语音识别的两大基石:语言模型与声学模型
要让机器听懂人话,其背后的核心引擎主要建立在两大模型之上:语言模型和声学模型。
简单来说,语言模型负责处理语言本身的逻辑。它的核心任务是预测某个词或一连串词语出现的可能性有多大。这就像我们在听别人说话时,即使偶尔听不清某个词,也能根据上下文猜到大概意思,语言模型赋予机器的正是这种“语言预感”。而声学模型则负责处理声音信号。它需要计算,当我们说出一个词W时,产生特定声学特征X的概率是多少,也就是把原始的音频“翻译”成可能的发音单元。

千万别小看声学模型,它堪称整个语音识别系统最底层、也最关键的一环。这个模型的好坏,直接决定了识别系统的准确度和在不同环境下的稳定表现。其工作原理,是用概率统计的方法,为语音中最基本的发音单元建立数学模型,描绘出它们的统计特性。这么做的目的非常明确:它能有效地衡量一段语音的特征矢量序列和每一个发音“模板”之间的相似度。说得更直白些,声学模型就是一套精密的“听音辨字”系统,专门用来判断这段声音信号到底对应了什么内容。
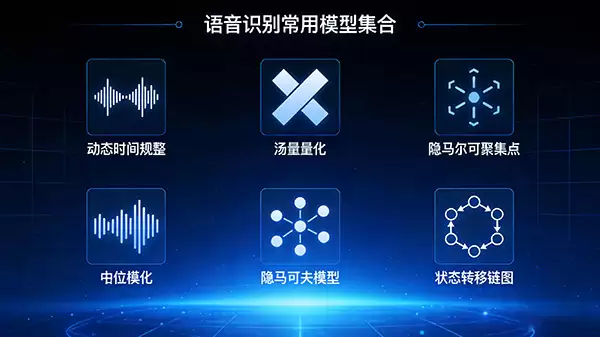
当然了,语音识别技术发展到今天,工具箱里的模型远不止这两个。为了应对语音信号千变万化的时长和模式,工程师们引入了像动态时间规整这样的技术。在面对海量声音数据时,矢量量化技术则能高效地进行压缩和分类。而在众多模型中,隐马尔可夫模型的地位尤为突出。
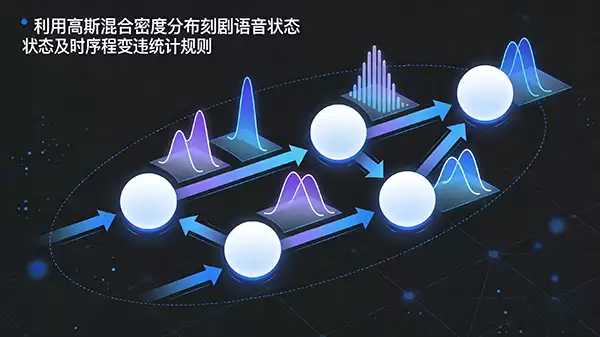
隐马尔可夫模型之所以重要,是因为它巧妙地刻画了语音的两个核心规律。一方面,它用高斯混合密度分布来描述每个语音状态(比如一个音素)的声学特征;另一方面,它又模拟了这些状态之间随时间转换的统计规律。这种既能处理静态特征又能处理动态时序的能力,让它成为了构建现代声学模型的基石之一。
正是这些模型和技术的协同工作与不断进化,才使得今天的语音识别系统能够越来越精准地理解我们的话语,让人与机器之间的对话,变得更加自然流畅。




