就在昨天,百度正式发布了其新一代基础大模型——文心大模型5.1版本。此次发布最引人瞩目的亮点之一,是其采用了创新的“多维弹性预训练”技术。据官方披露,该模型仅消耗了业界同规模模型约6%的预训练成本,便实现了基础模型效果的显著领先,并成功登顶LMArena大模型竞技场搜索能力榜单的国内首位。
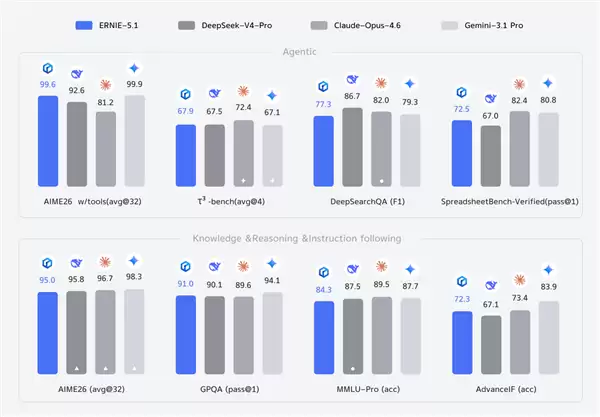
从多项权威基准测试的综合表现来看,文心大模型5.1实现了全方位的性能跃升。特别是在智能体(Agent)能力、复杂知识理解、多步逻辑推理以及深度搜索等核心维度上,提升尤为突出。具体而言,其Agent能力已超越DeepSeek-V4-Pro;在创意写作与内容生成方面,达到了与Gemini 3.1 Pro同等的水平;而在逻辑推理能力上,则已逼近全球顶尖的闭源大模型。

搜索能力登顶,成本控制成关键
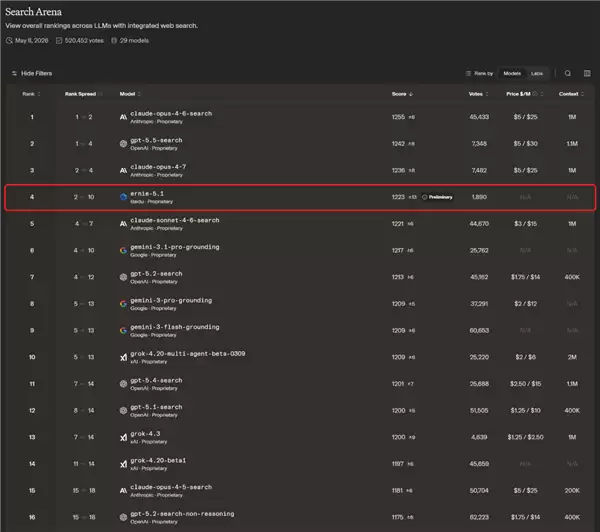
根据LMArena大模型竞技场的最新排名数据,文心5.1以1223分的成绩位列搜索能力榜国内第一、全球第四。值得关注的是,它也是该榜单上唯一入围的国产大模型。大模型的搜索能力,本质上是其快速检索、精准整合多源异构信息并生成高质量答案的综合体现。这项能力越强,模型输出的答案一致性与可靠性就越高,在智能内容创作、AI助手、企业知识库管理以及更复杂的自动化智能体应用场景中,其实际应用价值也就越大。
事实上,这并非文心大模型首次在LMArena榜单上取得佳绩。此前,文心5.0系列模型就已在文本理解与视觉理解榜单中多次亮相,稳居国产模型性能的第一梯队。更早之前,在4月30日,文心5.1的Preview预览版曾以1476分的高分登上文本榜国内榜首,超越了包括GPT-5.5、DeepSeek-V4-Pro在内的多款主流模型,成为当时榜单前十五名中唯一的国产代表。
“多维弹性预训练”技术立功
文心5.1综合能力实现大幅跨越的核心驱动力,正是前文提及的“多维弹性预训练”技术。这项技术在文心5.0发布时被首次提出,其最大优势在于能够实现“一次训练,产出多种参数规模的模型”,从而极大地提升了模型训练的效率与部署的灵活性。
作为该技术的一项关键阶段性成果,文心5.1完整继承了文心5.0的海量知识储备,同时在模型架构上进行了大幅优化——模型总参数量被压缩至约原版的三分之一,激活参数量则压缩至约二分之一。正是得益于这种“更精巧”的模型设计,文心5.1才能以仅约6%的业界同规模预训练成本,实现基础能力的全面领先。简而言之,百度通过技术创新,用更少的计算资源和成本,打造出了性能更强大的AI模型。
目前,文心大模型5.1已在百度千帆模型广场与文心一言平台同步上线,正式面向广大企业客户与开发者开放体验。此外,一个值得业界期待的重要节点是:Create 2026百度AI开发者大会定于5月13日至14日在北京举行。届时,百度预计将围绕文心大模型生态,发布其在人工智能核心技术突破与产业应用落地方面的最新战略与成果。




