真人级TTS语音合成系统:字级控制与毫秒级停顿技术

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
语音合成技术(TTS)近年来发展迅猛。如今,让AI流畅地朗读一段文字已非难事;真正的技术挑战在于,它能否像真人一样,精准掌控语句内部的节奏——该放缓时放缓,该停顿时停顿,该强调时能真正凸显出重点。
这正是当前语音合成技术发展的关键分水岭。在整体自然度和声音克隆方面,我们已经看到了显著进步。然而,当要求模型超越平铺直叙的朗读,对一句话内部的节奏进行有选择、有重点的精细编排时,许多系统的短板便暴露无遗。许多模型能够实现整体语速调整,或为整段话套用某种风格,但在需要局部精细调控的关键位置,往往仍采用“一刀切”的方式,难以实现真正意义上的局部可控。
恰恰是这种“局部”控制能力,在实际产品场景中至关重要。
试想这些场景:验证码播报时,数字之间是否需要刻意拉开间距以提升辨识度?导航提示中,“前方右转”这样的关键动作信息能否被单独凸显?在语言教学中,两个发音相近的单词能否通过节奏差异被清晰区分?甚至在故事讲述中,能否在关键词出现前预留半拍空白以酝酿情绪?这些需求,都无法通过简单地将整句话放慢来满足。
近期,华南理工大学的研究团队提出了一项名为MAGIC-TTS的新工作。这项研究首次在token级别上,同时实现了对字级时长和边界停连的精细控制,标志着真正意义上的局部可控语音生成取得了突破。

因此,这项研究的核心价值在于,它推动了一项过去难以稳定实现的能力:让语音合成模型不仅会“发声”,更开始学会“安排”一句话的内部节奏,同时确保合成音质和声音克隆的相似度不受损。
将MAGIC-TTS置于真实应用场景中审视,它有望率先改变以下三类任务。
第一类:高辨识度播报
这类任务的核心诉求并非“更自然”,而是“更不易听错”。研究以验证码播报为例:先为整句设定均匀的基准时长,然后刻意拉大数字分组间的停顿,最后再将每个数字本身的发音略微放慢。其效果并非整句话变慢,而是让用户先听清分组结构,再听清每个具体数字。这种处理思路,显然同样适用于订单号、取件码、地址、药品名称等高信息密度的播报场景。
地铁播报也遵循类似逻辑。研究者并未拖慢整句语速,而是将站点出现前的停顿做得更明显,同时将需要乘客注意的站名读得更重、更清晰。对于这类高实时性任务,节奏的准确性往往比声音是否足够“像真人”更具实用价值。
第二类:教学与纠错
研究展示了一个英文近音词纠正的案例。通过缩短前一个词、拉长后一个词,并在两者之间加入短暂停顿,模型让两个易混词之间的差异变得清晰可辨。这个例子的关键,不在于它能合成英文,而在于模型开始懂得利用“节奏”本身来辅助区分语义关系。
这类能力一旦成熟,将直接惠及外语学习、儿童跟读、口语训练等场景。因为教学需要的从来不是一台平铺直叙的朗读器,而是一个能够主动制造差异、突出重点的智能示范系统。
第三类:表达型语音
研究还演示了一个戏剧化场景:在句尾的关键词出现前,先预留一小段空白,再将最后一个词缓缓拉长。这个动作非常细微,但听感会立刻从“把句子读完”转变为“把情绪传递出来”。这表明,局部节奏控制不仅能提升信息清晰度,更开始触及叙事的张力和情感表现力。
过去,这类精细处理通常被认为是真人配音、导演调度或后期剪辑的专属领域。如今,TTS技术也开始向这个方向探索,为AI语音注入更多表现力。
为什么这项能力至关重要却难以实现?
首先,整句控制和句内控制是两回事。让一整段话慢一点,本质仍是全局调节;但让某个词多占几十毫秒、让某个边界多留一段停顿,则要求模型在局部位置精确地重新分配时间资源,技术难度更高。
其次,停顿控制和字时长控制的难度也不同。停顿更接近于在内容之间“插入空白”,而内容时长则直接涉及token内部声学信号的展开方式。前者像调整间距,后者则是改变内容本身的形态,后者通常更为复杂。
再者,局部控制越精细,对训练数据标注的边界准确性要求就越苛刻。如果在训练阶段,一个token的起止时间点本身就模糊不清,那么在推理时,无论想拉长它还是在它后面添加停顿,都会变得不可靠。
因此,这类问题真正卡住行业脖子的,往往不是缺乏想法,而是能否将其工程化为一个稳定、可靠、可应用于真实场景的模型。
方法:抓住三个底层环节
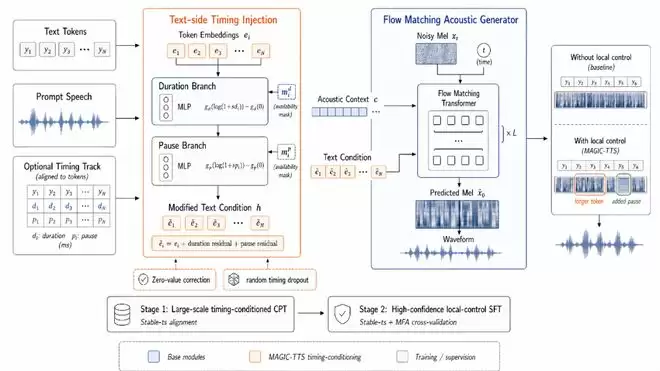
从方法层面看,MAGIC-TTS成功的关键在于抓住了三个更底层的技术环节。
第一,拆解一句话里的两种时间因素。 这项工作没有再将“节奏”作为一个模糊的整体感觉去学习,而是明确区分了“每个词要占多久”(内容时长)和“每个词之后要停多久”(边界停顿)。将这两件事拆解开来,等于承认了一句自然语音的节奏,本就不是一个总时长数字能够概括的。
第二,预先校准每个词的边界监督。 论文中一个关键的工程步骤是,先利用Stable-ts在总时长3万小时的大规模语音数据上构造token级时序标签进行持续预训练,再结合Stable-ts和MFA(Montreal Forced Aligner)进行交叉验证,筛除不可靠的样本。最终用于精细指令微调的高置信度子集时长为230.72小时。这一步至关重要,它确保了后续的精细控制建立在一个坚实、准确的数据基础之上。
第三,解决停顿控制对内容控制的干扰问题。 模型为每个位置编码了内容控制残差和停顿控制残差。但一个现实挑战是:自然语音中大多数字词是连读的,许多位置的停顿残差天然应接近于零。如果模型简单地用MLP编码这些停顿残差,可能会将不存在的停顿编码成有偏信号,导致整句语音中积累无意义干扰,从而削弱更难学习的内容时长控制效果。论文采用的零值校正机制,本质上就是在处理这个问题,确保不该有影响时尽量消除干扰。
与此同时,作者还专门进行了缺失控制条件下的鲁棒性训练。原因很实际:用户不可能每次都为一整句话提供精细到每个token的时序控制指令。如果一个系统只有在“满配”控制条件下才表现良好,那它就更像实验室演示,而非实际可用的能力。同时保住高质量的默认合成效果与灵活的局部调节能力,才更接近产品化的方向。
关键证据:不只是“会停”,更是“能稳控字”
这篇论文的数据结果中,最值得关注的并非停顿指标,而是内容时长的控制精度。
在显式提供token级内容时长和停顿条件后,每个字的内容时长平均绝对误差(MAE)从36.88毫秒大幅降低至10.56毫秒,相关性从0.588提升到0.918。停顿方面,MAE从18.92毫秒降至8.32毫秒,相关性从0.283提升至0.793。
为什么说内容时长指标更关键?因为“在边界停一下”相对容易理解和实现;但要把某个token本身说得更长一点,同时又不破坏整句话的自然流畅度,难度显然更高。因此,内容时长指标的大幅提升,比单纯的停顿跟随更能证明模型掌握了精细的节奏编排能力。
应用场景:哪些产品将最先受益?
如果这项技术能够顺利普及,以下几类产品将最先体验到其带来的变革。
最先受益的,依然是那些“听错一个字都麻烦”的高辨识度播报场景。 这包括验证码、订单号、地址、药品名、导航指令、车载提示等。比起声音是否拟人,这些场景更惧怕信息传递不清。过去许多系统只能依靠整体放慢语速来保底,但这往往牺牲效率,且对重点的突出效果有限。若能实现节奏的局部编排,系统就能将需要重点聆听的部分单独“拎”出来,提升信息接收的准确率。
第二批受益的将是教学与纠音领域。 儿童跟读、外语学习、示范朗读等场景,都需要一个善于示范“差异”的智能系统,而非仅仅把文本念完。谁能更清晰地将停连、重音、对比关系演示出来,谁就在这类教育产品中占据了核心优势。
再往后,是表达型语音的广阔天地。 数字人、剧情化配音、音频内容生成、有声故事讲述等方向,对局部节奏和情感层次的要求更高。一旦相关能力成熟,所带来的产品体验提升和表现力丰富度也将最为显著。
小结
MAGIC-TTS的核心价值,在于将语音合成技术从“把话念自然”的阶段,向前推进到了“能精细安排句内节奏”的新层次。如何同时实现对token级字时长和边界停顿的稳定、可靠控制,让现实应用中的关键信息能被更清晰、更有表现力地传达,这将是语音合成技术下一阶段演进需要重点攻克的方向,也为更智能、更拟人化的AI语音交互打开了新的可能性。
相关攻略

对正义、责任与信念的追寻从未停止 《寒战1994》海报。 出品方供图 历史的长河里,总有一些年份看似波澜不惊,却在无声处,悄然转动了命运的齿轮。 回望二十世纪九十年代上半叶的香港,表面秩序井然,但人心的流向与城市的未来,已然开始微妙的偏移。那些被反复试探的边界,共同编织成一种隐而不发的张力,弥漫在空

导读:Jacob Elordi的脚趾离锋利刀刃只有几厘米——这场戏的演员亲述现场有多悬。 【现场】刀刃贴肤的实拍 《亢奋》第三季那场令人屏息的婚礼戏里,有个细节你可能没注意到:演员需要手持一把真实的指甲剪,无限逼近Jacob Elordi的脚趾来完成特写。事后回忆起来,操作者依然心有余悸——道具组提

CBS拓展「消防+警长」双剧宇宙,正式布局医疗赛道 看来,CBS的“应急响应宇宙”版图正迎来新一轮扩张。一个暂未命名的全新医疗剧项目,目前已进入早期筹备阶段。其最大亮点在于,它将与已获得稳定收视的《烈焰国度》(Fire Country)以及今年3月首播即夺得当晚收视冠军的《警长国度》(Sheriff

HBO Max服务器负载飙升23%:一部医疗剧如何用单集引爆观众热情 9点档的叙事革命 《匹兹堡医护队》(The Pitt)第二季第15集“9:00 P M ”,选择了一个颠覆传统医疗剧套路的独特视角。它没有聚焦于急诊室常见的生死急救,而是将镜头对准了医院日常中极易被忽略的环节——医护交接班时刻,深

谍战剧的“硬核竞技场”与《特殊使命》的信仰重量 说起谍战剧,那一直是影视界的“硬核竞技场”,比拼的不仅是情节的悬疑,更是人性与信仰的深度。《特殊使命》便是这样一部作品,它通过巩向光这个人物,将信仰与责任的千钧之重,展现得淋漓尽致。故事始于北平,我党同志巩向光受组织派遣,潜入国民党内部。他的任务很明确
热门专题







热门推荐

当RPA机器人面临复杂决策场景时,企业通常可以采取以下几种经过验证的有效策略来应对,确保自动化流程的顺畅与准确。 借助人工智能技术 一种广泛应用的解决方案是将RPA与人工智能技术深度融合,特别是机器学习与自然语言处理。通过集成AI的预测分析与模式识别能力,RPA能够处理非结构化数据并应对模糊的业务情

当智能制造与人工智能技术深度融合,这不仅是两种前沿科技的简单叠加,更是一场旨在重塑全球制造业竞争格局的系统性变革。其核心目标在于,通过深度嵌入人工智能等前沿技术,全面提升制造业的智能化水平、生产效率与国际竞争力。那么,如何有效推进这场深度融合?以下六大关键策略构成了清晰的行动路线图。 1 加强关键

对于已经部署了RPA的企业而言,项目上线远不是终点。要让自动化投资持续产生价值,对机器人性能进行持续优化是关键。这就像保养一台精密的机器,定期维护和调校,才能确保其长期高效、稳定地运行。 那么,具体可以从哪些方面着手呢?以下是一些经过验证的优化方向。 一、并行处理与任务分解 首先,看看任务执行本身。

面对海量数据源的高效抓取需求,分布式数据采集架构已成为业界公认的核心解决方案。该架构通过精巧的设计,协调多个采集节点并行工作,并将数据汇聚至中央处理单元,最终实现数据的集中分析与深度洞察。这套系统看似复杂,但其核心原理可拆解为几个关键组件的协同运作。 一、系统核心组成 一套典型的分布式数据采集系统,

Gate io平台活动页面多样,新手易混淆注册奖励、邀请与正常开户页。本文梳理三者核心区别:注册奖励页通常含专属链接与限时福利;邀请页强调社交分享与返利机制;正常开户页则提供基础功能与安全验证。清晰辨识有助于用户高效参与活动,避免错过权益或操作失误,提升在Web3领域的入门体验。