百川智能推出Baichuan2 Turbo API助力企业定制化服务
12月19日,百川智能正式开放了基于搜索增强的Baichuan2-Turbo系列API接口,涵盖Baichuan2-Turbo和Baichuan2-Turbo-192K两大版本。此次发布的核心亮点在于,它不仅提供了高达192K的超长上下文窗口支持,更重要的是,新增了搜索增强知识库的构建能力。这意味着,开发者现在可以通过API直接上传自有文本资料,快速构建专属知识库,从而打造更精准、更贴合业务场景的智能应用解决方案。在持续引领国内大模型开源生态之后,百川智能正致力于为企业级应用的深度定制与高效落地开辟一条创新路径。
与此同时,其官方网站的模型体验中心也同步升级,现已全面支持PDF、Word等多种格式的文档上传以及URL网址直接输入,让广大用户能够直观体验搜索增强技术与超长上下文窗口结合所带来的强大效果。
在百川智能的技术战略中,搜索增强被视为推动大模型规模化落地的关键引擎。它精准瞄准了当前阻碍大模型广泛应用的核心痛点:模型幻觉问题、信息时效性不足,以及垂直领域专业知识的匮乏。搜索增强技术,本质上是为大型语言模型配备了一个“实时外接大脑”。这个大脑既可以接入实时更新的互联网海量信息,也能无缝对接企业内部完整的私有化知识库。通过精准解析用户意图,在海量信息中快速检索出最相关的内容,再结合超长上下文窗口进行深度分析与归纳总结,这套技术组合不仅显著扩展了模型本身的能力边界,更使得各技术模块之间形成了高效协同的闭环。
大模型+搜索构成完整技术栈,实现了大模型和领域知识、全网知识的全新链接
大模型无疑是具有划时代意义的技术突破,但客观而言,它仍存在诸多挑战。幻觉现象、信息滞后、缺乏垂直行业深度知识,这些都是其在赋能各行各业时必须克服的障碍。
行业的探索从未停歇:扩大模型参数量、延伸上下文长度、接入外部数据库,或针对特定领域进行定向训练与微调。每条技术路线都有其价值,但也存在各自的局限性。例如,单纯扩大模型参数虽能提升通用智能水平,但随之而来的海量数据需求与巨额算力成本,让许多企业难以承受,且仅靠预训练难以从根本上解决幻觉和时效性问题。
业界迫切需要一条能够融合各方优势的路径,真正将大模型的潜力转化为可衡量的产业价值。百川智能提出的构想极具启发性:将“大模型+搜索增强”类比为新一代的计算架构。大模型本身如同计算机的中央处理器(CPU),负责核心的逻辑推理与运算;超长上下文窗口则相当于内存,用于处理当前的任务流与信息;而实时互联网信息与企业私有知识库共同构成了这个系统的“海量存储器”,提供了近乎无限的、可按需调用的知识储备。
基于这一核心理念,百川智能以Baichuan2大模型为基石,将搜索增强技术与超长上下文窗口进行深度融合,构建了一套完整的企业级AI技术栈。这不仅仅是简单的功能叠加,更是旨在实现大模型与领域专业知识、全网实时信息之间一种全新的、动态的、高效的连接方式。
用行业大模型解决企业应用不是最佳方法,大模型+搜索增强可以解决99%企业知识库的定制化需求
企业独有的数据和知识资产,是其构筑核心竞争力的关键。如果大模型无法与这些宝贵资产深度融合,其对企业产生的实际价值将大打折扣。过去,常见的解决方案是训练或微调一个专用的行业大模型。但这背后需要高水平的研发团队和持续的巨额算力投入,且每次知识更新都可能涉及重新训练或调整,流程繁琐、成本高昂、灵活性不足,模型稳定性也面临挑战。此外,企业大量数据是结构化的业务数据,并不完全适合直接用于模型微调,强行操作反而可能加剧模型的幻觉问题。
为了突破传统微调方法的局限,扩展上下文窗口和使用向量数据库是两条备受关注的技术路径。百川智能在此基础上实现了关键创新:它将传统的向量数据库升级为功能更强大的搜索增强知识库,显著提升了模型对外部知识的获取与利用效率;同时,通过将搜索增强与超长上下文窗口相结合,使得模型能够无缝衔接企业全部知识库与全网信息。这种“大模型+搜索增强”的模式,被认为能够替代绝大部分的企业个性化微调需求,高效解决高达99%的企业知识库定制化问题。其意义不仅在于为企业大幅节省成本与时间,更在于让企业的专有知识能够作为一种可持续积累、迭代和增值的数字资产沉淀下来。
当搜索增强方案有效缓解了幻觉和时效性两大核心难题后,大模型在实际业务中的可用性便得到了极大拓展。在金融、政务、司法、教育等领域的智能客服、精准知识问答、合规风控等场景中,其应用前景变得更为明朗。更重要的是,相比复杂的模型微调,搜索增强在显著提升模型能力的同时,大幅降低了技术应用门槛,使得广大中小企业,特别是电商领域的商家,也能轻松借助大模型技术提升运营效率与客户体验。这种方式,无疑将加速大模型在真实业务场景中创造实际价值的过程。
突破搜索增强技术多个难点,稀疏检索与向量检索并行召回率提升至 95%
尽管搜索增强前景广阔,但要构建一套高效、可靠且智能的检索增强生成系统却充满挑战,其中涉及多个技术难点,需要深厚的搜索引擎技术与大模型研发经验来攻克。
在大模型交互时代,用户的提问方式更加自然、口语化,且与对话上下文紧密相关。因此,如何精准对齐用户意图与搜索引擎的查询语句,成为首要挑战。百川智能利用自研大模型对用户意图理解模块进行专门优化,能够将用户连续、口语化的多轮对话,智能转化为更符合传统搜索引擎理解的关键词或结构化查询。
此外,研发团队还借鉴了Meta的CoVe(思维链验证)技术思想,将复杂的用户问题自动拆解为多个可并行检索的子问题,使得模型能够针对每个子问题进行精准定向搜索,从而组合出更准确、更详尽的答案。通过自研的TSF(深度思考)技术,模型还能进一步推断用户输入背后的深层需求与意图,引导生成更具洞察力和价值的回答。
在精准理解用户需求之后,下一步是高效地从知识库中匹配相关信息。这需要强大的向量模型来完成深度的语义匹配。百川智能自研的向量模型,使用了超过1.5T token的高质量中文数据进行预训练,并通过自研的损失函数持续优化训练过程。在中文MTEB评测集的多个代表性任务中,其综合表现取得了行业领先水平。
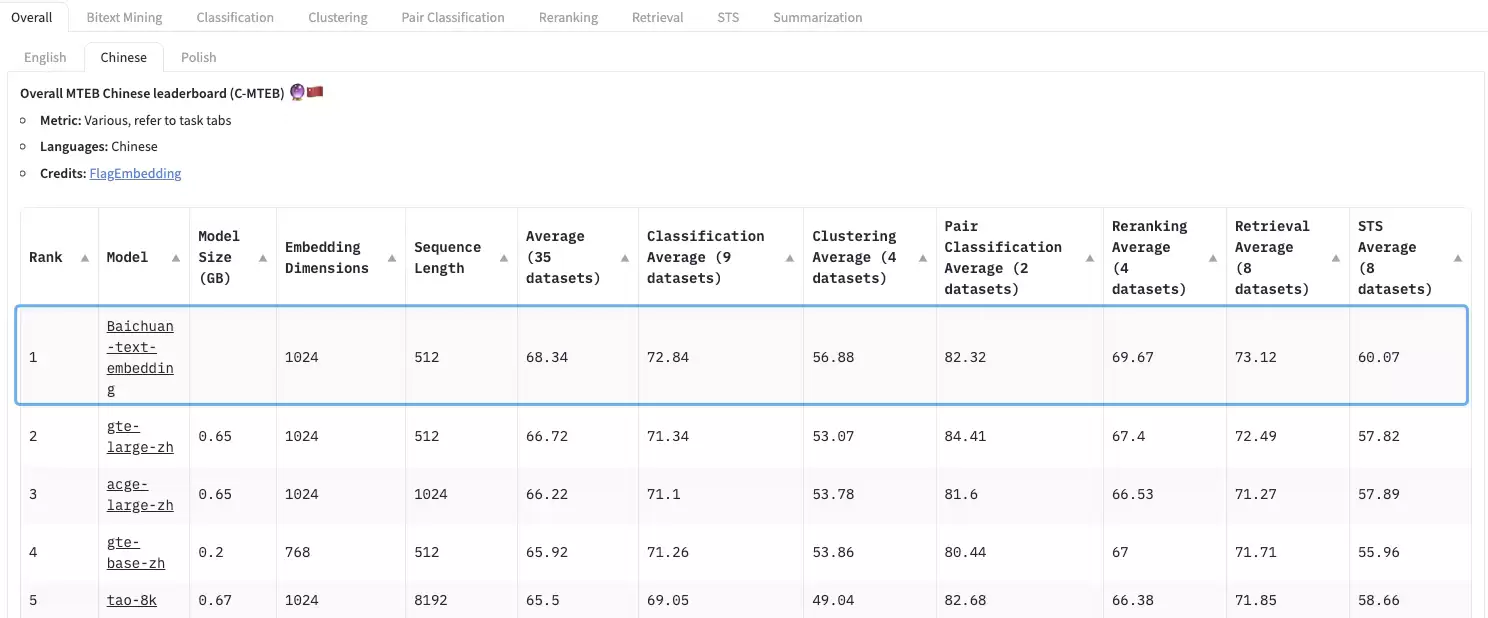
目前,构建知识库的主流方法是向量检索,但其效果高度依赖训练数据的覆盖面,在未充分覆盖的专业领域泛化能力会下降,且用户提问与知识文档的长度差异也给精准匹配带来挑战。
为此,百川智能并未单一依赖向量检索,而是创新性地融合了稀疏检索和重排序模型。通过采用稀疏检索与向量检索并行的混合检索策略,将目标文档的整体召回率提升到了95%的高水平,大幅优于市面上多数开源向量模型约80%的召回率。
另一个常见问题是,当检索到的资料本身存在错误,或与大模型自身的知识体系存在冲突时,反而可能加重模型的“幻觉”。针对这一痛点,百川智能在通用RAG技术基础上,首创了Self-Critique(大模型自省)技术。该技术能让大模型对检索返回的内容,从相关性、准确性、可用性等多个维度进行自我审查和筛选,自动挑出最优质、最匹配的部分作为参考,从而有效提升输入信息的质量,显著降低知识噪声的干扰。
5000万tokens数据集测试回答精度95%,长窗口+搜索实现“真·大海捞针”
超长上下文窗口虽然能容纳更多信息,但单纯延长窗口可能会牺牲模型的核心性能,且存在技术上限。同时,每次回答都需要将整个长文档重新读取一遍,导致推理效率低下,成本高昂。
百川智能采用的“长窗口+搜索增强”组合方案,则提供了一种更高效、更经济的思路。在192K超长窗口的基础上,通过集成搜索增强能力,模型能够有效处理的知识库规模实现了数量级的飞跃,达到5000万tokens。其核心工作流程是:首先根据用户问题,从海量文档中精准检索出最相关的片段,再将这部分精选内容与原始问题一同送入长上下文窗口进行深度处理。这相当于先通过智能检索“大海捞针”,再对找到的“针”进行“细看针眼”般的精细分析,极大地节省了推理成本和时间。
为了验证这一能力的有效性,团队采用了业内公认的权威长文本测试基准——“大海捞针”测试。对于192K token长度以内的请求,其回答精度可以达到100%。
而在远超单窗口长度的、高达5000万tokens的超大规模文档数据集测试中,结合搜索系统后,采用稀疏检索+向量检索的混合方式,实现了95%的回答精度,接近全域满分。而单一的向量检索方式,精度则为80%。这充分证明了混合检索策略在应对超大规模知识库时的显著优势。
本次测试基于中文场景进行,具体配置如下:
• 大海(HayStack):博金大模型挑战赛-金融数据集中的80份长金融文档。
• 针(Needle):一段关于百川智能CEO王小川在极客公园创新大会2024上分享的内容,其中提到了“技术产品匹配(TPF)”这一概念。
• 查询问题:王小川认为大模型时代下,产品经理的出发点是什么?
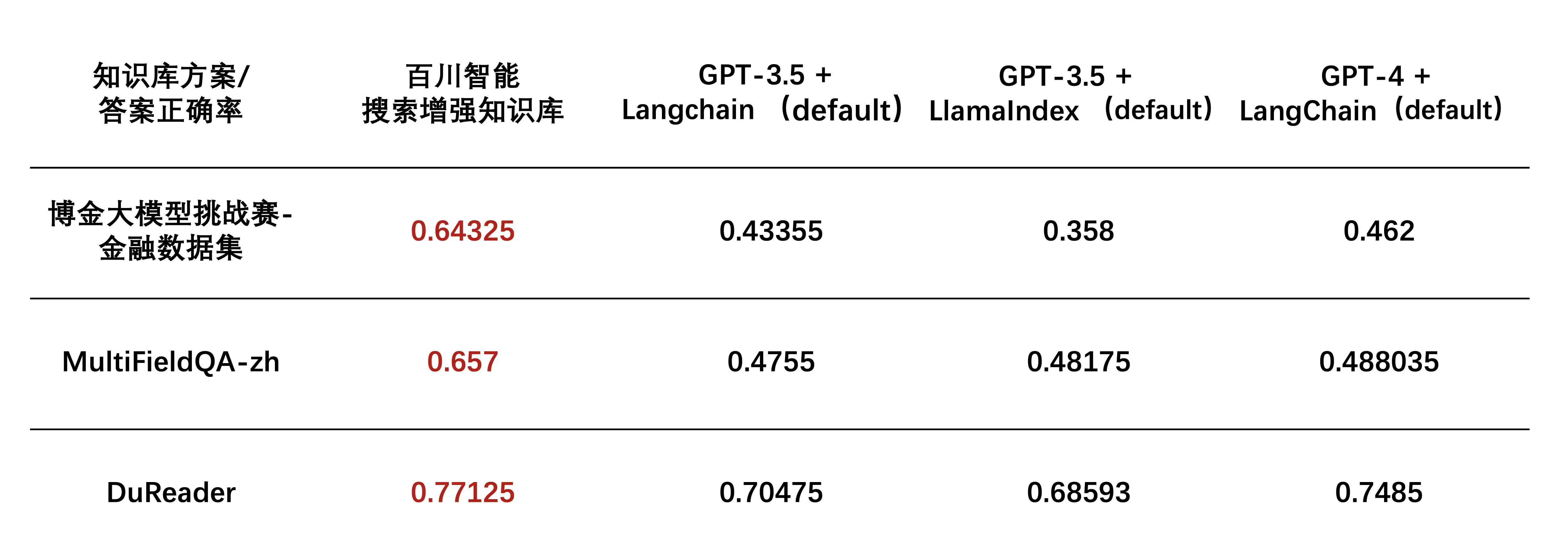
此外,百川智能的搜索增强知识库在多个主流知识库测试集上的表现同样出色,在博金大模型挑战赛-金融数据集(文档理解部分)、MultiFieldQA-zh和DuReader等权威评测中,其得分均领先于GPT-3.5、GPT-4等行业头部模型。
据了解,目前已有金融、法律、教育等多个行业的头部企业与百川智能展开深度合作,基于其长上下文窗口和搜索增强知识库的强大能力,对自身业务进行智能化升级与创新探索。这条“大模型+搜索增强”的路径能否成为企业高效拥抱AI的捷径,市场正在持续验证并给出积极反馈。
相关攻略

在人工智能浪潮中,大语言模型已成为推动产业变革的关键引擎。其中,实在智能推出的实在塔斯(TARS)大模型,是一款面向垂直行业领域、可自主训练的类ChatGPT大语言模型。它并非通用模型的简单复刻,而是基于实在智能在自然语言处理领域长期的技术积淀与丰富的落地经验,为行业深度定制而生。下面,我们来详细拆

在探索如何高效利用GPT、BERT等大型语言模型的强大能力时,“工作流”无疑是实现任务自动化与智能化的核心策略。它是一套将复杂问题标准化、流程化的系统性方法,旨在显著提升任务执行的效率与输出结果的可靠性。那么,一套优秀的大模型工作流具体包含哪些关键组成部分?我们又该如何设计与实施呢? 工作流的核心要

大模型缓存机制通过KVCache和前缀匹配实现重复内容仅计费一次,显著降低成本。主流方案差异明显:OpenAI自动缓存折扣约五折但时效短;Claude需手动标记,折扣可低至一折;DeepSeek采用硬盘缓存,持久且费用极低。工程中应将稳定内容前置以提升命中率,高频重复场景下合理利用可大幅节省费用。

谈及当前企业智能化转型的主流方案,“大模型一体机”无疑是备受关注的核心选项。本质上,它是一套完整的“交钥匙”解决方案,将AI服务器硬件、预训练好的大模型以及配套的应用软件深度融合,打包交付,旨在为企业提供安全、高效、可私有化部署的大模型服务。 一、核心构成:三位一体的“智能体” 这套系统的架构与核心

企业在引入大型人工智能模型时,面临一个关键抉择:是采用便捷的云端服务,还是选择将模型私有化部署在本地?后者,即将大模型部署于企业自有的服务器或专用硬件上,正日益成为对数据安全、响应速度和成本控制有严格要求的机构的核心选择方案。 一、私有化部署的背景与趋势 在人工智能技术迅猛发展的浪潮中,以实在智能为
热门专题







热门推荐

华硕在ROGDAY2026上发布了枪神10X整机,首次搭载三颗可联动显示的全息光显风扇,外观极具未来感。其核心配置顶级,采用AMD锐龙99950X3D2处理器、ROGRTX5080显卡、64GB内存及4TBSSD,并配备高效三区独立散热系统,定价69999元。

智能门锁领域迎来重磅新品。知名品牌鹿客近期于京东平台正式发售其旗舰型号V3 Max智能门锁,该产品凭借创新的隔空无线充电技术与先进的AI视觉识别系统引发市场关注。官方定价为3572元,在部分参与促销活动的地区,消费者可享受补贴,最终入手价有望低至2799元,性价比优势显著。 鹿客V3 Max在视觉安

在备受瞩目的ROG DAY 2026广州站活动中,华硕重磅发布了其新一代高性能游戏笔记本电脑——ROG魔霸10系列。该系列包含16英寸的魔霸10与屏幕更大的18英寸魔霸10 Plus两款机型,旨在为硬核玩家带来顶级的游戏体验。 ROG魔霸10系列的硬件配置堪称顶级。处理器方面,用户最高可选择搭载AM

5月15日,小米官方正式公布了小米手环10 Pro的完整配置信息。作为新一代旗舰手环,它在健康监测精准度、运动功能专业度以及佩戴舒适度上均实现了显著突破,为用户带来了更全面的智能穿戴体验。 小米手环10 Pro 健康监测:精度与维度的双重跃升 本次升级的核心在于健康监测能力的全面进化。小米手环10

金士顿扩展其可超频的ECCRDIMM内存系列,新增高达7600MT s型号。其中高速型号采用全新铝制散热马甲,提升散热效率以保障高负载下的稳定运行。该系列同时支持ECC校验与超频,兼顾性能与数据完整性,适用于AI计算、工程仿真等高要求专业场景。