何恺明,这位计算机视觉领域的标志性人物,这次将目光投向了语言模型。不过,他带领团队探索的,并非当下如ChatGPT所采用、基于“预测下一个词元”的自回归范式。
他们选择的,是一条在过去几年图像生成领域大放异彩,如今正被越来越多研究者引入文本生成的新路径:扩散语言模型。
在其团队的最新论文中,一个名为“ELF:Embedded Language Flows”的全新连续扩散语言模型被提出。

与许多仍在词元(token)层面进行扩散的语言模型不同,ELF将整个生成过程都置于连续的嵌入(embedding)空间中进行,直到最后一步,才重新离散化,将表示变回词元。
正是凭借这一设计,ELF仅用1.05亿参数、450亿训练词元、32步采样,就在多项指标上正面超越了一批主流的扩散语言模型。
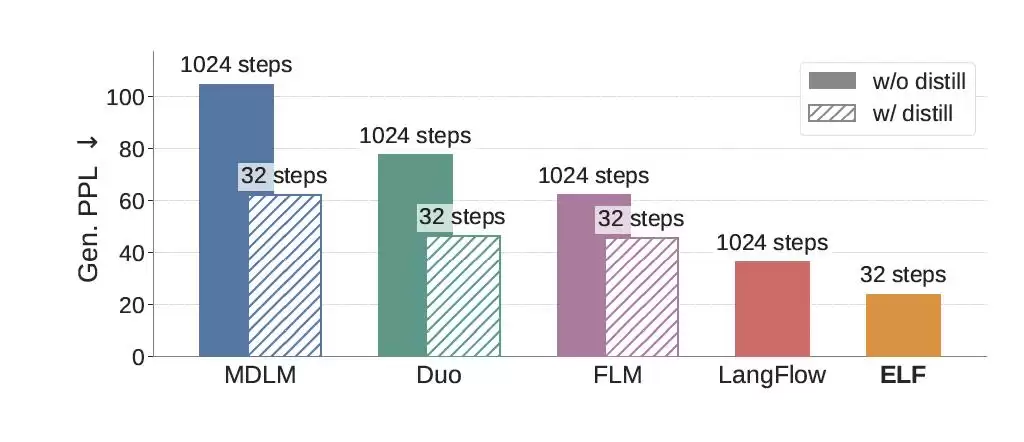
最直观的一项成果是,在OpenWebText数据集上,它将生成困惑度压到了24。这个指标可以理解为,让一个强大的语言模型为生成结果“打分”,数值越低,意味着生成文本的质量越高、越接近人类自然语言。
在与同类模型的对比中,ELF在训练词元少近10倍、采样步数更少的情况下,反而取得了更低的生成困惑度。
可以说,在过去很长一段时间里,扩散语言模型的主要进展都集中在离散路线。而ELF首次有力地证明:连续的方法,不仅可行,而且效果出众。
ELF到底做了什么
要理解ELF的创新,首先得厘清当前扩散语言模型的两条主流技术路线。
一派是以MDLM、Duo为代表的“离散派”,直接在离散的词元空间进行扩散。另一派则是“连续派”,如Diffusion-LM、CDCD等,它们先将词元映射为连续的嵌入向量,然后在连续空间中进行去噪。
此前,离散路线似乎更受青睐,原因看似不言而喻:语言本身就是离散的。然而,何恺明团队提出了一个反向的洞见——问题或许不在于“语言必须离散”,而在于前人并未将“连续”路线贯彻到底。
早期的连续方法,如Diffusion-LM,虽然在嵌入空间去噪,但每一步仍需计算词元级别的交叉熵损失,相当于将连续的生成轨迹始终“拴”在离散的词表上。后来的LD4LG、Cosmos等潜在扩散模型,去噪过程连续了,却需要额外训练一个解码器将潜在表示转换回词元,引入了新的模块。
ELF的思路则更为彻底:它将所有的去噪过程,完全保留在连续的嵌入空间内;直到最终时刻(t=1),才一次性映射回离散词元。

具体而言,在训练阶段,离散词元先被编码成连续嵌入,再加噪形成带噪表示。模型的任务,要么是将其还原为干净的嵌入(使用均方误差损失),要么直接预测词元(使用交叉熵损失)。
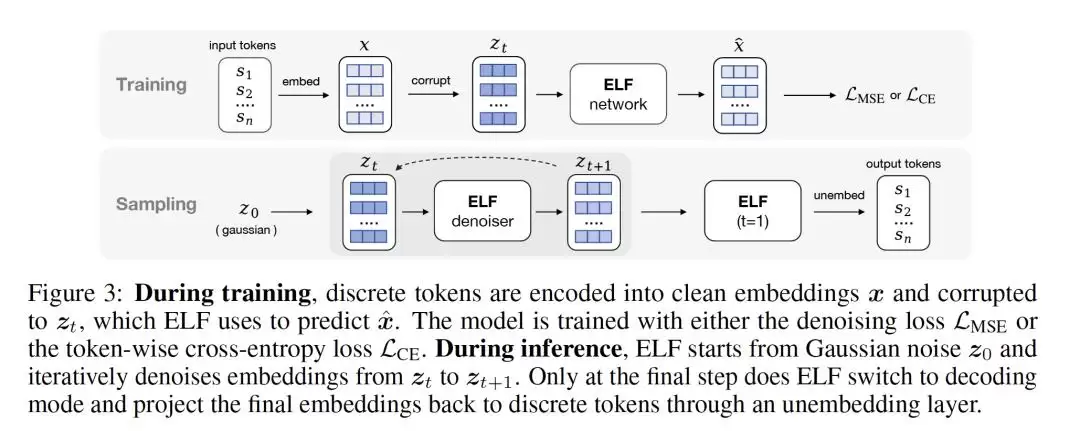
在推理生成时,模型从高斯噪声出发,全程在连续空间中进行去噪。直到最后一步,才切换到解码模式,将最终的嵌入表示投射回词元。
ELF首次清晰地将“连续表示”与“离散输出”这两个过去常被纠缠处理的问题拆解开来:中间的去噪过程完全交给连续空间自由演化;最终的语言生成,则仅作为最后一步的离散化操作。
这种设计,既避免了每一步都强行向词表对齐所带来的约束,也无需引入额外的解码器模块。整个流程真正实现了“连续的归连续,离散的归离散”。而这,正是ELF能够以更少的采样步数和训练数据,取得更优效果的关键所在。
ELF不是“先扩散,再解码”
在具体实现上,ELF系统地解决了三个核心问题:词元如何变为连续表示?在连续空间中如何有效去噪?最后又如何变回词元?
把token变成连续embedding
应用连续扩散于语言生成,第一步是将离散的词元序列转化为连续的向量表示。ELF默认采用预训练的T5编码器来生成具有上下文信息的双向嵌入。值得注意的是,这个编码器仅在训练阶段使用,推理时不会增加额外计算负担。
在连续embedding空间里做Flow Matching
获得连续表示后,ELF在嵌入空间中执行流匹配。简单来说,流匹配定义了一条从噪声数据到干净数据的平滑轨迹:起点是高斯噪声,终点是目标嵌入,中间状态是两者的线性插值。
与传统直接预测“速度场”的做法不同,ELF沿用了团队此前在《Back to Basics》论文中的思路——直接预测干净的嵌入本身。其训练目标是最小化预测嵌入与真实嵌入之间的均方误差。

采用这种“x-预测”方式有两个主要原因:其一,它在高维嵌入空间(如768维或更高)中表现更稳定;其二,它天然地与最终“预测干净词元”的目标对齐。实验也表明,若采用速度场预测并共享权重,模型性能会显著下降。
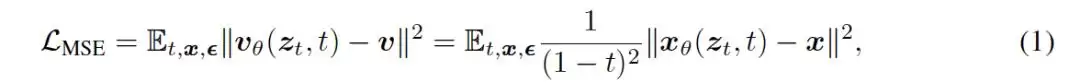
从连续embedding,再回到离散token
语言生成的最终输出必须是离散词元。因此,ELF在最后一个时间步,需要将连续的嵌入表示映射回词元空间。
巧妙的是,ELF并未像许多潜在扩散模型那样训练一个独立的解码器。它将最后一步视作一次“连续到离散的解码”,而这个解码器与前面的去噪器,其实是同一个神经网络。
为了确保最后一步的训练不至于太简单(因为此时输入已非常接近干净嵌入),ELF在最后一步额外引入了一次词元级别的扰动,构造出带噪声的输入。随后,同一个网络输出干净嵌入,再通过一个可学习的反嵌入矩阵投影为词元逻辑值。训练目标则是标准的词元级交叉熵损失。整个网络共享参数,并通过一个二值的模式标记来区分“去噪模式”与“解码模式”。
推理时,模型从噪声开始连续去噪,直至最后一步切换模式并输出最终词元。此外,ELF还将图像生成中常用的“无分类器引导”技术适配了过来,利用自条件信号来提升生成质量。
实验对比
实验部分,ELF有力地回答了一个悬而未决的问题:连续扩散语言模型,究竟竞争力如何?结果表明,它不仅在质量上能打,更在速度与训练成本上实现了多重优势。
如前所述,在OpenWebText的文本生成任务中,ELF仅用32步采样,在不进行蒸馏的情况下,就将生成困惑度降至24。而许多主流离散扩散模型往往需要运行1024步才能达到相近水平。
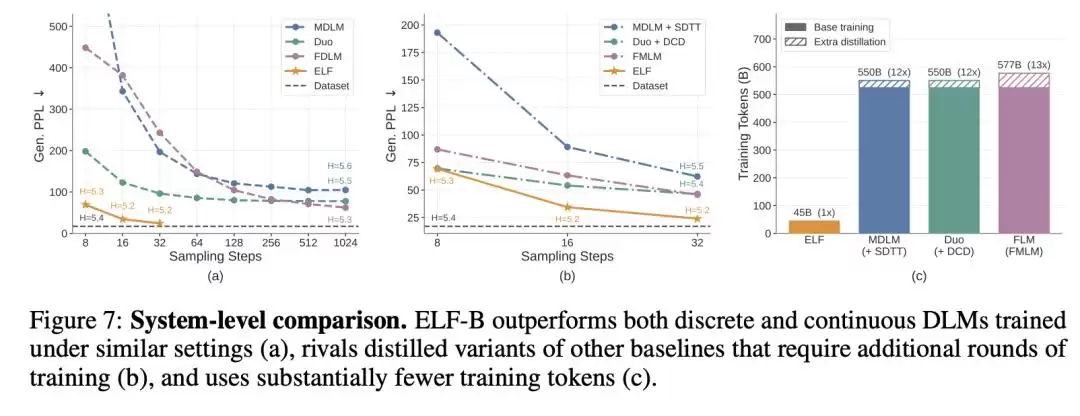
更值得注意的是,ELF达成这一结果所使用的训练词元量仅为450亿,而同类模型通常需要5000亿以上。这意味着,它在采样效率和训练数据需求上都减少了一个数量级,效果却更优。
在条件生成任务上,ELF同样表现稳健。无论是在WMT14机器翻译还是XSum文本摘要任务中,它都稳定超越了现有的扩散语言模型,甚至优于部分自回归基线模型。

论文总结颇为克制:ELF在生成质量、采样效率和训练成本之间,实现了出色的权衡。用更直白的话说就是:连续派路线并非天生劣势,只是此前未能将“连续”的理念执行得如此彻底。
作者介绍
这篇论文有两位共同第一作者,贡献顺序由抛硬币决定。
胡珂雅,MIT EECS一年级博士生,是何恺明在MIT指导的首批博士生之一,由何恺明与Jacob Andreas联合指导。她本科毕业于上海交通大学ACM班,研究兴趣聚焦于语言与视觉的交叉领域,致力于构建数据效率更高、泛化能力更强的智能体。在何恺明MIT的主页上,她位列研究生名单首位。

另一位第一作者Linlu Qiu,同为MIT博士生,师从Yoon Kim教授。她本科毕业于香港大学,硕士毕业于佐治亚理工学院,曾在谷歌担任AI研究员。值得一提的是,这并非她首次与何恺明团队合作,不久前他们共同完成的论文《ARC Is a Vision Problem!》已被CVPR 2026接收。

作者Hanhong Zhao(赵瀚宏)为MIT本科生,高中就读于中国人民大学附属中学,曾获国际物理奥林匹克竞赛金牌。

作者陆伊炀,现为清华大学姚班大二学生,目前在MIT CSAIL实验室实习,导师为何恺明,研究方向为计算机视觉与深度生成模型。高中时期他是物理竞赛生,曾获全国中学生物理竞赛金牌,此前也已以一作身份与何恺明合作发表论文。

核心作者黎天鸿,是何恺明课题组的博士后。他本科毕业于清华姚班,博士毕业于MIT,半年前那篇重要的《Back to Basics: Let Denoising Generative Models Denoise》论文的第一作者正是他。

论文的其他作者还包括MIT EECS的两位教授Yoon Kim、Jacob Andreas,以及何恺明本人。
参考链接:[1]https://arxiv.org/pdf/2605.10938




