机器学习系担任博士后研究员,合作导师是刘学教授。在此之前,他是香港城市大学计算机科学系的博士研究生,师从马辰教授。他的研究方向涵盖数据挖掘、大语言模型、AI for Science(曾与清华/香港城市大学马维英教授团队合作)以及智能体AI。
近期,他的研究焦点主要围绕AI智能体的一系列前沿探索性课题,包括智能体强化学习、智能体记忆、长时程智能体、智能体终身演化、智能体世界模型,以及智能体数据的Scaling Laws等。

这篇文章的共同第一作者是Minda Hu,目前是香港中文大学计算机科学与工程系的博士研究生,在MISC Lab从事研究工作,导师为金国庆教授。他的研究兴趣主要包括数据挖掘、机器学习和自然语言处理,并特别关注机器学习、社会计算与自然语言处理等方向的交叉问题。当前的研究重点在于探索如何更高效、有效地利用大语言模型,以提升模型在实际应用场景中的复杂推理能力与整体效能。

此外,该项工作还得到了麦吉尔大学、香港城市大学和爱丁堡大学等多位研究者的积极参与和重要贡献。值得一提的是,该论文标题“Search-R2”还得到了来自UIUC和Google的“Search-R1”作者团队的官方授权与认可。
相关攻略

你是否好奇,游戏《GTA》中飞驰的汽车与现实中监控摄像头拍下的车辆,在人工智能的“视觉系统”里究竟有多大差别?尽管现代游戏画面已极为逼真,光影、材质与场景构建都栩栩如生,但对于自动驾驶、交通监控、智慧城市管理等需要落地应用的AI算法而言,虚拟游戏图像与真实世界照片之间,依然横亘着一道肉眼难以分辨、却

这项由香港大学、京东探索研究院、清华大学、北京大学和浙江大学联合完成的研究,以技术报告形式发布于2026年4月,论文编号为arXiv:2604 25427,有兴趣深入了解的读者可通过该编号查询完整原文。 你是否曾尝试用AI生成视频,却对结果感到失望?画面与描述不符、人物肢体扭曲、场景光影闪烁,最终视

2026年4月,一项由伦斯勒理工学院与亚利桑那州立大学联合开展的研究,在arXiv预印本平台发布(编号:arXiv:2604 24040v1),系统性地揭示并量化了AI表格检索领域一个长期存在的“盲点”——表格序列化格式对检索性能的巨大影响。 一、格式不同,AI就“认不出”同一张表格了? 设想一个典

腾讯混元团队提出新方法,使模型在推理时能根据输入动态生成参数,实现实时适配。实验表明,该方法在图像编辑任务中效果显著,能有效处理冲突需求,并在多项评测中领先,推动了智能模型从静态向动态演进。

北京大学团队提出DistDF损失函数,基于最优传输理论对齐预测与真实标签的联合分布,规避传统逐点损失中的独立性假设,实现无偏训练。该方法能有效捕捉序列整体形态与结构,兼容多种模型,在实验中展现出更优性能。
热门专题







热门推荐

英伟达Omniverse定位为物理AI操作系统。松应科技推出ORCALab1 0,旨在构建基于国产GPU的物理AI训练体系。针对机器人行业数据成本高、仿真迁移难的问题,平台提出“1:8:1黄金数据合成策略”,并通过高精度仿真提升数据可用性。平台将仿真与训练集成于个人设备,降低开发门槛,核心战略是在英伟达生态垄断下推动国产替。

Concordium是一个注重合规与隐私的区块链平台,其原生代币为CCD。该平台通过内置身份验证机制平衡隐私与监管要求,旨在服务企业级应用。CCD用于支付交易手续费、网络治理及生态内服务结算。其经济模型包含释放与销毁机制,以维持代币价值稳定。项目在合规金融、供应链、数字身份等领域有应用潜力。

上海人工智能实验室联合多家机构发起国产软硬件适配验证计划,致力于打造覆盖AI全流程的验证平台与自主生态社区。该平台旨在解决国产算力与应用协同难题,构建从芯片到应用的全链路验证体系,支持多种软硬件适配,推动国产AI技术向“好用、易用”发展。商汤科技依托AI大装置深度参与,已。

具身智能行业资本火热,但曾估值超200亿元的达闼科技迅速崩塌。其失败主因在于创始人黄晓庆以通信行业思维经营机器人业务,过度依赖政商关系与资本运作,技术产品突破有限;同时股权结构复杂分散,倚重政府基金,最终因融资断档与商业化不足导致团队离散。这折射出第一代创业者跨。

TurboQuant论文被质疑弱化与RaBitQ的关联,并存在理论比较与实验公平性问题。谷歌借助平台影响力将其定义为突破性成果,凸显了大厂在学术生态中的结构性优势。类似争议在伦理AI、芯片等领域亦有体现,反映了产业界将利益嵌入研究流程的机制。当前AI研究日益由大厂主导,其通过资本、渠道与话语权塑造。