前言
在数据分析的实际工作中,我们几乎总会面临一个普遍且关键的挑战——数据缺失问题。简而言之,它指的是数据集中某些特征或字段的值存在不完整或空缺的情况。
有趣的是,这种“空缺”在不同技术语境下的表现形式各异:在数据库系统中常被称为 NULL,在 Python 基础类型中表现为 None,而在 Pandas 或 NumPy 的数据结构中,则统一标识为 NaN(Not a Number)。
这里需要明确一个重要的概念区分:缺失值并不等同于空字符串。空字符串是一个具有明确类型的字符串对象,而缺失值代表的是数据的“真空”状态,其本身不具备数据类型。
接下来,我们将系统性地讲解,如何利用强大的 pandas 数据分析库,高效地完成缺失值的检测、统计与科学处理。
一、缺失值的检测与统计
处理缺失值的第一步,是实现精准的“问题定位”。您必须清晰掌握数据中哪些字段存在缺失,以及缺失的严重程度如何。这一步的量化分析是整个数据清洗流程的基石。
Pandas 为此提供了两把利器:isnull() 用于精准识别缺失值,notnull() 则用于标记非缺失值。两者均返回布尔类型(True 或 False)的结果。我们以下面加载的数据集为例进行演示:
import pandas as pd
df =pd.read_excel('sass.xlsx') # 读取数据
print(df)
查看每列是否有缺失值
想要快速评估各数据列的健康状况?df.isnull().any() 方法非常高效。在返回结果中,True 明确指示该列存在至少一个缺失值,False 则表示该列数据完整无缺。
print('每列是否存在缺失值:\n', df.isnull().any()) # True表示有缺失,False表示无缺失
显示数据缺失情况、位置
如果需要精确定位缺失值具体隐藏在哪些数据单元格,直接使用 df.isnull() 会得到一张清晰的“热力图”。输出结果中,True 精准标记了每一个缺失值的位置。
print('数据缺失值查看:\n', df.isnull()) # True表示缺失,False表示未缺失
统计每列缺失值个数
仅知道位置还不够,我们需要对问题的规模进行量化。将 sum() 聚合函数与 isnull() 或 notnull() 结合,可以轻松计算出每一列缺失值的具体数量,从而直观把握数据缺失的分布特征。
print('每列数据缺失的个数:\n', df.isnull().sum())
提示:notnull() 的用法与 isnull() 完全对称,仅逻辑相反,常用于统计有效数据的数量。
二、缺失值的处理
直接删除缺失值(删除法)
这是最直观的解决方案:直接将包含缺失值的行或列从数据集中移除。这种方法虽然简单直接,但需要谨慎使用,因为它会直接导致样本量减少或特征维度降低,可能损失有价值的信息。因此,是否采用删除法,必须基于数据缺失的机制和分析的具体目标来综合判断。
Pandas 中的 dropna() 方法专门用于执行此操作,其核心语法如下:
DataFrame.dropna(self,axis=0,how='any',thresh=None,subset=None,inplace=False)
| 参数 | 释义 |
| axis | 接收0或1,表示轴向,0表示行,1表示列。默认为0 |
| how | 接收特定string,表示删除形式。取值为“any”,表示只要有缺失值就执行删除操作,取值为“all”,表示当且仅当全部为缺失值时才执行删除操作。默认为“any” |
| subset | 接收array,表示根据去重的行/列条件。默认为None,所有行/列 |
| inplace | 接收布尔值,代表操作是否对原数据生效,默认为False |
我们使用这份原始数据(df1)来演示具体操作:
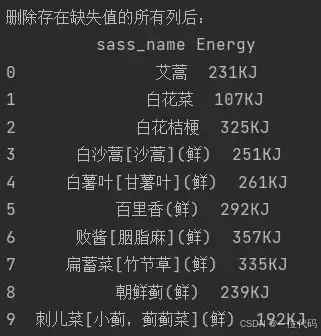
实例1:删除存在缺失值(NaN)的所有列
df2 =df1.dropna(axis=1)
print('删除存在缺失值的所有列后:\n', df2)
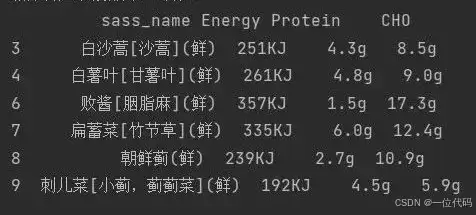
实例2:删除特定字段存在缺失值(NaN)的行。
例如,我们仅希望删除‘Protein’(蛋白质)或‘CHO’(碳水化合物)这两个关键营养字段中任一存在缺失值的记录行。
df3 = df1.dropna(subset=['Protein', 'CHO'])
print('删除特定字段为空的行:\n', df3)
替换补齐缺失值
相较于直接删除,替换补齐是实践中更为常用且灵活的缺失值处理策略。其核心思路是,利用合理的估计值来填充数据中的空白部分,以保持数据集的完整性。
填充值的选择需根据数据类型决定:
- 对于数值型特征,通常采用均值、中位数或众数等能够代表数据集中趋势的统计量进行填补。
- 对于类别型(分类型)特征,则常使用该特征的众数(即出现频率最高的类别)进行填充。
当然,依据具体业务场景,也可以采用前向/后向填充、特殊值标记(如用-1或-999表示缺失)、甚至使用机器学习预测模型进行填充等高级方法。
Pandas 的 fillna() 方法为此提供了全面的功能支持,其基本语法如下:
DataFrame.fillna(value=None,method=None,axis=1,inplace=False,limit=None)
| 参数 | 释义 |
| value | 接收dict、DataFrame等类型数据,表示用来替换缺失值的值。无默认值 |
| method | 接收特定string:(1)取值为“backfill”或“bfill”,表示使用下一个非缺失值来填补缺失值。(2)取值为“pad”或“ffill”,表示使用上一个非缺失值来填补缺失值。默认为None |
| axis | 接收0或1,表示轴向。默认为1 |
| inplace | 接收布尔值,代表操作是否对原数据生效,默认为False |
| limit | 接收int,表示填补缺失值个数上限,超过则不进行填补。默认为None |
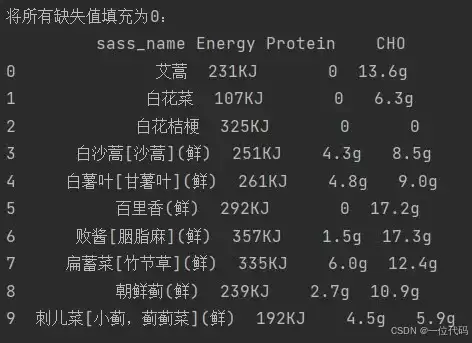
继续使用上面的示例数据(df1),这次我们尝试将所有缺失值(NaN)统一填充为数字0:
df4 = df1.fillna(value=0)
print('将所有缺失值填充为0:\n', df4)
注意:此处将所有缺失值填充为0,仅为演示 fillna() 方法的基本用法。在实际的数据分析与建模项目中,必须结合数据的分布特性、缺失原因以及后续分析目标,审慎选择最科学、最合理的填充策略或填充值,这是确保数据质量和分析结果可靠性的关键。
以上便是关于在 pandas 中进行数据缺失值处理的全流程教学,涵盖了从检测、统计到删除与填充的完整解决方案。熟练掌握这些技巧,将使您能够更加专业、高效地应对数据分析中的各类数据完整性问题。




