上科大何旭明团队提出新方法 解决多模态模型简单样本偏置实现难题优先学习
多模态大模型的能力边界持续扩展,但一个长期存在的挑战依然突出:模型时常会产生看似合理实则错误的“幻觉”。面对信息不完整或语义模糊的输入,模型倾向于用猜测填补空白,从而虚构出图像中并不存在的物体、属性乃至情节。这并非偶然错误,而是当前主流训练范式下的一种结构性偏差——模型易于从海量清晰样本中学习,却对那些真正棘手、充满歧义的困难样本关注不足,导致其在复杂现实任务中的可靠性与事实准确性大打折扣。
如何有效抑制多模态模型的“幻觉”问题?上海科技大学何旭明教授团队的最新研究指出了一个关键方向:核心症结或许不在于数据总量不足,而在于数据难度分布不均。他们提出的DA-DPO(Difficulty-Aware Direct Preference Optimization)框架,通过引导模型在训练过程中动态聚焦于更易出错的困难样本,为降低多模态幻觉提供了一条高效且实用的新路径。

抑制幻觉,但不抑制能力
实验结果显示,DA-DPO方法在对抗多模态幻觉方面表现稳定且显著。更为可贵的是,它并未以牺牲模型的整体理解和推理能力为代价。
研究团队在多个权威评测基准上进行了全面验证,涵盖AMBER、MMHalBench等,涉及图像描述生成、视觉问答等多种任务。与传统优化方法相比,DA-DPO在降低幻觉率、提升输出的事实一致性方面优势明显。特别是在物体识别与描述层面,模型显著减少了“无中生有”的错误,在复杂场景或存在遮挡的情况下,对天马行空式回答的抑制效果尤为突出。
关键在于实现平衡。以往的一些去幻觉方法在压制错误信息的同时,往往也拖累了模型的综合性能。而在LLaVA-Bench、MME等评估综合能力的测试中,DA-DPO基本保持甚至提升了模型的通用性能,尤其是在需要多轮对话和复杂视觉推理的任务上,表现更为稳健。这表明,该方法并非通过让模型变得“保守”或“沉默”来规避错误,而是从优化机制本身入手,在输出的忠实性与模型的智能性之间找到了更优的平衡点。
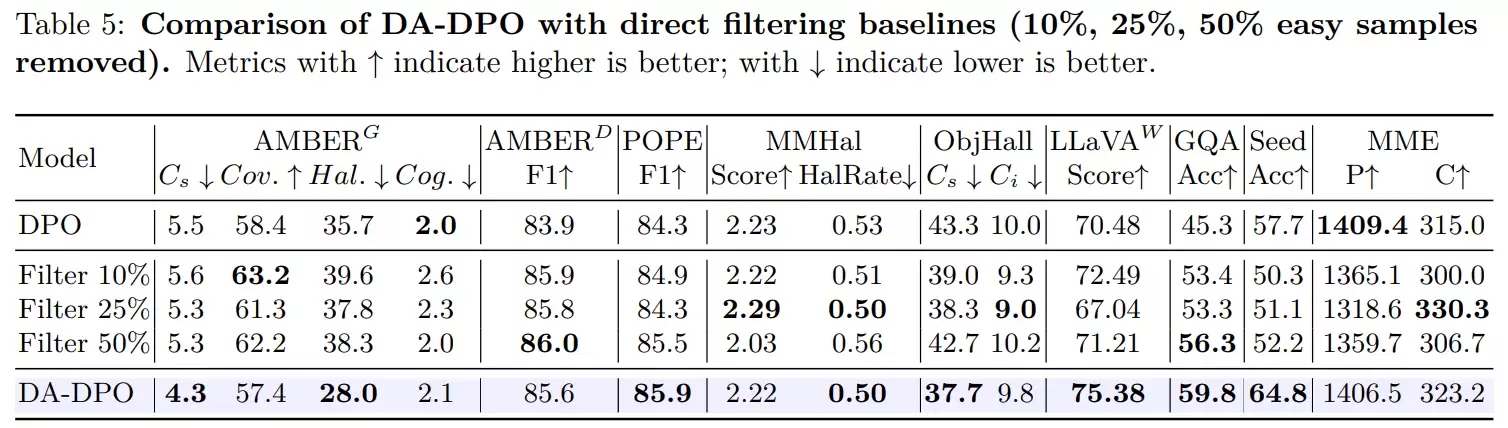
对训练过程的动态分析揭示了其背后的机理。研究人员将样本按难度分级后发现,在标准训练中,简单样本的“奖励”信号提升速度远快于困难样本,后期差距日益拉大。而DA-DPO的训练曲线则显示,困难样本的奖励增长更为显著,简单样本的增长则趋于平缓。量化指标清晰表明,DA-DPO有效缩小了难易样本间的奖励差距,确保训练重心向困难样本倾斜。这正是其能够精准抑制细粒度幻觉,同时保全模型整体能力的根本原因。
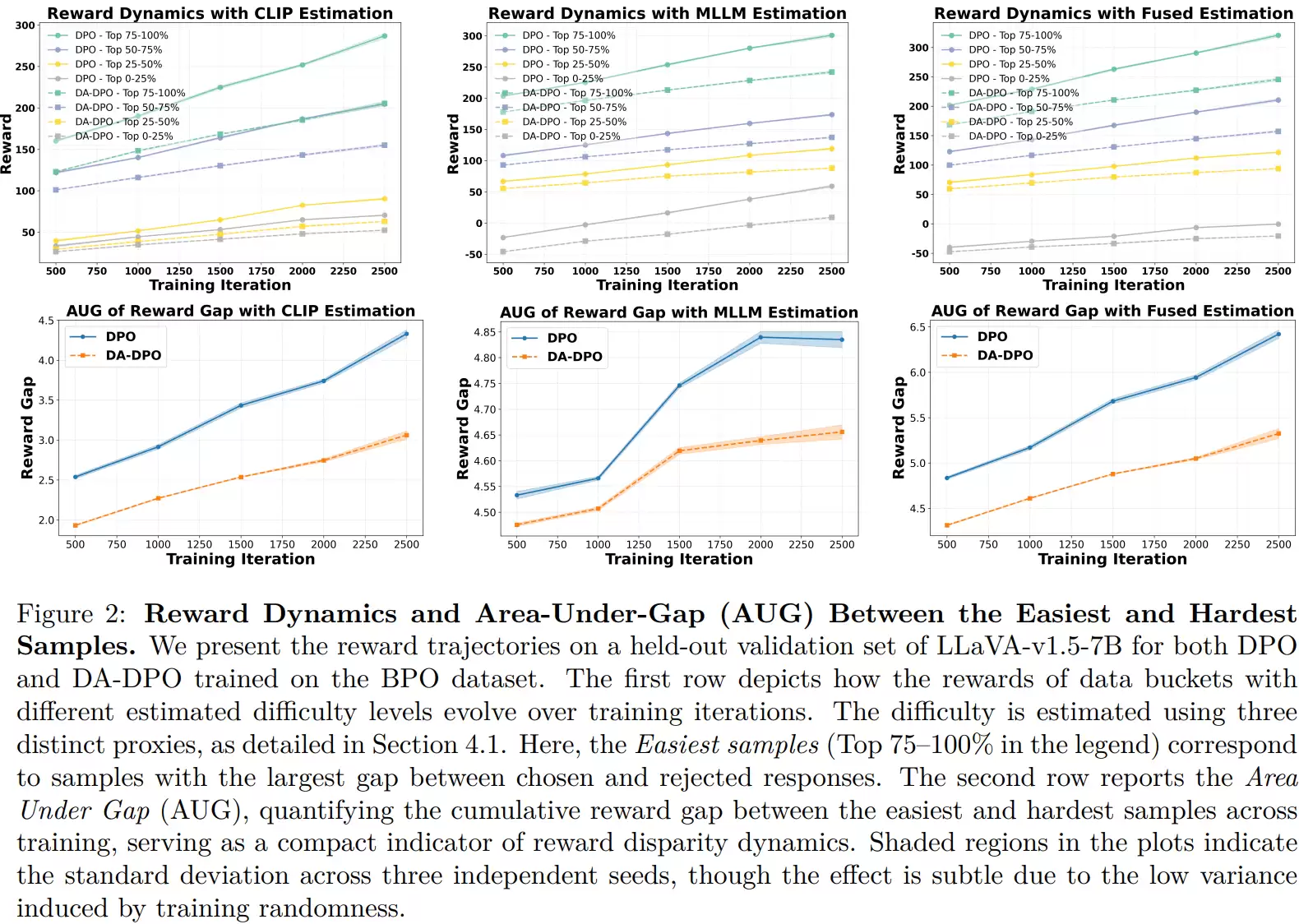
把权重交给难样本
整个实验设计围绕一个核心洞察展开:现有的多模态偏好对齐数据中,充斥着大量易于判断的简单样本对。传统训练方法会不自觉地“偷懒”,过度拟合这些简单部分,从而冷落了那些真正决定模型性能上限与鲁棒性的困难样本。
为了验证并解决这一问题,团队从模型选择、数据构建、评估策略到训练方法,进行了一系列环环相扣的系统性实验。

在模型选择上,他们使用了包括LLaVA在内的不同规模架构,以确保方法的普适性,而非针对特定模型的“特调”。
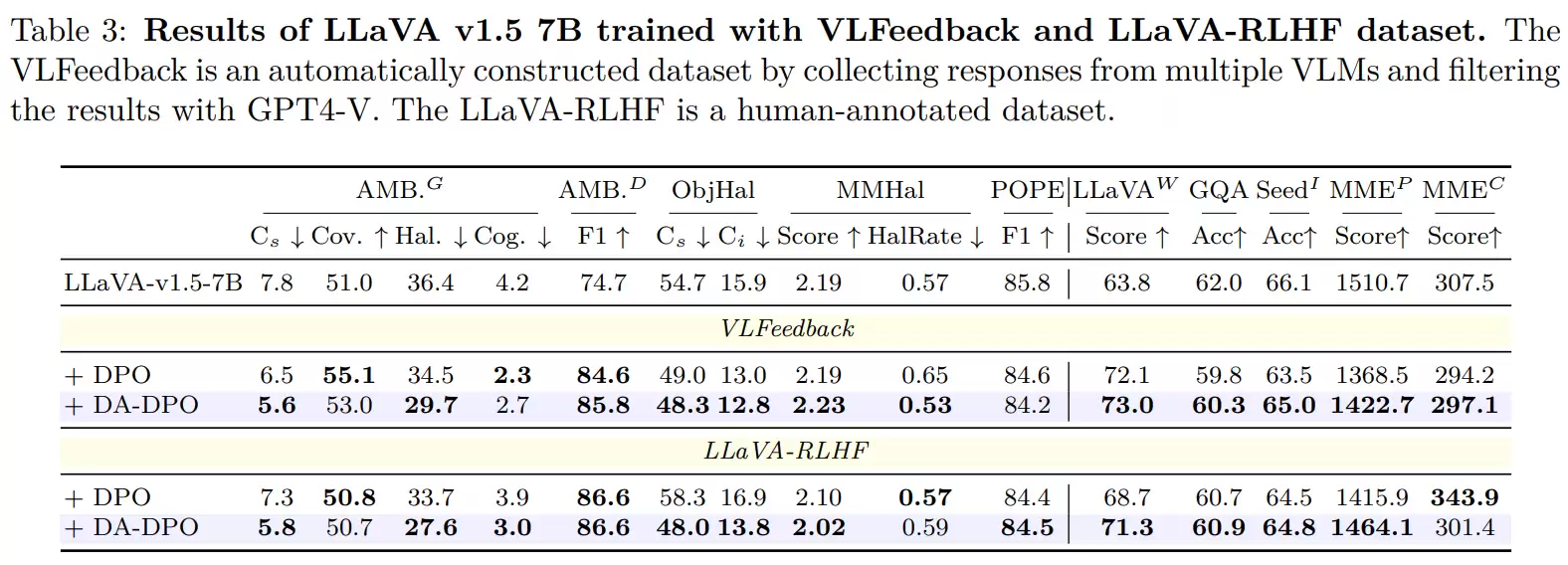
数据层面则融合了自动构造、模型筛选和人工标注三种不同来源的偏好数据。这旨在证明,样本难度分布失衡是各类多模态数据中的普遍现象,而非某个特定数据集的个性问题。
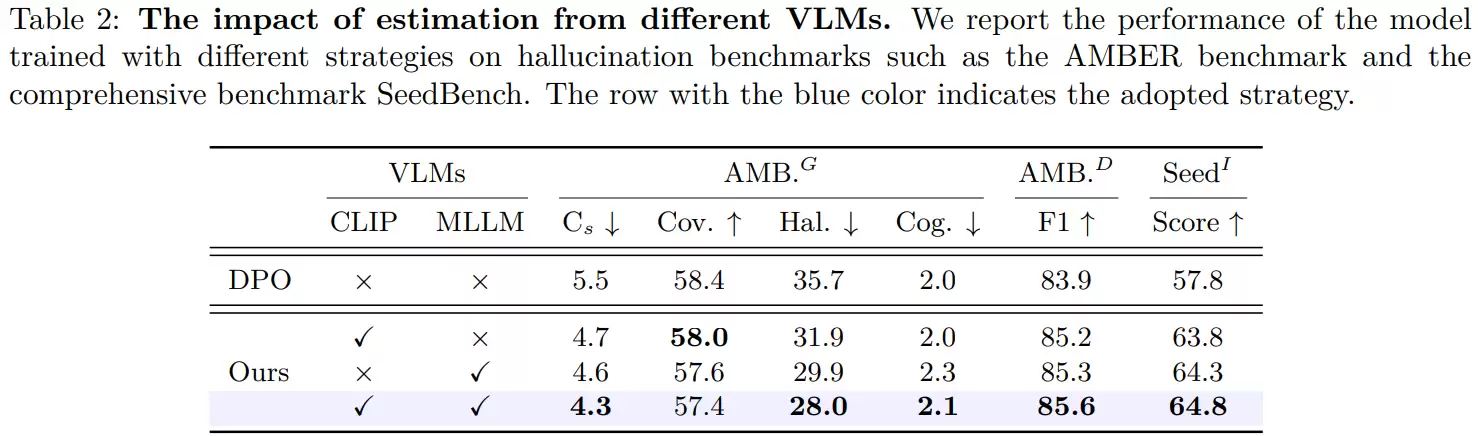
接下来的关键挑战是:如何在不显著增加额外计算成本的前提下,准确评估每个样本对的难度?研究团队巧妙地借用了两类现成的预训练模型进行评估:像CLIP这样的对比式模型,从图文相关性角度打分;像LLaVA这样的生成式模型,则从问答语义一致性角度衡量。通过计算偏好对中“好回答”与“坏回答”的得分差异,就能估计其区分难度:差值越小,意味着模型越难判断,样本就越“困难”。最后,融合两类模型的判断,形成更鲁棒、更全面的难度评分。
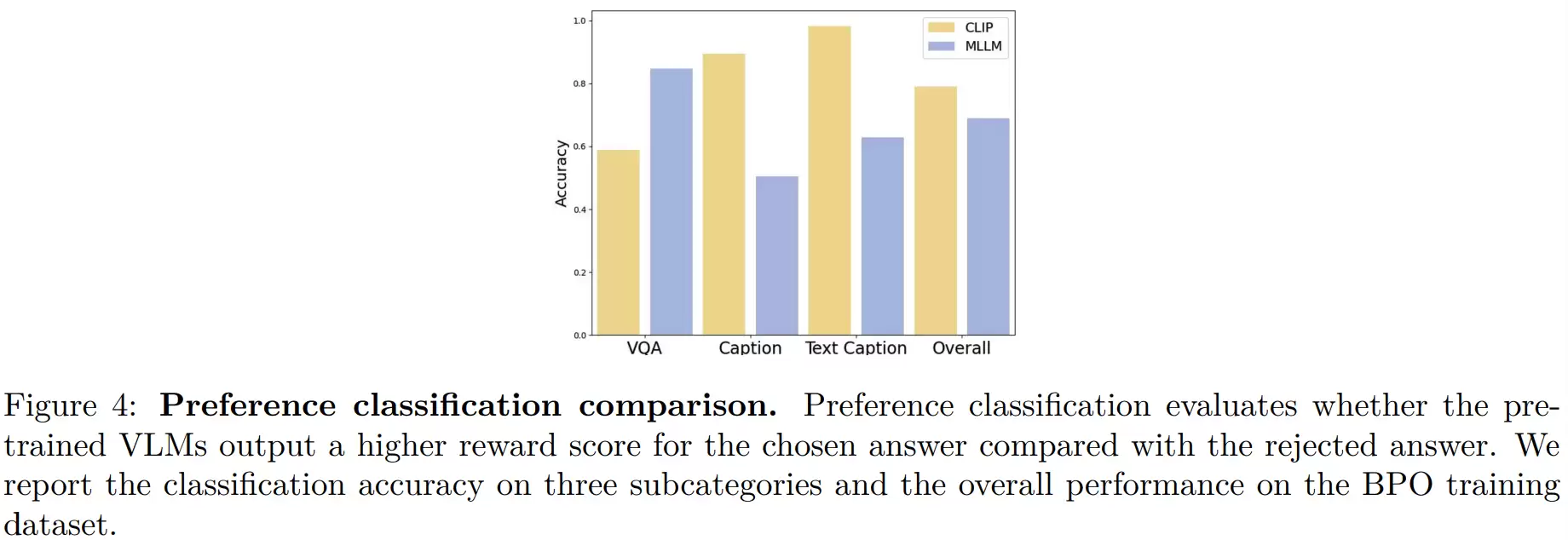
在训练阶段,这个动态的难度评分被引入到DPO框架的关键参数中,使其不再是固定值。于是,困难样本在训练损失中获得了更高的权重,简单样本的权重则被适当降低,从而引导模型集中精力攻克那些更难啃的“硬骨头”,优化学习重点。
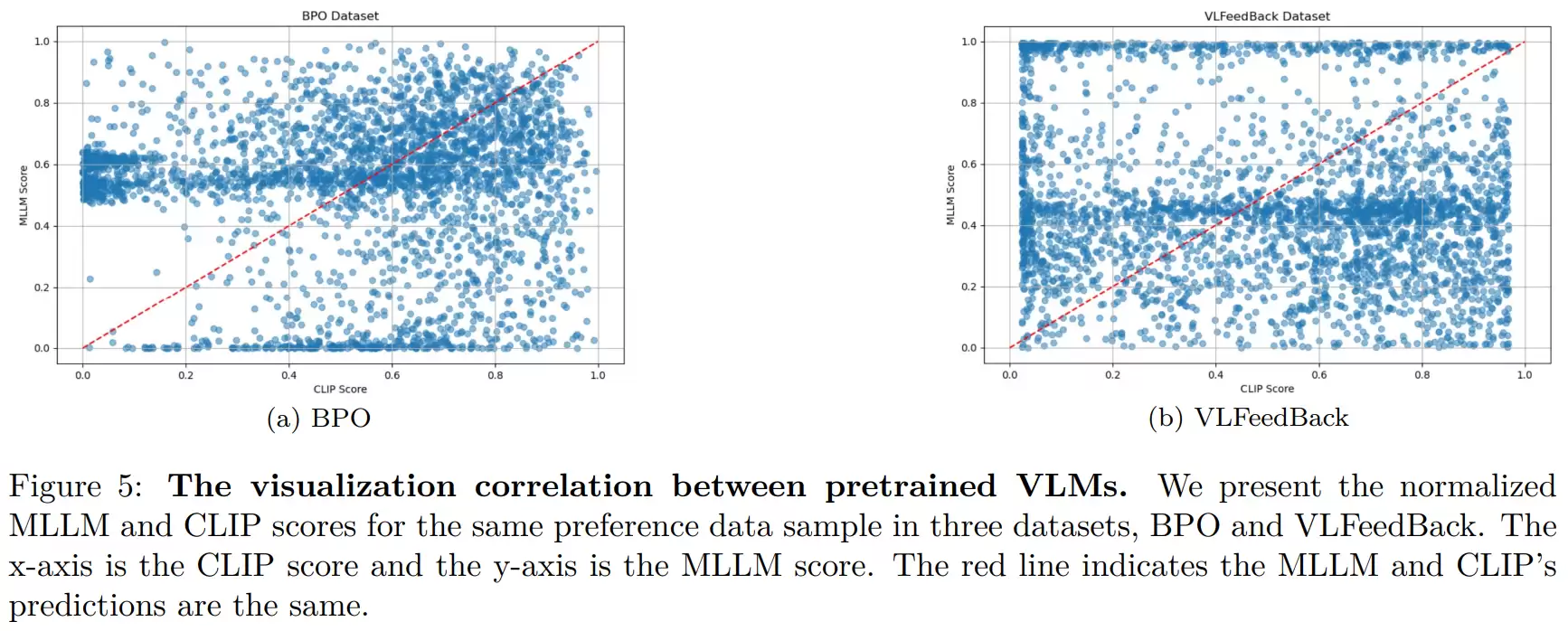
为了排除偶然性并验证各模块的有效性,大规模消融实验必不可少。例如,对比仅使用单一模型评估难度的效果,证明了融合策略的优越性;再如,与直接删除简单样本的“硬过滤”方法对比,发现那种粗暴方式会破坏数据多样性并导致性能波动,而DA-DPO的“软加权”策略则能带来更稳定的性能提升。
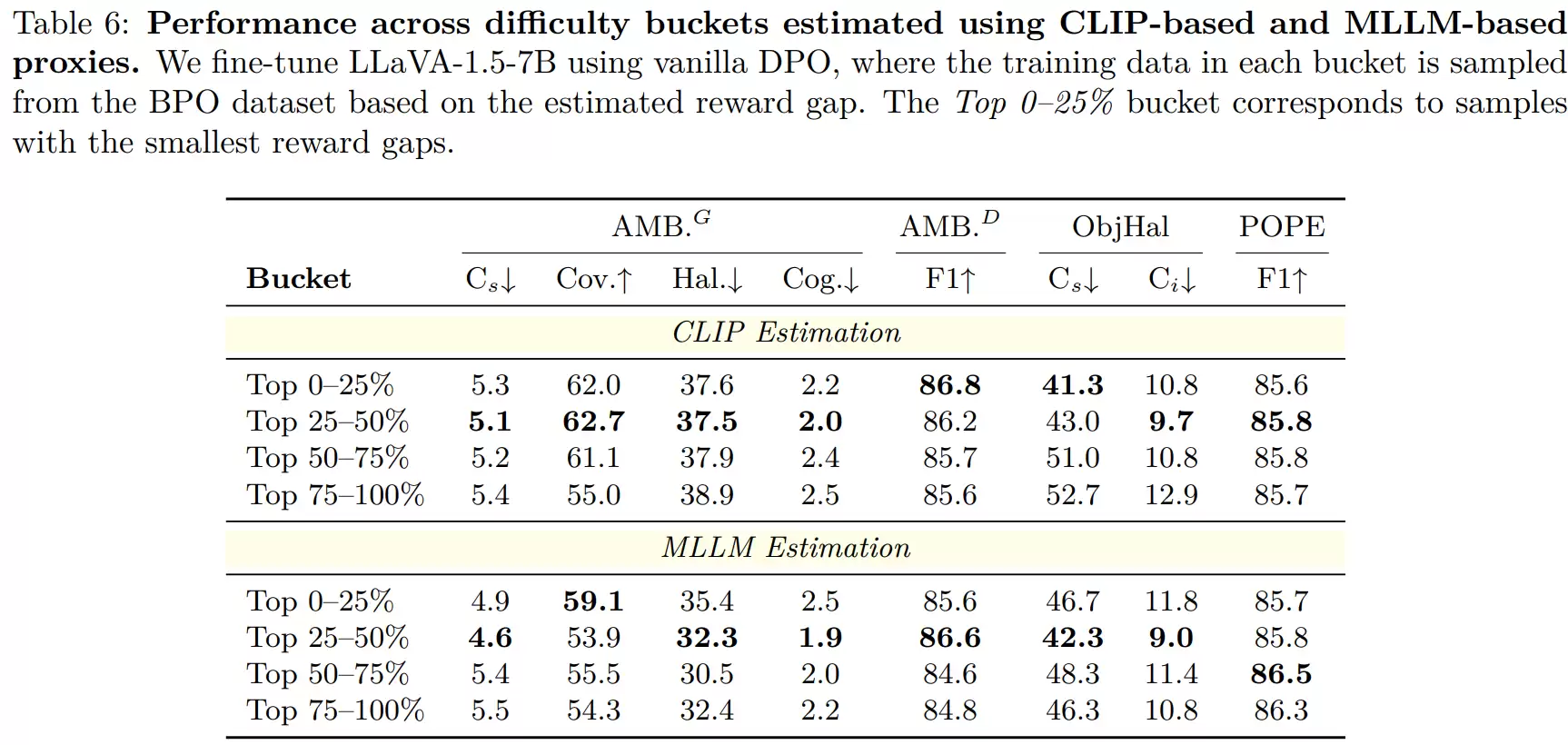
进一步的“难度分桶”实验还发现,当训练数据以中等难度样本为主时,幻觉抑制效果达到最佳。这强化了一个比单纯“堆砌数据量”更深刻的观点:训练样本难度结构的合理性,对于提升多模态模型性能至关重要。

从「数据更多」到「难度更准」
这项工作的价值,远不止于提出了一个有效的技术方法。
在理论层面,它通过系统性的分析,揭示了过去多模态偏好优化中一个被忽视的盲点:传统方法存在固有的“难度偏置”。模型倾向于学习区分度高的简单样本,而对那些语义复杂、区分细微、更贴近真实世界挑战的困难样本学习不足。这正是幻觉难以根除的深层原因之一。DA-DPO将样本难度显式地纳入优化目标,实质上重构了偏好对齐学习的视角,将焦点从“需要更多数据”转向了“需要更合理的数据难度分布”。这对后续研究方向,如自适应数据采样、困难样本挖掘等,都具有明确的启发性。
在工程实践上,DA-DPO的优势在于其“高性价比”。它不依赖昂贵的新增人工标注,无需额外训练独立的奖励模型,也避开了复杂的强化学习流程,仅仅通过利用现有模型评估难度并动态调整训练权重,就实现了性能的稳定提升。这种低成本、易集成、易部署的特性,使其在追求效率的工业级应用中颇具吸引力。
至于应用前景,则直接关乎AI系统的安全与可信赖性。无论是医疗影像分析中误报病灶,还是自动驾驶系统误判路况,多模态幻觉在关键领域可能造成严重后果。DA-DPO能在不显著削弱模型核心能力的前提下有效降低幻觉,无疑提升了模型在这些高风险场景中的可靠性。当然,该方法也有其局限,例如难度评估的准确性依赖于预训练模型本身的质量,在陌生或高度专业化的领域可能失准。未来的研究,可以朝着领域自适应的难度估计、更精细的难度度量等方向继续探索。
总而言之,这项研究不仅为抑制多模态幻觉提供了一条实用的技术路径,更贡献了一个可能影响未来多模态学习范式的核心观点:有时候,比数据“数量”更重要的,是数据“难度”的分布质量。
在多模态世界里寻找答案的人
这项研究的第一作者是上海科技大学信息科学与技术学院PLUS Group的硕士研究生Longtian Qiu,师从何旭明教授。他的研究兴趣集中在少样本学习、视觉—语言预训练等前沿方向。

文章的通讯作者是何旭明教授。他是上海科技大学信息科学与技术学院的副教授、博士生导师,并担任学院副院长。何教授于多伦多大学获得博士学位,曾在UCLA从事博士后研究,在澳大利亚国立大学等机构拥有丰富的研究经历。自2016年加入上海科技大学以来,他领导PLUS Lab团队在计算机视觉、机器学习与科学智能等领域持续深耕,特别是在开放世界理解、多模态大模型等挑战性课题上产出了一系列重要成果,发表了百余篇顶级会议与期刊论文,并获得了多项学术荣誉与教学奖项。

相关攻略

你是否好奇,游戏《GTA》中飞驰的汽车与现实中监控摄像头拍下的车辆,在人工智能的“视觉系统”里究竟有多大差别?尽管现代游戏画面已极为逼真,光影、材质与场景构建都栩栩如生,但对于自动驾驶、交通监控、智慧城市管理等需要落地应用的AI算法而言,虚拟游戏图像与真实世界照片之间,依然横亘着一道肉眼难以分辨、却

这项由香港大学、京东探索研究院、清华大学、北京大学和浙江大学联合完成的研究,以技术报告形式发布于2026年4月,论文编号为arXiv:2604 25427,有兴趣深入了解的读者可通过该编号查询完整原文。 你是否曾尝试用AI生成视频,却对结果感到失望?画面与描述不符、人物肢体扭曲、场景光影闪烁,最终视

2026年4月,一项由伦斯勒理工学院与亚利桑那州立大学联合开展的研究,在arXiv预印本平台发布(编号:arXiv:2604 24040v1),系统性地揭示并量化了AI表格检索领域一个长期存在的“盲点”——表格序列化格式对检索性能的巨大影响。 一、格式不同,AI就“认不出”同一张表格了? 设想一个典

腾讯混元团队提出新方法,使模型在推理时能根据输入动态生成参数,实现实时适配。实验表明,该方法在图像编辑任务中效果显著,能有效处理冲突需求,并在多项评测中领先,推动了智能模型从静态向动态演进。

北京大学团队提出DistDF损失函数,基于最优传输理论对齐预测与真实标签的联合分布,规避传统逐点损失中的独立性假设,实现无偏训练。该方法能有效捕捉序列整体形态与结构,兼容多种模型,在实验中展现出更优性能。
热门专题







热门推荐

知名制作人阿迪·尚卡尔透露,在卡普空发布新作后,他收到大量粉丝请求,希望将科幻游戏《识质存在》动画化。他认为该游戏因“不寻常且原创性十足”而备受关注。但目前他并无改编计划,而是选择专注于全新的原创项目,以探索更多叙事可能性。

《班迪与油印机》是一款融合平台跳跃与解谜的冒险游戏。攻略从基础操作讲起,详细介绍了前八关的核心玩法与技巧,包括利用特殊动作通过地形、应对各类机关与Boss战策略。游戏过程中可收集资源以升级能力,探索隐藏区域。其关卡设计富有创意,难度较高,但攻克后能获得显著成就感。

在《异环》游戏中,获取那台备受瞩目的AE86幽灵车外观,关键在于完成白杨的支线赛车挑战。许多玩家在此环节遇到困难,感觉对手速度难以超越。实际上,掌握正确技巧后,赢得比赛并不复杂。 异环白杨赛车任务通关技巧详解 获胜的核心策略可以总结为:把握弯道优势,主动实施碰撞。 白杨的车辆起步与直线加速性能确实出


心魔15层需冰抗180、火抗220以应对高额元素伤害,并把握BOSS施法前摇。16层需优先集火“魅惑魔灵”以防混乱,并稳妥处理高伤“穿刺者”。17层需兼顾元素区域走位与快速击破回血核心,考验团队输出与生存综合能力。这三层逐级挑战生存、节奏与整体实力。