浙大彭思达团队与理想汽车合作解决高分辨率深度估计细节缺失难题
在单目深度估计领域,追求更高的输出分辨率已成为主流趋势。目前,众多方法能够生成2K甚至4K的高分辨率深度图,表面上看,细节确实更加丰富。
然而,在实际的工业应用场景中,尤其是在三维重建、新视角合成这类对几何一致性要求极高的任务里,高分辨率深度图的表现有时并不理想。物体边缘容易模糊,细小结构常常错位,分辨率虽然提升了,但几何精度却没有同步提高。类似的问题在自动驾驶和机器人导航中同样关键——几何误差会直接影响对障碍物边界的精准判断和对可通行区域的可靠估计,进而威胁后续路径规划与决策的安全性。
问题的根源或许在于,当前大多数方法依然遵循着“在固定分辨率下预测,再进行插值放大”的传统路径。这种做法虽然能便捷地获得更大的图像尺寸,但对于细节区域而言,本质上只是放大了原有的预测误差。对于依赖深度信息进行环境感知与建模的系统来说,这种误差不仅影响局部三维模型的质量,更会动摇整个感知与决策链条的稳定性。因此,业界开始深入思考:高分辨率深度估计的瓶颈,或许不在于模型架构不够复杂,而在于深度信息的表示方式本身存在根本性的局限。
正是基于这一深刻洞察,浙江大学彭思达团队与理想研究团队合作,提出了名为《InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields》的创新研究。这项工作的核心并非在现有框架上追求更高的评测指标,而是回归问题本质,重新思考在高分辨率条件下,深度信息应该如何被更有效、更本质地建模与利用。
为了系统验证新范式的有效性,研究团队设计了一系列覆盖合成数据、真实数据以及三维下游任务的严谨实验,旨在从多维度、精细化地评估新方法在复杂几何结构与细节区域的实际性能表现。

论文地址:https://arxiv.org/pdf/2601.03252
当深度不再受分辨率限制
研究团队通过一系列覆盖合成数据、真实数据以及下游三维任务的系统性实验,全面验证了InfiniDepth在高分辨率深度估计、细粒度几何建模以及大视角渲染方面的卓越性能。
首先,在团队专门构建的Synth4K高分辨率基准数据集上,进行了零样本相对深度评估。Synth4K包含五个来自不同高质量游戏场景的子集,每个子集都提供了数百张分辨率为3840×2160的RGB图像及对应的高精度深度图,能够真实反映4K分辨率下物体边缘、薄壁结构和复杂曲面的精细几何细节。
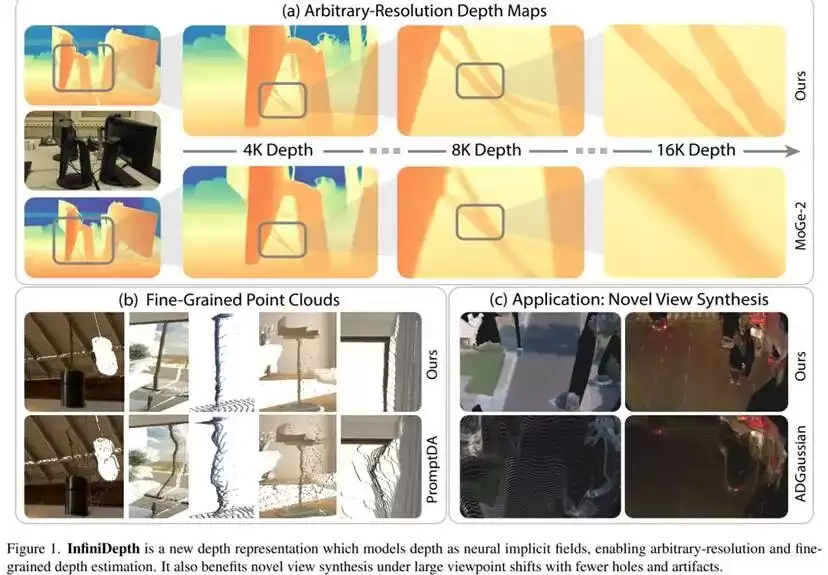
评估同时关注全图区域和高频细节区域,并采用δ0.5、δ1和δ2作为核心指标。在全图范围内,InfiniDepth在五个子集上均表现最佳。例如,在Synth4K-1上,其δ1指标达到89.0%,明显高于DepthAnything的83.8%和MoGe-2的84.2%;在Synth4K-3上,δ1进一步提升至93.9%,相比DepthPro和Marigold等方法优势显著;在Synth4K-5上,其δ1达到96.3%,在所有对比方法中位列第一。这些结果充分说明,该方法在高分辨率条件下具备稳定且一致的整体精度优势。
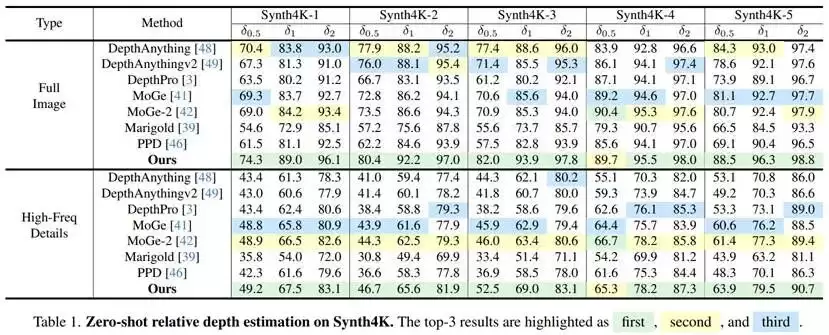
进一步聚焦于高频细节区域(通过多尺度拉普拉斯算子筛选出的几何变化剧烈区域)时,所有方法的性能都有所下降,但InfiniDepth的下降幅度最小,且在多数子集上保持领先。例如,在Synth4K-1的高频区域,其δ1为67.5%,而DepthAnything和DepthAnythingV2分别仅为61.3%和60.6%;在Synth4K-3的高频区域,InfiniDepth的δ1为69.0%,相比MoGe-2的63.4%提升明显。整体来看,InfiniDepth在高频区域的δ1指标通常比主流方法高出约5到8个百分点,这有力证明了其在边缘、薄结构和局部几何突变区域拥有更强的细节恢复与表达能力。
值得注意的是,这类高频细节并非合成数据独有,在真实世界的复杂场景中同样普遍存在。例如在自动驾驶环境中,路缘石、护栏、交通标志杆等关键道路元素往往具有细长、边界清晰且几何变化明显的特点,其深度估计的准确性直接关系到车辆对道路结构和可行驶空间的精确理解。因此,在这些区域保持稳定的几何表达能力,对于提升复杂道路环境下的感知可靠性具有至关重要的现实意义。
研究团队特别强调,这种性能差异并非源于后处理技巧。对于Synth4K的4K输出,大多数对比方法需要先在较低分辨率下预测深度,再通过插值上采样到4K;而InfiniDepth由于采用了连续的神经隐式深度表示,可以直接在任意4K坐标位置预测深度值。因此,其在高分辨率评估中的优势反映的是模型原生的、不受限制的分辨率扩展能力。
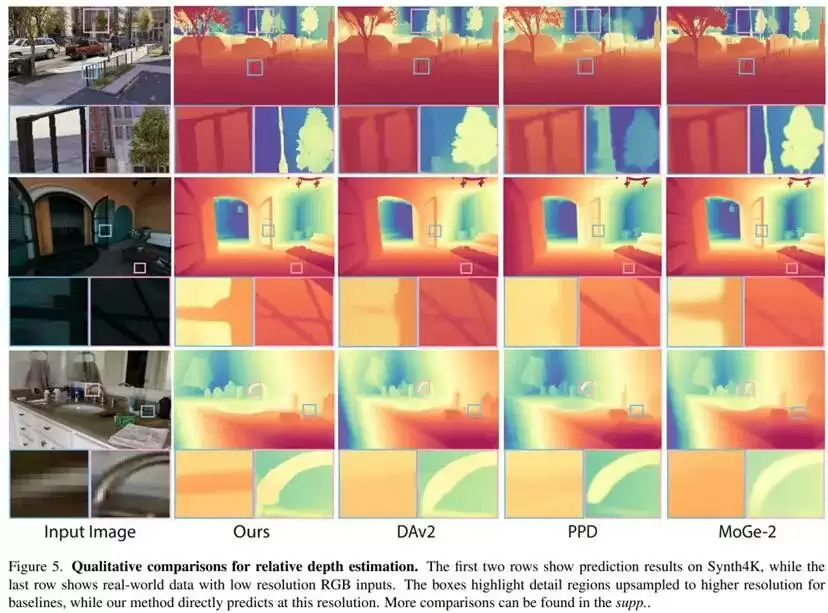
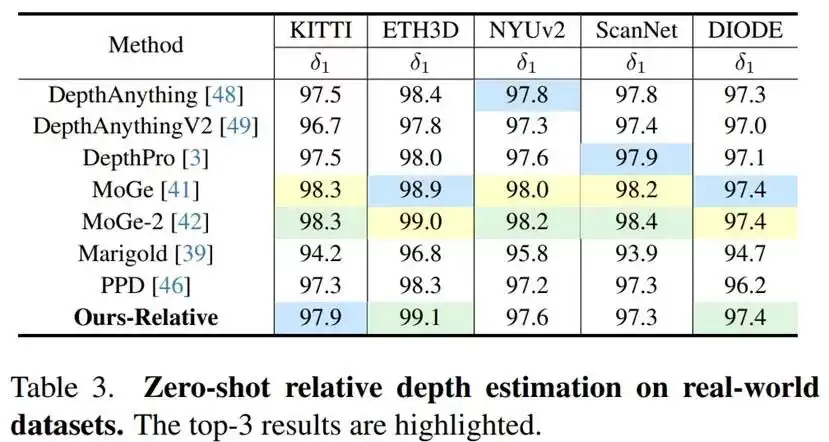
在真实世界数据集(KITTI、ETH3D、NYUv2、ScanNet和DIODE)上的零样本相对深度评估中,InfiniDepth的表现与当前主流方法整体处于同一水平,甚至略有优势。例如,在ETH3D上,其δ1达到99.1%,略高于MoGe-2的99.0%;在KITTI上,δ1为97.9%,与DepthPro和MoGe等方法基本持平;在NYUv2和ScanNet上,也未出现明显性能退化。这些结果说明,即便模型仅使用合成数据训练,其连续深度表示并未损害对真实数据的泛化能力。这种对训练数据分布变化不敏感的特性,在自动驾驶和移动机器人等实际部署场景中至关重要,因为真实环境往往与训练条件存在较大差异,对感知系统的鲁棒性与稳定性要求极高。
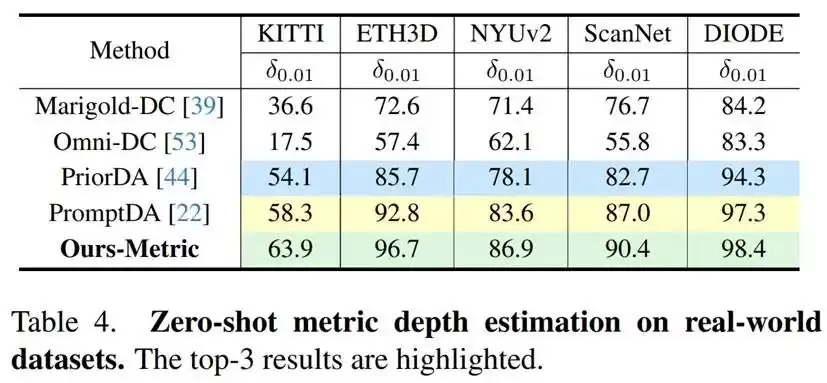
在尺度深度估计实验中,研究团队将InfiniDepth与稀疏深度提示机制结合,并在Synth4K以及真实数据集上采用了更严格的δ0.01、δ0.02和δ0.04指标进行评估。在Synth4K的全图区域,InfiniDepth-Metric在Synth4K-1上的δ0.01达到78.0%,相比PromptDA的65.0%提升显著;在Synth4K-3上,其δ0.01达到83.8%,同样领先于所有对比方法。在高频细节区域,这一优势更加突出,例如在Synth4K-3的高频区域,InfiniDepth-Metric的δ0.01为37.2%,而PromptDA仅为24.7%,PriorDA和Omni-DC的表现更低。这表明,在细节区域和高精度尺度估计任务中,连续深度表示能够带来更显著的收益。
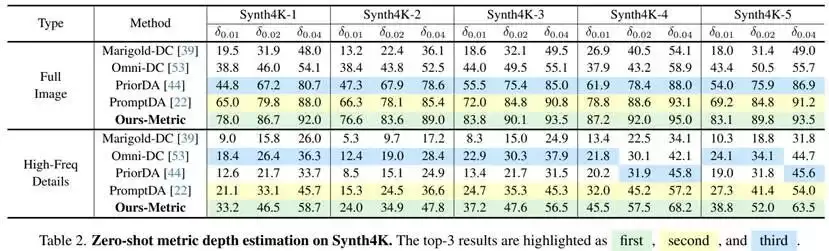
在真实数据集的尺度深度评估中,也观察到了一致的趋势。在KITTI和ETH3D上,InfiniDepth-Metric的δ0.01指标分别达到63.9%和96.7%,均优于现有方法;在DIODE数据集上,其δ0.01达到98.4%,在对比方法中排名第一。这说明该方法在引入稀疏深度约束后,能够在真实场景中实现高精度且稳定的尺度深度预测,为三维重建等应用提供了可靠的度量信息。
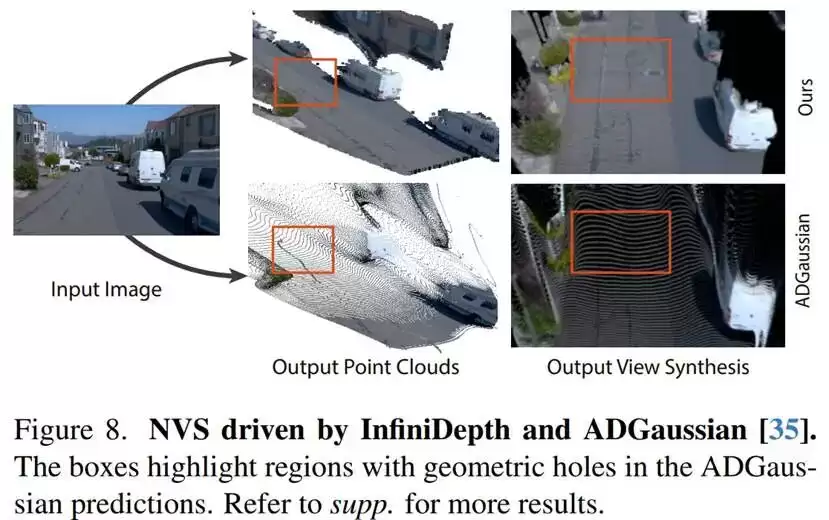
此外,在单视图新视角合成实验中,研究团队将InfiniDepth预测的深度用于构建三维点云并驱动高斯溅射渲染。实验结果表明,相比采用传统像素对齐深度的方法,在大视角变化条件下,基于该方法构建的点云分布更加均匀,生成的新视角图像中几何空洞和断裂明显减少,整体结构更加完整。这说明连续深度表示能够为三维建模提供更加稳定和一致的几何基础,有效缓解了因离散采样导致的表面不连续问题。
这种更可靠的三维几何结构不仅有利于视觉重建和渲染任务,在自动驾驶和机器人系统中同样具有深远的现实意义。更准确、一致的空间几何信息有助于系统对周围环境形成更清晰、更完整的空间认知地图,从而为后续的实时导航、避障规划与安全决策提供更加稳定和可信的感知支撑。
把深度放进三维里再看一次
上述一系列优异的实验结果,源于研究团队围绕一个核心科学问题所设计的系统性实验验证:“深度表示方式本身,是否成为制约分辨率无限扩展与几何细节恢复能力的关键瓶颈?”
研究人员指出,现有单目深度估计方法普遍在固定的像素网格上进行离散预测,输出分辨率与训练分辨率强相关,高分辨率结果通常依赖插值或上采样,这不可避免地会平滑并损失高频几何信息。为了验证问题是否源于表示方式,团队创新性地提出将深度建模为连续空间中的映射关系,使模型能够在任意图像坐标位置直接、连续地预测深度值,从而从根本上摆脱了固定分辨率的束缚。
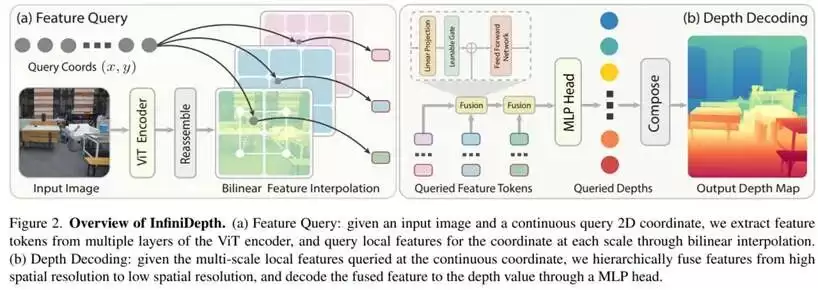
在数据设计上,为了避免真实数据集中深度标注稀疏、分辨率有限和噪声较大的问题干扰实验结论,研究人员精心构建了Synth4K高分辨率合成数据集,并进一步引入高频细节掩码,通过多尺度拉普拉斯能量筛选出几何变化最剧烈的区域,从而实现对模型细节恢复能力的精细化定量评估。
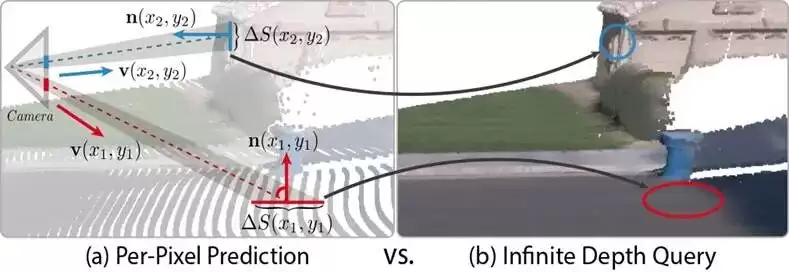
在实验设置上,所有对比方法均使用相同分辨率的输入图像,并在评估阶段统一对齐尺度;对于4K输出,基线方法的结果通过上采样获得,而InfiniDepth直接在4K网格坐标位置进行深度预测,以确保对比实验公平且聚焦于深度表示和解码方式的本质差异。在训练阶段,研究人员并未对整张深度图进行逐像素监督,而是随机采样大量坐标及其对应的深度值进行训练,这一策略既符合连续深度建模的设定,也使高分辨率监督更加灵活高效。

为了验证各个模块的贡献,研究团队进一步设计了系统的消融实验。当移除连续深度表示、回退到传统的离散网格预测方式时,模型在Synth4K和真实数据集上的高精度指标普遍下降8到12个百分点;当去除多尺度局部特征查询与融合机制时,模型在细节区域的性能同样出现一致性退化。这些结果从定量角度有力证明,连续表示和多尺度局部查询是InfiniDepth性能提升的关键因素。

在新视角合成相关实验中,研究人员进一步分析了像素对齐深度在三维反投影过程中导致点云密度不均的问题,并基于连续深度表示所支持的几何分析能力,根据不同区域对应的表面覆盖情况自适应分配采样密度,从而在三维空间中生成更加均匀的表面点分布。实验结果表明,这一策略在大视角变化条件下能够有效减少孔洞和几何断裂,提升渲染质量。

不同场景下的一致性结论
综合上述实验可以看出,InfiniDepth的研究意义不仅体现在指标提升上,更在于研究团队通过多数据集、多指标和多任务的定量实验,清晰地表明:高分辨率深度估计中几何细节恢复能力的主要瓶颈,确实来源于深度表示方式本身。在Synth4K这一高分辨率基准上,高频细节区域普遍达到5至10个百分点的性能提升,直接说明了依赖插值的高分辨率预测在几何建模上的局限性。
同时,真实数据集上的零样本评估结果表明,连续深度表示并未削弱模型的泛化能力,展现了良好的跨域适应性。而在引入稀疏深度约束后,其在高精度尺度深度估计中的优势进一步放大。结合新视角合成实验可以看到,这种表示方式不仅提升了二维深度图在细节上的一致性,也为三维点云构建和渲染提供了更加稳定的几何基础。
在此基础上,这类连续深度表示所带来的稳定几何结构,使得深度信息能够更自然、更有效地被用于后续的三维建模与环境理解。在自动驾驶和机器人系统中,这种高分辨率、高一致性且可任意分辨率的深度感知,有助于显著提升复杂动态场景下空间建模和导航决策的可靠性与安全性。
总体而言,研究团队通过在高分辨率合成数据、真实世界数据以及下游三维任务上的系统实验,用具体数据和指标证明了连续隐式深度表示在分辨率扩展性、几何细节恢复能力以及大视角渲染方面的综合优势,为单目深度估计的后续研究提供了清晰且可验证的新方向。
研究背后的工作者
本论文的通讯作者彭思达,现任浙江大学软件学院研究员。他于2023年在浙江大学计算机科学与技术学院获得博士学位,师从周晓巍教授和鲍虎军教授,本科毕业于浙江大学信息工程专业。
彭思达研究员在三维视觉、神经隐式表示以及深度感知等研究方向上具有扎实的研究积累和持续的学术贡献,已在CVPR、ICCV、ECCV、NeurIPS、TPAMI等国际顶级会议和期刊上发表多篇高水平论文,并在多项学术评选中获得重要荣誉,包括2025 China3DV年度杰出青年学者奖和2024 CCF优秀博士论文奖。
此外,他在GitHub上分享的个人科研经验与学习资料获得了广泛关注。其研究兴趣从神经隐式深度估计进一步拓展至动态场景建模、空间智能体训练以及大规模三维重建等前沿方向,强调解决具有实际应用价值且尚未充分解决的核心问题,致力于推动三维视觉新技术在真实行业场景中的落地与产生广泛影响。

参考链接:https://pengsida.net/
相关攻略

你是否好奇,游戏《GTA》中飞驰的汽车与现实中监控摄像头拍下的车辆,在人工智能的“视觉系统”里究竟有多大差别?尽管现代游戏画面已极为逼真,光影、材质与场景构建都栩栩如生,但对于自动驾驶、交通监控、智慧城市管理等需要落地应用的AI算法而言,虚拟游戏图像与真实世界照片之间,依然横亘着一道肉眼难以分辨、却

这项由香港大学、京东探索研究院、清华大学、北京大学和浙江大学联合完成的研究,以技术报告形式发布于2026年4月,论文编号为arXiv:2604 25427,有兴趣深入了解的读者可通过该编号查询完整原文。 你是否曾尝试用AI生成视频,却对结果感到失望?画面与描述不符、人物肢体扭曲、场景光影闪烁,最终视

2026年4月,一项由伦斯勒理工学院与亚利桑那州立大学联合开展的研究,在arXiv预印本平台发布(编号:arXiv:2604 24040v1),系统性地揭示并量化了AI表格检索领域一个长期存在的“盲点”——表格序列化格式对检索性能的巨大影响。 一、格式不同,AI就“认不出”同一张表格了? 设想一个典

腾讯混元团队提出新方法,使模型在推理时能根据输入动态生成参数,实现实时适配。实验表明,该方法在图像编辑任务中效果显著,能有效处理冲突需求,并在多项评测中领先,推动了智能模型从静态向动态演进。

北京大学团队提出DistDF损失函数,基于最优传输理论对齐预测与真实标签的联合分布,规避传统逐点损失中的独立性假设,实现无偏训练。该方法能有效捕捉序列整体形态与结构,兼容多种模型,在实验中展现出更优性能。
热门专题







热门推荐

知名制作人阿迪·尚卡尔透露,在卡普空发布新作后,他收到大量粉丝请求,希望将科幻游戏《识质存在》动画化。他认为该游戏因“不寻常且原创性十足”而备受关注。但目前他并无改编计划,而是选择专注于全新的原创项目,以探索更多叙事可能性。

《班迪与油印机》是一款融合平台跳跃与解谜的冒险游戏。攻略从基础操作讲起,详细介绍了前八关的核心玩法与技巧,包括利用特殊动作通过地形、应对各类机关与Boss战策略。游戏过程中可收集资源以升级能力,探索隐藏区域。其关卡设计富有创意,难度较高,但攻克后能获得显著成就感。

在《异环》游戏中,获取那台备受瞩目的AE86幽灵车外观,关键在于完成白杨的支线赛车挑战。许多玩家在此环节遇到困难,感觉对手速度难以超越。实际上,掌握正确技巧后,赢得比赛并不复杂。 异环白杨赛车任务通关技巧详解 获胜的核心策略可以总结为:把握弯道优势,主动实施碰撞。 白杨的车辆起步与直线加速性能确实出


心魔15层需冰抗180、火抗220以应对高额元素伤害,并把握BOSS施法前摇。16层需优先集火“魅惑魔灵”以防混乱,并稳妥处理高伤“穿刺者”。17层需兼顾元素区域走位与快速击破回血核心,考验团队输出与生存综合能力。这三层逐级挑战生存、节奏与整体实力。