在自动化文档处理流程中,PDF 文件可能因导出错误、内容重复或格式转换问题而包含多余页面。手动删除不仅耗时,而且处理大批量文件时容易导致文件损坏。
通过 C# 调用 .NET 组件实现程序化删除 PDF 页面,可以将功能无缝集成到桌面应用、Web 服务中,实现自动化、批量化处理。本文演示如何使用免费库 Free Spire.PDF for .NET 删除 PDF 文件中的单个或多个页面。
1. 安装
打开 Visual Studio,进入 工具 → NuGet 包管理器 → 程序包管理器控制台,执行:
Install-Package FreeSpire.PDF
或者,在 管理 NuGet 程序包 界面中搜索 FreeSpire.PDF 并安装最新版本。
2. 加载 PDF 文档
一切操作都始于加载文档。Free Spire.PDF 的 PdfDocument 类提供了多种加载方式,以适应不同的应用场景:
using Spire.Pdf;
// 从文件路径加载
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(@"C:\input.pdf");
// 从流加载
using (FileStream fs = new FileStream(@"C:\input.pdf", FileMode.Open))
{
pdf.LoadFromStream(fs);
}
// 从字节数组加载
byte[] data = File.ReadAllBytes(@"C:\input.pdf");
pdf.LoadFromStream(new MemoryStream(data));
这里有个细节需要注意:LoadFromFile 方法内部会检查文件是否存在,若文件缺失则会抛出 FileNotFoundException。因此,在调用前使用 File.Exists 进行预判,能让你的程序更加健壮。
3. 删除单个 PDF 页面
关键规则:这里有一个程序员和普通用户之间常见的“认知鸿沟”——Free Spire.PDF 的页面索引是 从0开始(0-based)的,而我们日常所说的页码则是 从1开始(1-based)的。
删除前,必须完成这个简单的转换:
目标页码(1-based) - 1 = 代码索引(0-based)
// 示例:删除第 3 页,对应索引 2 pdf.Pages.RemoveAt(2);
返回值和影响:RemoveAt 方法没有返回值。删除操作完成后,后续页面的索引会自动向前移动一位。举个例子,一个原本有5页的文档,删除索引为2的页面后,原来索引为3的页面就会变成新的索引2。
4. 删除多个 PDF 页面
删除多页时,情况就稍微复杂一些了。如果直接按顺序删除靠前的页面,会导致后续页面的索引发生变化,从而引发“索引越界”的错误。
最佳方案其实很简单:先将需要删除的页码转换为索引,然后按照降序进行删除。这样就能确保每次删除操作的目标索引都是稳定、准确的。
以下示例展示了如何使用我们熟悉的1-based页码,来删除第1页和第3页:
// 定义需要删除的页码(1-based,直接填日常看到的页码即可)
int[] pagesToDelete = new int[] { 1, 3 };
// 转换为 0‑based 索引并降序排列
var deleteIndices = pagesToDelete
.Select(page => page - 1)
.Where(index => index >= 0 && index < pdf.Pages.Count) // 过滤无效索引
.OrderByDescending(index => index);
// 循环删除页面
foreach (int index in deleteIndices)
{
pdf.Pages.RemoveAt(index);
}
注意: 在转换和删除前,务必使用 pdf.Pages.Count 来验证页码的有效性,避免程序因无效输入而崩溃。
效果预览:
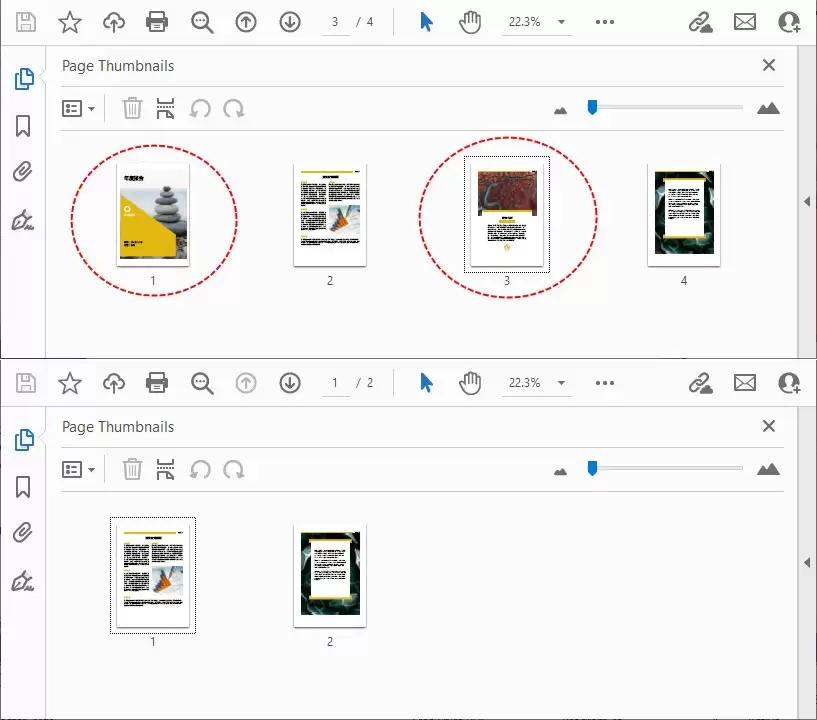
5. 保存修改后的 PDF 文件
页面删除操作完成后,数据还在内存中,必须调用 Sa veToFile 方法才能将修改持久化到磁盘。这个方法支持覆盖原文件或生成新文件:
// 保存到新文件
pdf.Sa veToFile("output.pdf");
// 覆盖原文件(谨慎使用)
pdf.Sa veToFile(@"C:\input.pdf");
// 保存到流
using (FileStream fs = new FileStream(@"output.pdf", FileMode.Create))
{
pdf.Sa veToStream(fs);
}
pdf.Close();
6. 完整可运行代码(含异常处理)
将上述所有功能模块整合起来,并加入完善的异常捕获机制,就能得到一个健壮、可直接运行的示例。它能妥善处理文件损坏、页码无效、权限不足等各种意外场景:
using System;
using System.Linq;
using System.IO;
using Spire.Pdf;
class PdfPageDeleter
{
static void Main(string[] args)
{
string inputPath = @"C:\docs\input.pdf";
string outputPath = @"C:\docs\output.pdf";
int[] pagesToDelete = { 2, 4 }; // 1‑based: 删除第 2 页和第 4 页
try
{
using (PdfDocument pdf = new PdfDocument())
{
// 检查文件是否存在
if (!File.Exists(inputPath))
{
Console.WriteLine($"文件不存在: {inputPath}");
return;
}
pdf.LoadFromFile(inputPath);
int originalPageCount = pdf.Pages.Count;
Console.WriteLine($"原始页数: {originalPageCount}");
// 过滤有效页码
var indices = pagesToDelete
.Select(p => p - 1)
.Where(i => i >= 0 && i < originalPageCount)
.OrderByDescending(i => i)
.ToList();
if (indices.Count == 0)
{
Console.WriteLine("没有有效的页码需要删除。");
return;
}
foreach (int index in indices)
{
pdf.Pages.RemoveAt(index);
}
Console.WriteLine($"删除后页数: {pdf.Pages.Count}");
pdf.Sa veToFile(outputPath);
Console.WriteLine($"已保存到: {outputPath}");
}
}
catch (System.IO.IOException)
{
Console.WriteLine("错误:PDF 文件被其他程序占用或无文件读写权限!");
}
catch (Exception ex)
{
Console.WriteLine($"操作失败: {ex.Message}");
}
}
}
7. 常见异常处理
在实际开发中,总会遇到一些“意外”。下表总结了几个常见的异常场景及其处理逻辑,可以直接套用:
| 场景 | 处理方式 |
|---|---|
| 页码超出范围 | 通过 index < pdf.Pages.Count 过滤无效索引,避免报错 |
| 空 PDF 文件 | 判断 pdf.Pages.Count == 0,直接终止操作 |
| 文件损坏 / 无法读取 | 使用 try-catch 捕获加载异常 |
| 删除全部页面 | 免费库支持该操作,最终会生成一个空白 PDF 文件 |
| 文件权限不足 | 捕获 IOException,提示用户管理员权限运行程序 |
8. 页面集合操作
实际上,PdfDocument.Pages 属性返回的是一个 PdfPageCollection 对象,它提供了丰富的页面管理方法。除了删除,你还可以:
- 使用
Count属性获取总页数。 - 调用
Insert(int index)在指定位置插入新页面。 - 调用
Add()在文档末尾追加页面。
更进一步,如果需要实现条件删除(例如删除所有包含“机密”关键词的页面),可以结合 PdfTextFinder 来实现:
using Spire.Pdf.Texts;
PdfTextFinder finder = new PdfTextFinder(pdf.Pages[0]);
var found = finder.Find("机密"); // 返回文本位置列表
至此,从删除单页、多页到基于条件的智能删除,一套完整的 PDF 页面管理方案已经清晰呈现。借助 Free Spire.PDF for .NET,你可以轻松将这些功能集成到自动化工作流中,彻底摆脱对 Adobe Acrobat 等外部软件的依赖。




