【导读】一个让所有前沿AI模型集体“交白卷”的地狱级编程基准,终于被撕开了一道口子。GPT-5.5在ProgramBench上实现了零的突破,开局没有一行源代码,全靠推理算力硬闯,最终成功通关。这似乎宣告,传统的代码测试正在失效,一场围绕推理能力的算力狂飙,已经正式打响了。
编程AI的“终极考试”,迎来了第一位通关者。
就在最近,由Meta联手斯坦福、哈佛推出的全新编程基准ProgramBench,以其前所未有的难度震惊了业界:整整200道题,所有前沿AI模型的通过率——清一色的零。
没有一个模型能完整解出哪怕一道题。然而,这个僵局刚刚被打破了。GPT-5.5成为了那个破例者,拿下了“首杀”。

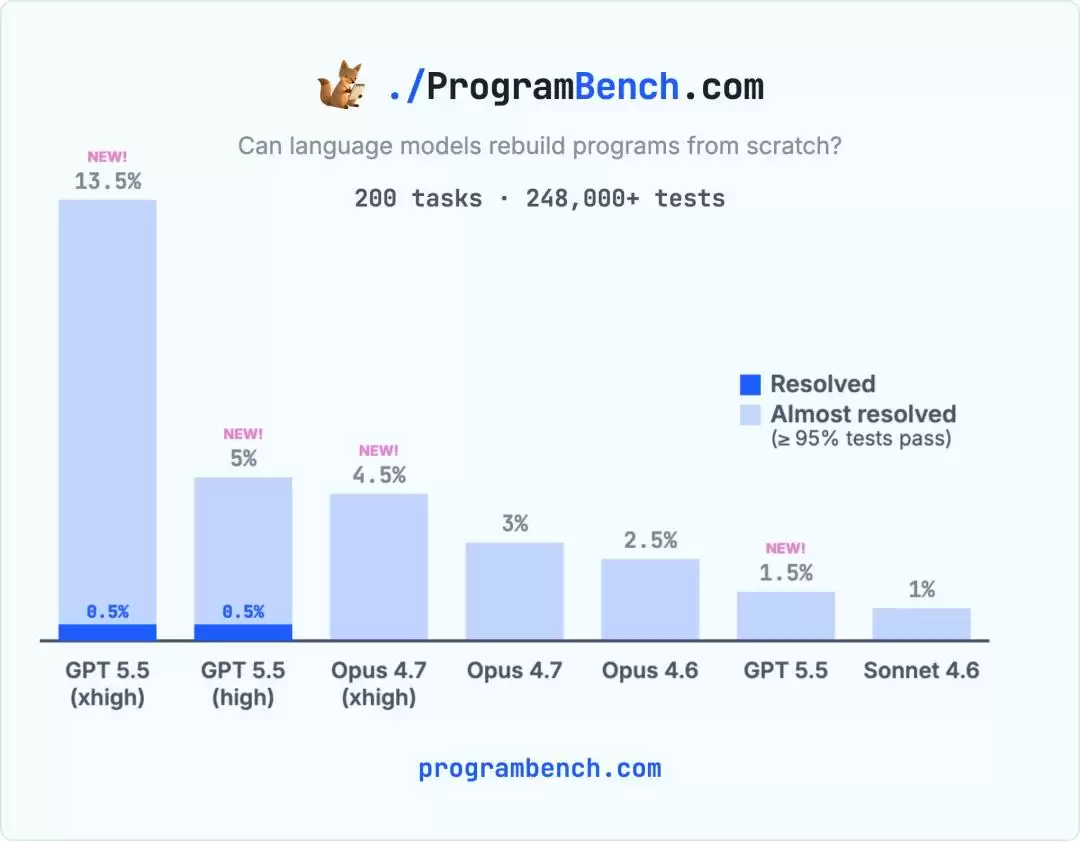
从对比图可以清晰看到,在两种不同的编程语言C和Python上,GPT-5.5的xhigh版本完全碾压了竞争对手Claude Opus 4.7的xhigh版本。
这个里程碑式的突破,究竟意味着什么?
编程AI「终极考试」,从0重建程序
要理解这次突破的分量,首先得明白ProgramBench到底难在哪里。
传统的编程基准,无论是SWE-bench还是HumanEval,本质上更像是“开卷考试”。它们要么给模型一个现有的代码库让它修Bug,要么让它补全一个函数框架。模型有大量的上下文可以参考。
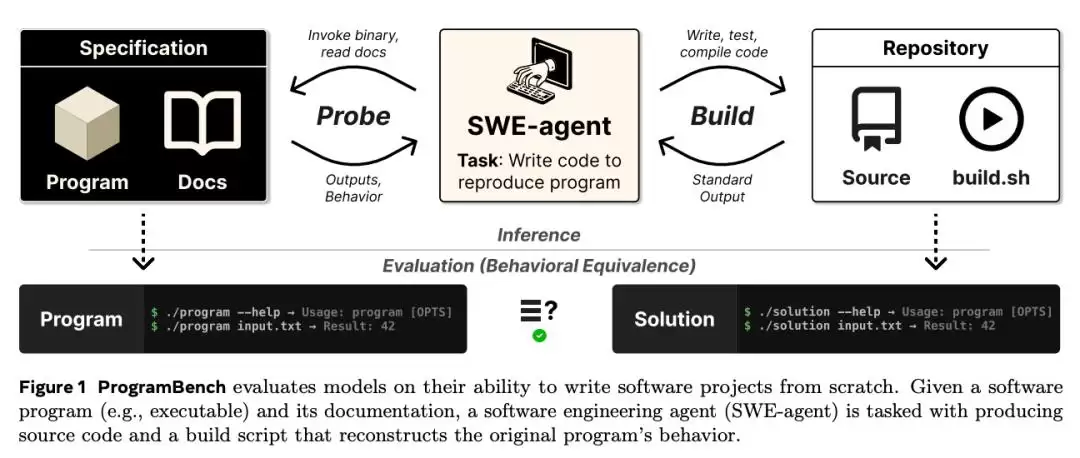
但ProgramBench彻底碘伏了这个模式。它给出的是一份“闭卷”的终极挑战:只给你一个编译好的可执行文件,外加一份功能描述文档。任务要求是——从零开始,把这个程序原样重写出来。
不给源码,不许反编译,也不许联网搜索。完全依靠模型对可执行文件行为的观察、测试和推理,来反向工程出完整的实现。
这200个任务覆盖的范围极广,从jq、ripgrep这类命令行小工具,到FFmpeg、SQLite乃至PHP编译器这样的重量级项目。其难度之高,让OpenAI的研究员Noam Brown都曾公开表示,是时候淘汰旧的评估方式,引入像ProgramBench这样的全新基准了。

基准刚发布时,所有刷榜的AI几乎全军覆没。而如今,GPT-5.5终于扳回了一城。
GPT-5.5首破纪录:同一题,C和Python两种解法
GPT-5.5攻克的第一个任务是“cmatrix”,一个在终端里模拟《黑客帝国》数字雨效果的经典程序。
有趣的是,研究人员发现,GPT-5.5的high和xhigh两个不同推理级别,竟然选择了完全不同的编程语言来攻克同一道题。high版本采用了C语言,而xhigh版本则使用了Python。

最终,两个版本都成功通过了全部的行为测试,但策略各有千秋。
GPT-5.5 high版本展现出了教科书般的工程方法:它先进行了10轮探索,测试了40多种不同的命令行参数组合,彻底摸清了原程序的所有行为模式。然后,它一次性写出了完整的C语言实现,仅经过5次微调修补就大功告成。
GPT-5.5 xhigh版本则更加彻底。它进行了多达27步的探索,几乎穷尽了每一条可能的命令行路径,对程序行为有了更深的理解,随后一气呵成地写出了完整的Python实现。
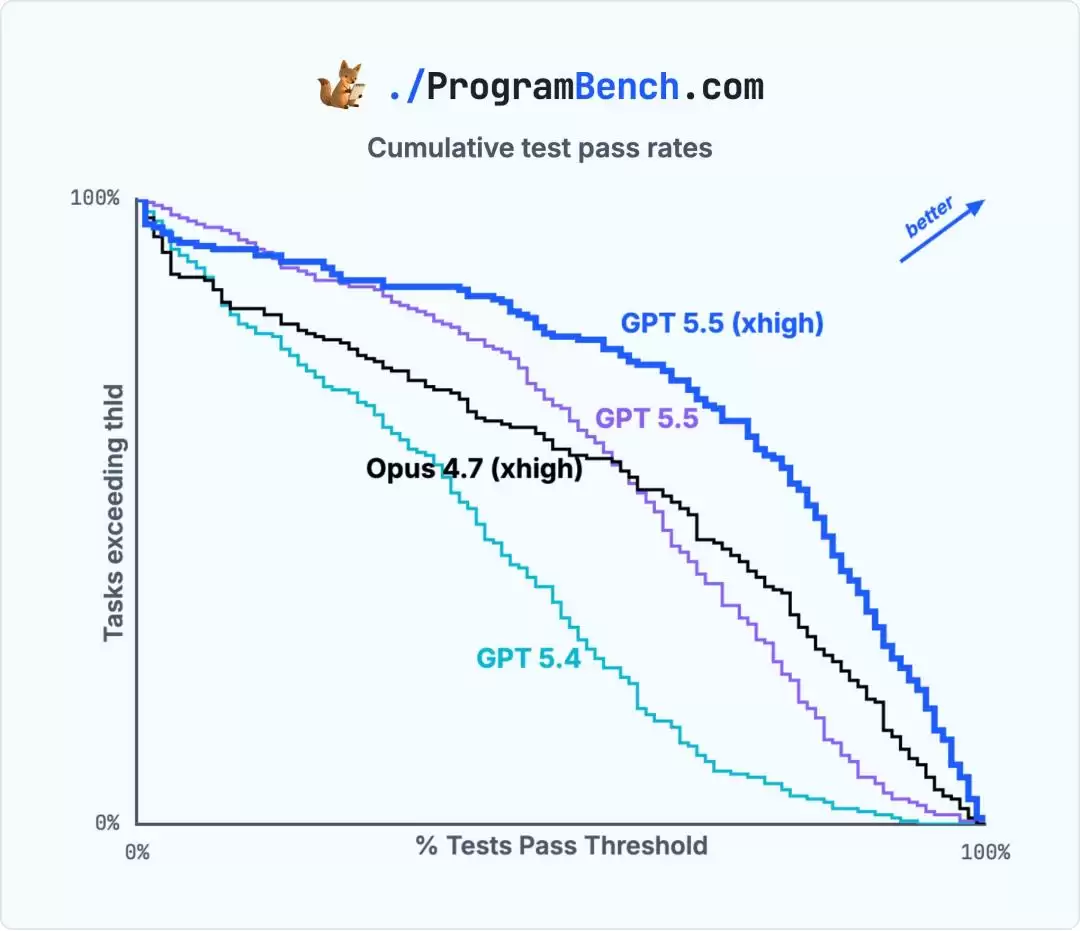
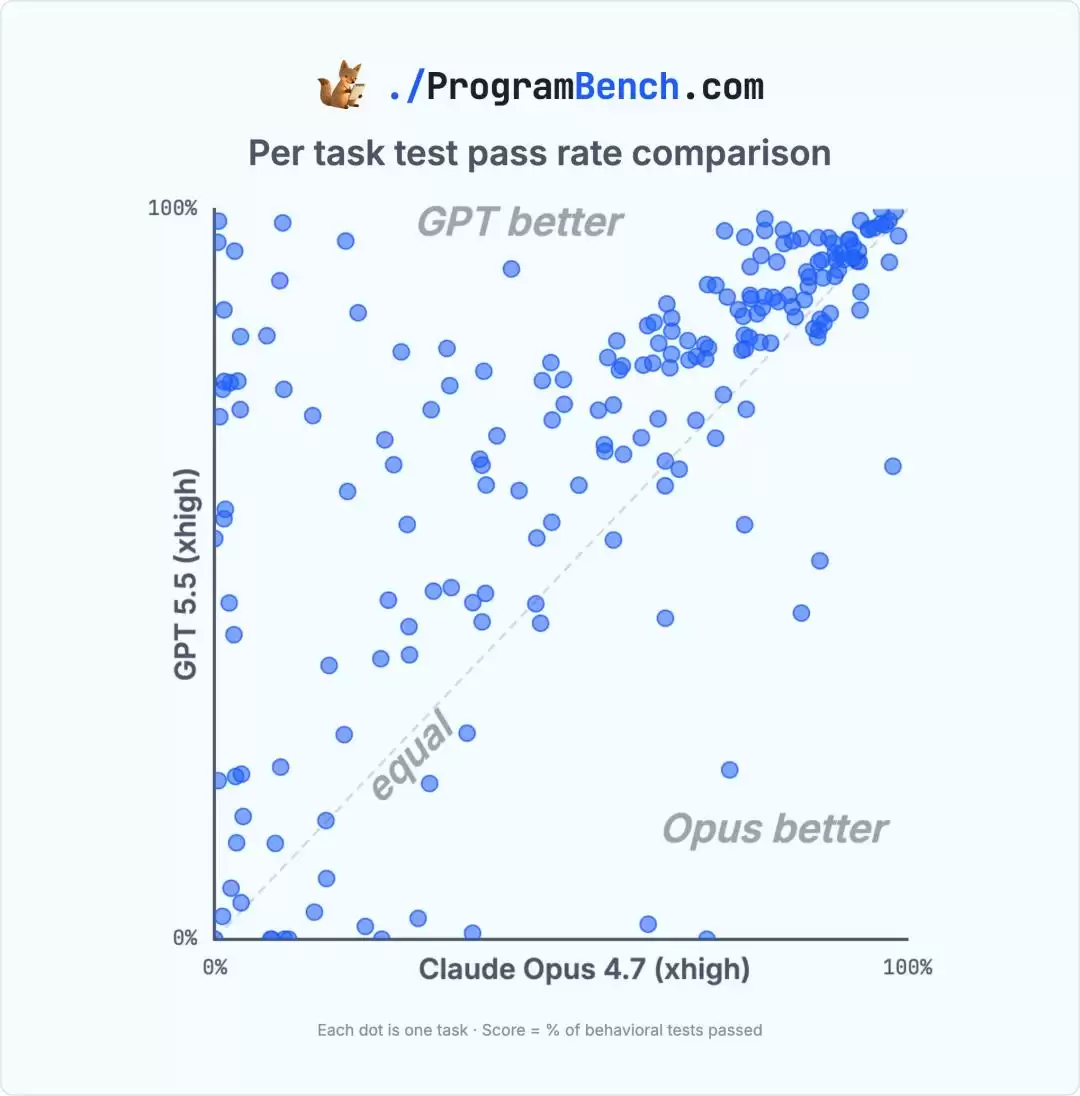
关键的数据对比揭示了更深刻的趋势。在未开启高推理模式(medium)时,GPT-5.5的成绩只是勉强比Claude Sonnet 4.6好一点。然而,一旦切换到xhigh模式,其性能直接产生了质的飞跃。
它不仅成为了首个解出一道题(通过率0.5%)的模型,还创下了一项新纪录:在26个任务中,其实现的程序通过了95%以上的单元测试。更重要的是,在完整的累积性能直方图上,GPT-5.5 xhigh全程碾压所有对手。无论看平均分、中位数,还是通过率超过90%或50%的任务数量,它都稳居第一。
178次调用,Opus 4.7栽在两个bug上
与GPT-5.5的“高效”相比,Claude Opus 4.7 xhigh版本的表现则有些令人唏嘘。
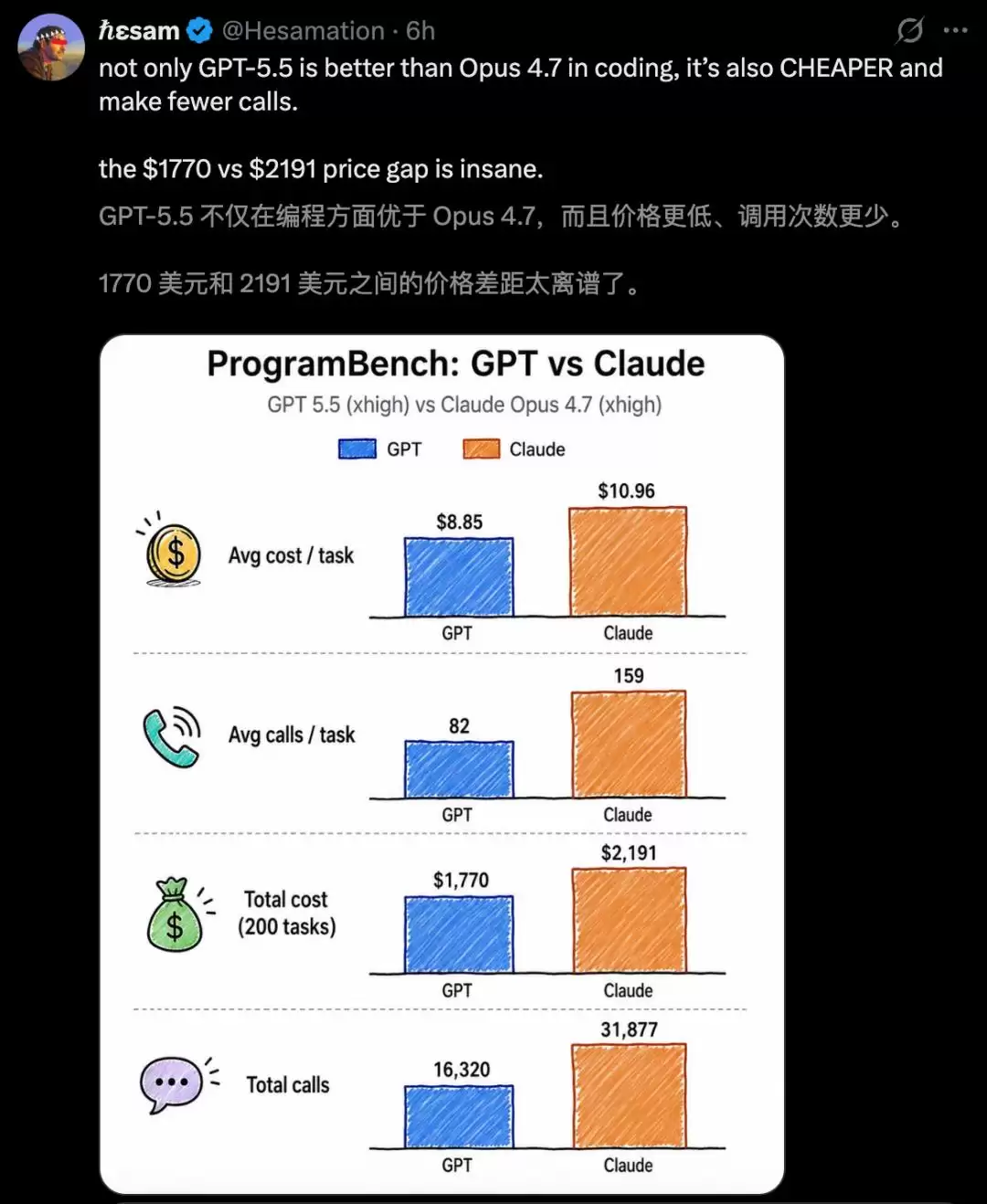
它花费了10.74美元,调用了178次API,成本是GPT-5.5普通版(1.04美元,17次调用)的十倍之多。结果却是在19个测试上失败,成绩垫底。
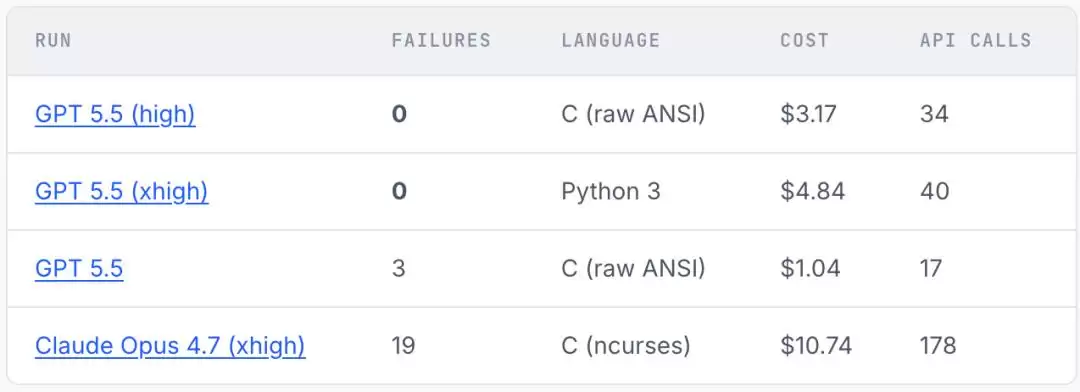
分析其失败原因,出人意料地简单,甚至有些“低级”:
Bug 1:颜色解析的大小写敏感问题。 Opus的代码在比较颜色字符串时,使用了严格区分大小写的strcmp(),而不是不区分大小写的strcasecmp()。这导致用户输入“GREEN”、“Red”、“BLUE”等混合大小写的颜色时,全部被判定为无效。仅仅这一个函数调用的差异,就直接导致了11个测试失败。
更具讽刺意味的是,在其长达178步的探索过程中,Opus从未测试过大写或混合大小写的颜色输入,它只尝试了小写和一个无效颜色“purple”。

Bug 2:无效颜色的退出码错误。 原程序在遇到无效颜色参数时,返回的退出码是exit(0),而Opus的实现却写成了exit(1)。这个细微的差异,又导致了另外8个测试失败。

颇具戏剧性的是,Opus在探索阶段明明观察到了原程序的行为——执行./executable -C purple; echo “exit=$?”后输出的是exit=0。但在测试自己的实现时,它却没有发现这个行为差异。
当然,Opus 4.7也并非全无亮点。它在处理缺失的ncurses图形库头文件时,展现了惊人的系统工程能力。当其他三个模型发现ncurses.h缺失后,都选择了改用ANSI转义序列这种更简单的方式来绕过。

而Opus 4.7则花了大约20步进行深入调查:先用ldconfig -p发现了系统中存在的运行时库文件(.so),再用nm -D检查了库文件导出的符号,最后徒手编写了一份长达106行的头文件声明,直接链接动态库来解决问题。这是一种真正的、富有创意的工程思维,尽管它并没有为最终的成绩带来帮助。
还有199题未解
ProgramBench的出现,无疑标志着编程能力评估进入了一个全新的、更残酷的阶段。
传统的SWE-bench基准,通过率已经被卷到了88.7%;在GPQA(一个面向博士水平的多学科测试)上,AI的表现已经超过了大多数PhD。这些旧的评估标准正在以惊人的速度“融化”,分数越来越高,区分度却越来越低。
而ProgramBench,200道题,至今只有1道被解出,整体通过率仅为0.5%。它像一座刚刚被发现的金矿,储量巨大,但极难开采。
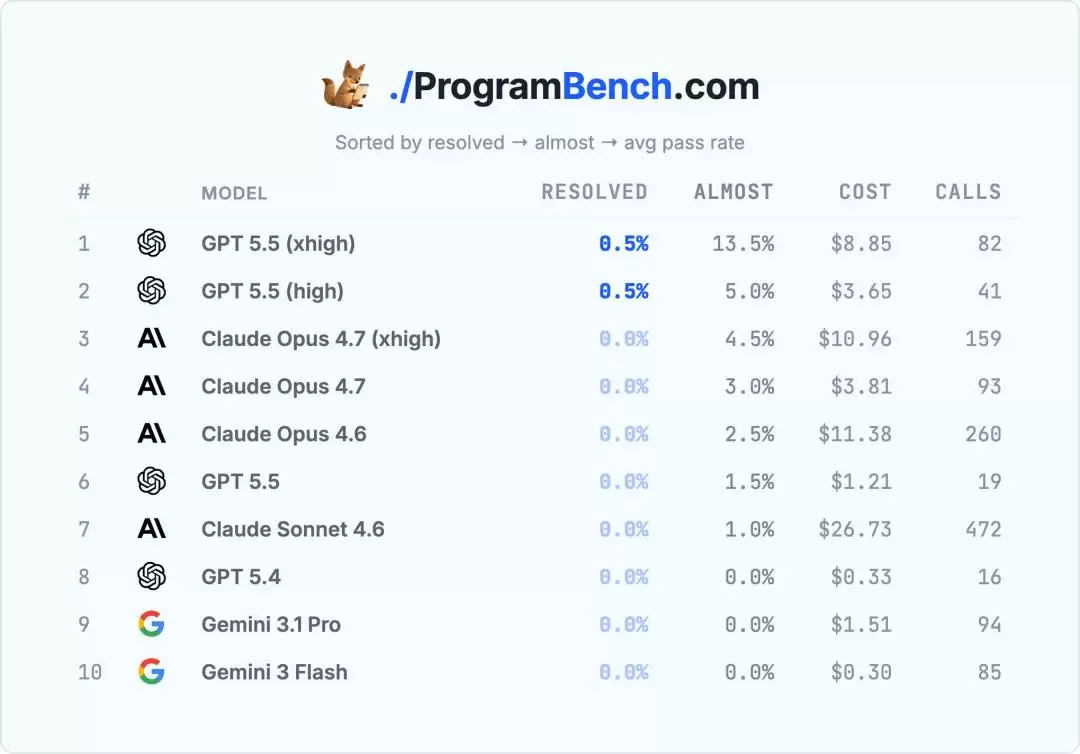
更重要的是,这次破纪录揭示了一个关键趋势:“推理算力”正在成为决定编程AI能力上限的核心变量。GPT-5.5在默认推理模式下表现平平,但一旦切换到高推理模式,性能便产生了飞跃。这强烈暗示,问题可能不在于模型不够“聪明”,而在于之前给予它们“思考”的时间和资源远远不够。
ProgramBench的战场上,还有199座堡垒在静静等待挑战者。
从零到一,不只是起点
回顾AI发展史上的那些“从零到一”的时刻——AlphaGo首次击败职业棋手、GPT-4首次通过律师资格考试、o1首次在数学奥赛题上得分——每一次都不仅仅是线性进步的起点,而是指数级能力爆发的信号弹。
Noam Brown等人提出的推理算力缩放定律(Scaling Law),在ProgramBench上得到了迄今为止最直观的验证:同一个GPT-5.5模型底座,medium模式几乎交白卷,high模式能满分通关单一任务,而xhigh模式则实现了断层式的领先碾压。
这揭示了一个深刻的洞见:智能,或许不再是一个固定的属性值,而是一个可以随算力投入而增长的函数。
这意味着什么?这意味着,通往更高级人工智能(ASI)的路径,可能并不一定需要等待下一次碘伏性的架构革命。只要推理算力能够持续扩展,只要缩放定律的墙还没有撞上。
那么,今天只能在ProgramBench上重建一个“数字雨”屏保程序的模型,明天或许就能重建SQLite数据库,后天,重建整个Linux内核也并非天方夜谭。这场由算力驱动的智能狂飙,才刚刚拉开序幕。




