在实时对话、人机交互等对AI响应速度要求极高的应用场景中,大语言模型的推理延迟哪怕只减少几毫秒,用户体验都可能产生质的飞跃。近期,斯坦福大学Hazy Research团队取得了一项突破性优化成果,将开源小模型Llama-3.2-1B的前向推理延迟推向了新的极限——他们通过将所有计算融合进一个名为“Megakernel”的单一CUDA核心中,实现了接近硬件理论极限的极致性能。
这项研究的动机非常明确:团队发现,当前主流的AI推理引擎在处理极低延迟的单序列生成任务时,效率并不理想。即使在H100这样的顶级GPU上,像vLLM、SGLang这样的先进系统,其显存带宽利用率也常常低于50%。瓶颈究竟在哪里?问题并非出在计算能力上,而在于“等待”造成的资源闲置。
传统方法通常将Transformer模型的每一层分解为几十甚至上百个细小的CUDA内核,分别处理RMSNorm、注意力机制、MLP等操作。这种“微内核”架构虽然模块化清晰,却引入了大量的上下文切换和内核启动开销。更重要的是,在生成单个token的短时任务中,这些内核必须排队执行,后续计算无法提前预加载数据,导致GPU对显存的访问断断续续。大量时间被耗费在“空转”和“等待指令”上,而非用于实际运算,严重拖累了整体效率。
Megakernel:从零设计的深度融合方案
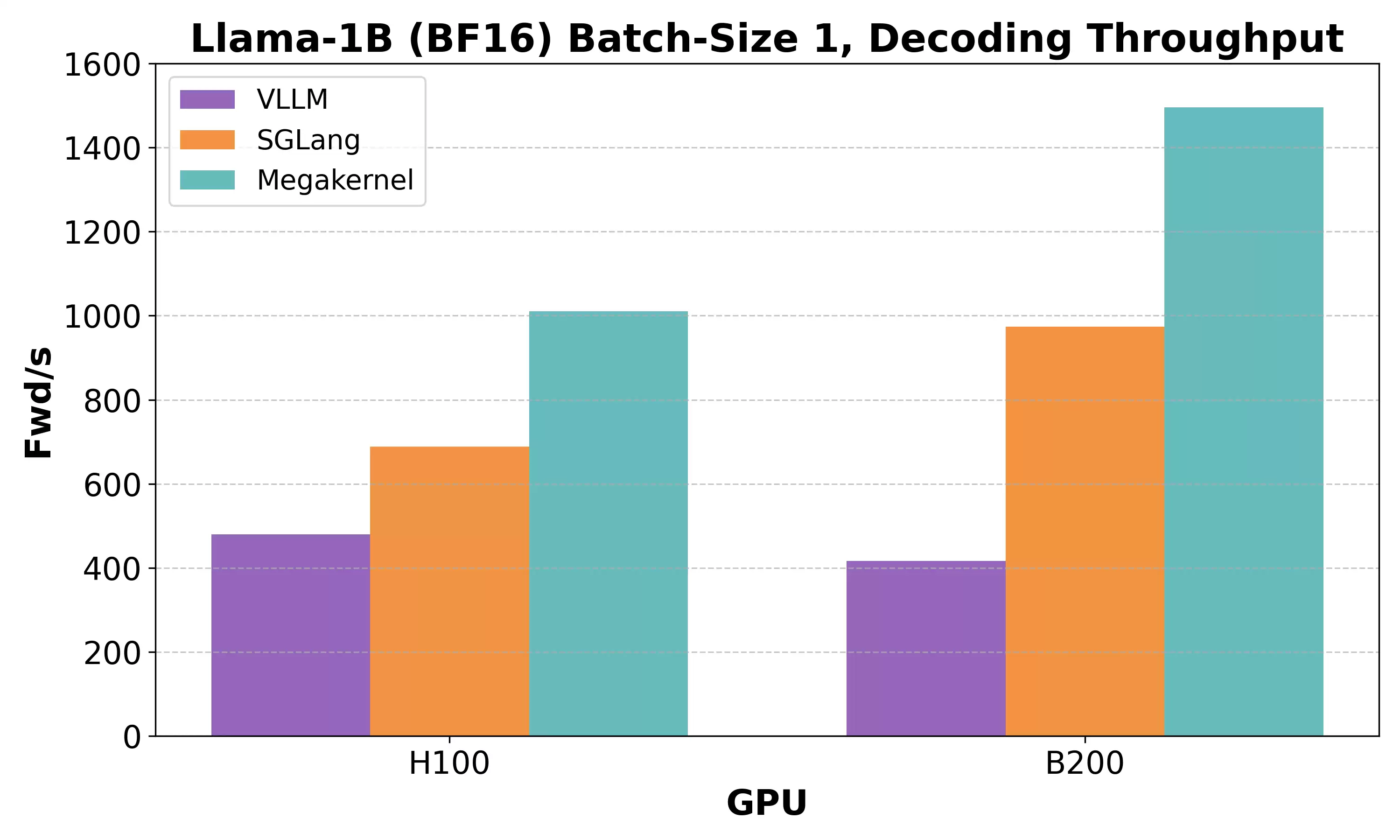
那么,Hazy团队提出的Megakernel方案效果究竟如何?数据给出了有力的证明。在H100 GPU上,他们的Megakernel将推理延迟压缩到了1毫秒以内,显存带宽利用率飙升至78%,相比vLLM提升了2.5倍,相比SGLang也提升了1.5倍。而在更先进的B200平台上,延迟进一步被压低至600到680微秒,几乎触及了硬件理论性能的天花板。
从一次完整推理的时间分解来看,核心计算(如矩阵-向量乘法)仅占约200微秒,而数据加载与同步等“后勤”开销被控制得极低。可以说,通过精密的指令调度与融合,Megakernel几乎榨干了硬件的每一分潜力。
能达到如此惊人的效果,核心在于一个激进的设计理念:彻底抛弃传统的多内核协作模式,将整个模型的前向传播过程,从头到尾整合进一个巨大的、单一的CUDA内核中。
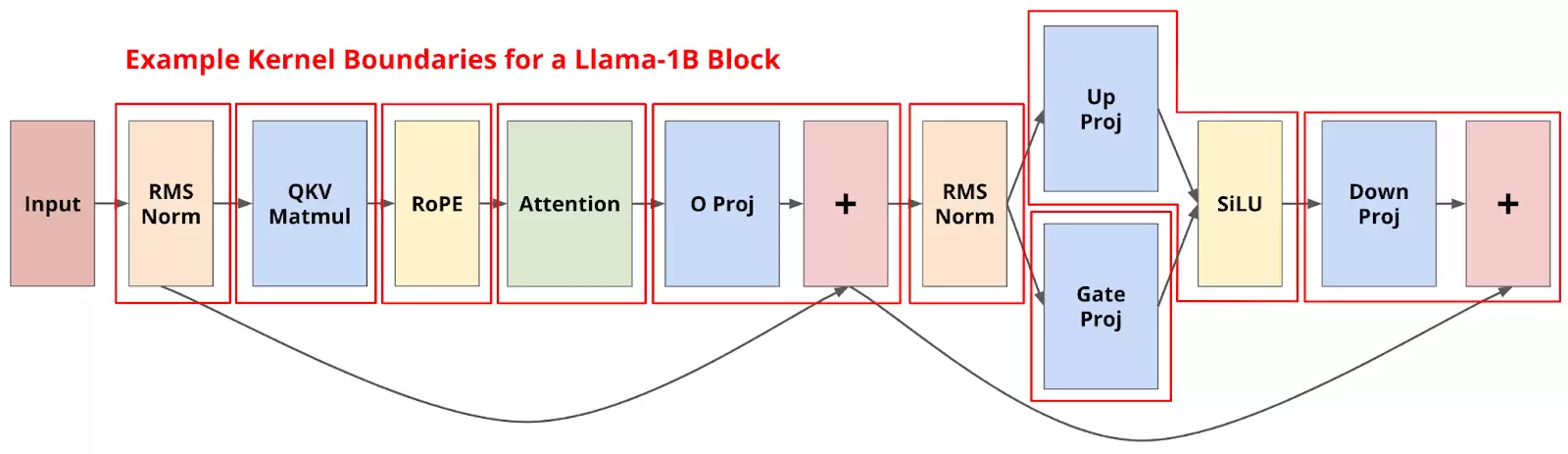
具体是如何实现的?团队基于已有的ThunderMLA架构,开发了一个在GPU上运行的轻量级“指令解释器”。该系统会为每个流式多处理器预先分配一份“执行计划”,计划中按顺序排列着代表Transformer各结构单元的复合指令,例如融合了RMSNorm、QKV投影和RoPE编码的指令,或是专门处理注意力与MLP的指令。
每一条指令都基于统一的模板构建,标准化了数据加载、计算和存储的流程。指令之间的依赖关系在运行前就由解释器静态分析并安排好,完全避免了运行时动态判断的开销。为了进一步提升效率,团队还对GPU的共享内存进行了精细的分页管理,确保不同计算阶段能够无缝衔接,下一个阶段可以尽早预加载权重数据,从而彻底消除了计算流水线中的“气泡”(空闲期)。
当然,将所有计算塞进一个内核也带来了新的挑战——传统的、隐式的内核间同步机制失效了。为此,团队引入了一套基于全局内存的计数器系统。每条指令执行完毕后,会对相应的计数器进行原子加一操作;如果某条指令需要等待前序步骤的结果,它会持续“监听”对应的计数器,直到数值达到预设条件才会开始执行。这种显式的、细粒度的依赖控制机制,避免了粗粒度的全局屏障,使得计算能够最大限度地并发进行。
研究过程中还揭示了一些有趣的发现。例如,即便在“已通过”的状态下,CUDA的异步屏障操作本身也有约60纳秒的固有开销,这在追求纳秒级优化的极致场景下不可忽视。此外,在关键的计算操作上,硬件架构差异的影响非常显著:在Hopper(H100)架构上,使用常规CUDA核心进行矩阵-向量乘法反而比使用专用的张量核心更高效;而在更新的Blackwell架构上,张量核心则重新占据了优势。这提醒我们,极致的性能优化需要针对特定的硬件微架构进行深度定制。
传统推理方式效率低下的根源剖析
在构建Megakernel之前,Hazy团队首先系统地剖析了现有方案为何在低延迟场景下“失灵”。结论指向一个系统性的根本问题:过度分解与模块化。
像vLLM和SGLang这样的系统,其设计初衷是为了追求灵活性和通用性,因此将模型前向过程拆分成大量细粒度的内核。这好比将一项复杂工作分配给几十名工人,每人只负责一道极其简单的工序。然而,在只需要生产一个“产品”(即生成一个token)的情况下,频繁的工人交接、任务派发(即内核启动与上下文切换)所花费的时间,反而远远超过了实际干活的时间。
每个内核启动都有其固定的开销,即便利用CUDA Graph等技术进行优化,也仍需1.3到2.1微秒。在这段时间里,GPU的强大计算单元处于等待状态。更为严重的是,这种串行执行模式导致数据加载无法实现流水线化。GPU计算完一个内核后,必须等待下一个内核启动,才能去加载新的权重和数据,这使得高带宽的显存在长时间内处于闲置状态,利用率自然低下。
这就形成了所谓的“内存-计算流水线气泡”:计算单元和内存控制器都无法持续饱和工作,而是在忙碌与等待之间反复切换,资源无法被充分利用。举例来说,从纯理论带宽计算,H100处理一次Llama-1B模型的前向传播可能非常快,但由于需要经历上百个内核的串行执行,每个内核带来的微小延迟累积起来,就会将实际性能拖慢数倍之多。
因此,问题的根源并非某个单一内核不够快,而是这种“微内核”架构本身在低延迟、单序列场景下,带来了无法通过局部优化消除的系统性开销。Hazy团队的思路清晰而彻底:要打破性能瓶颈,就必须从根本上重构执行模型,减少甚至消除内核间的边界,让GPU能够像处理一个连续任务一样流畅地工作。这正是Megakernel设计哲学的核心——用全局的、深度融合的视角,取代局部的、割裂的优化,从而实现AI推理延迟的极限压缩。