在智能语音交互日益普及的今天,语音识别技术的准确率依然是决定用户体验的关键。无论是智能家居控制、会议内容实时转写,还是车载语音助手,识别错误都会直接影响使用效率。那么,如何系统性提升语音识别的精准度?这背后是一系列核心技术协同作用的结果。

精准识别的第一步是信号预处理。原始音频通常包含环境杂音、设备电流声等干扰,直接分析必然影响效果。这就如同在喧闹的街道中听清对话,必须首先过滤背景噪音。因此,通过降噪、滤波等技术对音频进行“净化”与标准化处理,是为后续步骤奠定清晰基础的必要环节。

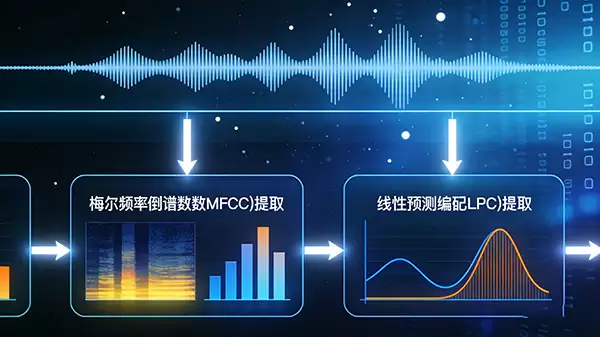
经过清洁的音频信号,需要转化为机器可解读的数字特征。特征提取技术在此至关重要。人耳能直观感知音色与语调,而机器则需要梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等特征参数来捕捉声音的本质内容。这些技术能有效剥离说话人的个人音色,聚焦于语音所携带的文字信息本身。
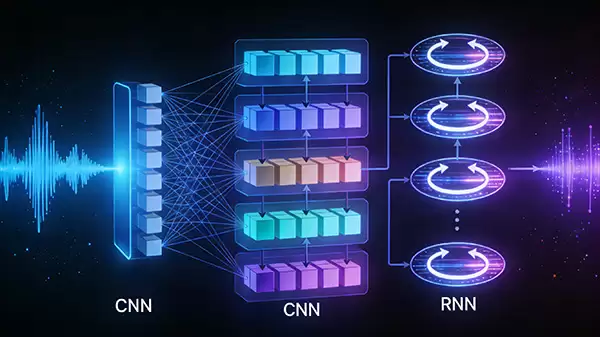
获取高质量特征后,需要强大的模型进行模式学习。基于深度学习的声学模型,如卷积神经网络(CNN)和长短时记忆网络(LSTM),已成为提升识别率的核心。它们能够从海量的语音数据中自动学习语音与文本之间的复杂对应关系,无需依赖大量人工规则,从而显著提高识别准确率与鲁棒性。
数据是训练优质模型的基石。语音识别系统的泛化能力,直接取决于训练数据的规模与多样性。收集涵盖不同口音、语速、年龄及噪声场景的高质量语音数据,是让模型应对真实复杂环境的最有效方法。数据越丰富,模型见过的“案例”越多,其实际表现就越稳定可靠。
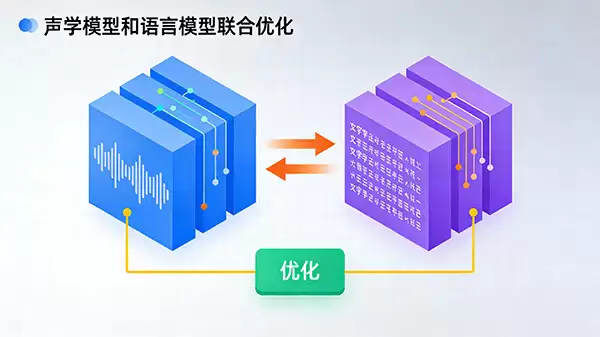
然而,仅靠声学模型并不足够,还需理解语言的上下文与常识。这就是语言模型的价值所在。它通过学习海量文本数据掌握语法规则与词频统计,能够判断“打开空调”比“打开空跳”更合理。当声学模型输出多个候选文本时,语言模型扮演着最终的语法校对者,有效纠正同音字或不合逻辑的识别错误。
更先进的方案是采用端到端语音识别技术,将声学模型与语言模型进行一体化联合训练与优化。这种方法让整个系统以最终的识别准确率为统一目标进行调校,避免了传统流水线中各模块优化目标不一致的问题,从而获得更强的整体性能和抗干扰能力。
面对持续变化的噪声环境,主动的语音增强算法能实时提升信噪比。例如,自适应噪声抑制可以动态追踪并消除背景音;回声消除技术则能有效防止扬声器输出被麦克风再次收录。这些技术如同为设备配备了“智能降噪麦克风”,从源头改善输入音频质量。
实际口语中存在大量连读、吞音和方言表达,这对识别构成巨大挑战。口语规范化处理旨在将这些非标准发音转化为标准文本形式,例如将“咋整”转化为“怎么办”,从而更好地匹配语言模型的知识库,提升对话场景下的识别准确率。
硬件设计同样能提供助力。采用多麦克风阵列进行拾音,结合波束成形技术,可以精准聚焦目标说话人方向,抑制其他方向的干扰。这在多人会议、远场语音交互等场景中,能显著提升语音唤醒和识别效果。
一个优秀的语音识别系统应具备持续进化能力。通过在线学习或增量学习技术,系统可以在实际部署后,安全地利用匿名化的新数据不断微调模型,适应新词汇、新口音或新的表达习惯,从而实现长期的性能提升与适应性维护。
综上所述,提升语音识别准确率是一项多维度的系统工程。从信号预处理、特征提取,到深度学习建模与大数据训练,再到语言模型纠错与端到端优化,辅以语音增强、口语规范化、麦克风阵列等增强技术,并通过持续学习实现迭代升级——这些方法共同构成了现代高精度语音识别解决方案。在实际应用中,需根据具体场景、资源与性能要求,灵活配置与整合这些技术模块,方能打造出真正可靠、智能的语音交互产品。




