在开发过程中,我们经常需要对图片进行文字识别,例如身份证识别、发片识别、文档扫描等场景。使用 OCR(Optical Character Recognition,光学字符识别)API 可以快速实现这些功能。本文将以 Python 为例,带你完成 OCR 文字识别 API 接入全过程,并提供在线体验和实用优化建议。
一、准备工作
万事开头先准备。接入任何API,第一步都离不开获取凭证和配置环境。
注册 OCR API 服务
这里我们以石榴智能OCR接入API为示例。注册流程通常很简单,完成后你会获得两个关键信息:API Key 和 Secret Key(或AppCode)。请务必妥善保管,它们相当于访问服务的“钥匙”。
安装 Python 依赖库
接下来,在Python环境中安装必要的库。打开终端,执行以下命令:
pip install requests pillow
requests:这是发送HTTP请求的利器,几乎是调用API的标配。Pillow:一个强大的图像处理库,用于图片的预处理(如调整尺寸、格式转换),属于可选但推荐安装的工具。
准备测试图片
手边准备一张清晰的测试图片至关重要。可以是身份证、票据、文档扫描件,或者任何包含清晰文字的图片。图片质量会直接影响初次测试的体验和信心。
二、API 请求方式简介
在动手写代码之前,先花几分钟了解API的基本请求格式,能让你事半功倍。
OCR API 通常需要发送以下参数:
image:图片数据,通常以 Base64 编码字符串形式提供,或者直接填写一个可公开访问的图片URL。type:指定识别类型,例如id_card(身份证)、invoice(发片)、general(通用文字识别)等,这有助于引擎进行针对性优化。language:可选参数,用于指定需要识别的语言,实现多语言混合识别。
示意请求格式:
让我们以一个通用OCR接口为例,拆解其请求构成。
请求URL:
POST http(s)://ocr-api.shiliuai.com/api/advanced_general_ocr/v1
请求方式: POST
请求头
| 参数 | 类型 | 说明 |
|---|---|---|
| Authorization | string | 'APPCODE ' + 您的AppCode |
| Content-Type | string | application/json |
请求体
| 参数 | 是否必填 | 类型 | 说明 |
|---|---|---|---|
| image_base64 | 选填 | string | 图片Base64;与image_url二选一;像素[15,8192];小于20M |
| image_url | 选填 | string | 图片URL;与image_base64二选一;像素[15,8192];小于20M |
| is_line | 选填 | bool | 是否为单行文字,默认False |
返回信息:
调用成功与否,全看返回的数据结构。一份标准的响应通常包含状态码、消息和核心数据。
返回结构
| 参数名 | 类型 | 说明 |
|---|---|---|
| code | int | 错误码 |
| msg | string | 错误信息(英文) |
| msg_cn | string | 错误信息(中文) |
| success | bool | 识别是否成功 |
| image_id | string | 请求图片ID |
| request_id | string | 唯一请求ID |
| data | data | 具体看下面 |
以下是返回示例,重点关注data字段的结构:
data 成功示例:
data = {
"content":
[
{
"text": "你好", // string, 文字内容
"prob": 0.995, // float, [0, 1], 文字内容置信度
"keypoints": [ // list, 文字区域四个角的位置,以文字的左上角为起点,按顺时针顺序排列,单行文字没有此项
{"x":50, "y":20},
{"x":150, "y":20},
{"x":150, "y":60},
{"x":50, "y":60}
]
},
......
]
}
data 失败示例:
data = {}
三、Python 接入示例
理论清晰了,现在来看实战代码。下面这段Python示例,清晰地展示了从图片到识别结果的完整链路。
# API文档:https://market.shiliuai.com/doc/advanced-general-ocr
# -*- coding: utf-8 -*-
import requests
import base64
import json
# 请求接口
URL = "https://ocr-api.shiliuai.com/api/general_ocr/v1"
# 图片转base64
def get_base64(file_path):
with open(file_path, 'rb') as f:
data = f.read()
b64 = base64.b64encode(data).decode('utf8')
return b64
def demo(appcode, file_path):
# 请求头
headers = {
'Authorization': 'APPCODE %s' % appcode,
'Content-Type': 'application/json'
}
# 请求体
b64 = get_base64(file_path)
data = {"image_base64": b64}
# 发送请求
response = requests.post(url=URL, headers=headers, json=data)
content = json.loads(response.content)
print(content)
if __name__=="__main__":
appcode = "你的APPCODE"
file_path = "本地图片路径"
demo(appcode, file_path)
将代码中的appcode和file_path替换成你自己的信息,运行一下,就能看到OCR识别的原始返回结果了。
四、识别效果示例
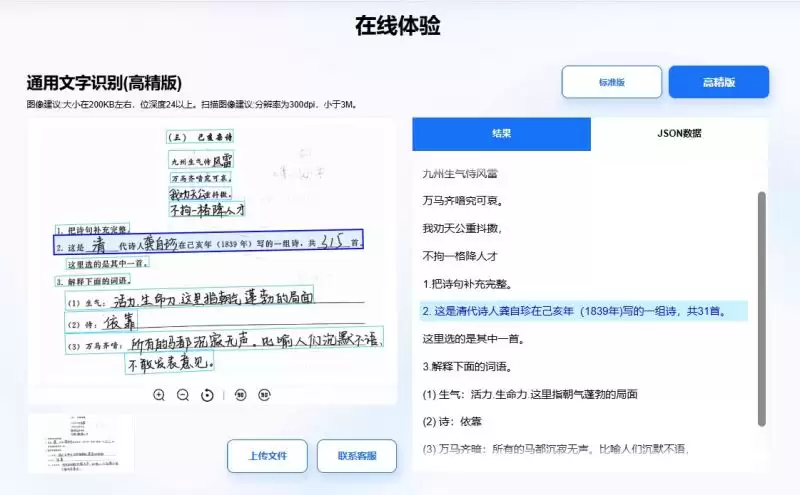
上图展示了一个典型的识别结果可视化效果。可以看到,OCR引擎不仅提取出了文字,还能精准定位每个文字块在图片中的位置,这对于后续的结构化信息提取非常有帮助。
五、常见优化技巧
接入成功只是第一步,要想在生产环境中获得稳定、高精度的识别效果,有几个技巧值得关注。
清晰图片优先
这是最根本的一条。模糊、倾斜、反光或对比度低的图片,识别率自然会打折扣。在调用API前,不妨用Pillow等库做个简单的预处理,比如调整亮度、对比度或进行锐化。
裁剪或分区识别
对于身份证、发片这类有固定版式的图片,直接全图识别的效果可能不如分区识别。可以先裁剪出姓名、号码等关键区域,再分别调用API,精度往往会显著提升。
批量或异步处理
如果需要处理大量图片,同步调用会导致程序长时间等待。此时,可以考虑使用消息队列或多线程/异步编程模型,并发地调用API,能极大提升整体处理效率。
错误处理
一个健壮的程序必须考虑异常情况。网络超时、API返回非成功状态码、识别结果为空等,都需要在代码中进行妥善处理,例如加入重试机制或友好的错误日志记录。
六、在线体验与多语言文档
- 在线体验:如果不确定效果,不妨先通过官方提供的在线Demo体验一下:
https://market.shiliuai.com/general-ocr
- 多语言支持:官方文档通常不止提供Python示例,还涵盖了Ja va、PHP、C#等主流语言的调用代码,方便不同技术栈的开发者集成。
- 丰富接口:除了通用文字识别,这类平台往往还提供身份证识别、发片识别、银&行卡识别等垂直场景的专用接口,针对性更强,效果也更好。
七、总结
回顾一下,通过OCR API集成文字识别功能,其实可以分解为几个清晰的步骤:
- 注册服务并获取访问密钥。
- 准备Python环境并安装必要依赖库。
- 理解API的请求/响应格式,并编写调用代码。
- 根据返回结果处理数据,并应用优化技巧提升体验。
- 参考官方文档和在线工具进行调试与验证。
总的来说,利用成熟的OCR API服务,开发者能够快速、经济地将强大的文字识别能力集成到自己的网站、桌面应用或移动端应用中,轻松应对身份证信息录入、票据报销、文档电子化等多种业务场景,从而专注于核心业务逻辑的开发。
希望这份指南能帮助你顺利完成接入。关于更深入的参数调优、性能压测或私有化部署等问题,可以进一步查阅相关的技术文档和社区讨论。
您可能感兴趣的文章:
- Python调用OCR API的避坑指南
- python 3调用百度OCR API实现剪贴板文字识别
- 从入门到验证码识别详解Python OCR技术实战指南
- Python工程化实践之OCR接口调用的超时与重试机制
- Windows和Linux下使用Python搭建一个图片OCR工具




