Ask On Data- 基于人工智能的开源聊天式ETL工具
什么是Ask On Data?
简单来说,Ask On Data是一款用“聊天”就能搞定数据工作的工具。它专为数据工程领域打造,核心卖点就两个字:省心。你不再需要面对复杂的代码,只需用简单的英文描述你的需求——无论是想把数据从一个地方挪到另一个地方,还是想清洗一下脏数据,甚至想直接做些初步分析,直接告诉它就行。
这背后,是自然语言处理和生成式AI在驱动。它把自己定位为一款具备“自主能力”的工具,目标很明确:打破技术壁垒,让哪怕没有编程背景的人,也能真正用起数据来。数据科学家和工程师能借此提升效率,而对业务分析师等角色来说,这可能是打开数据宝库的一把新钥匙。
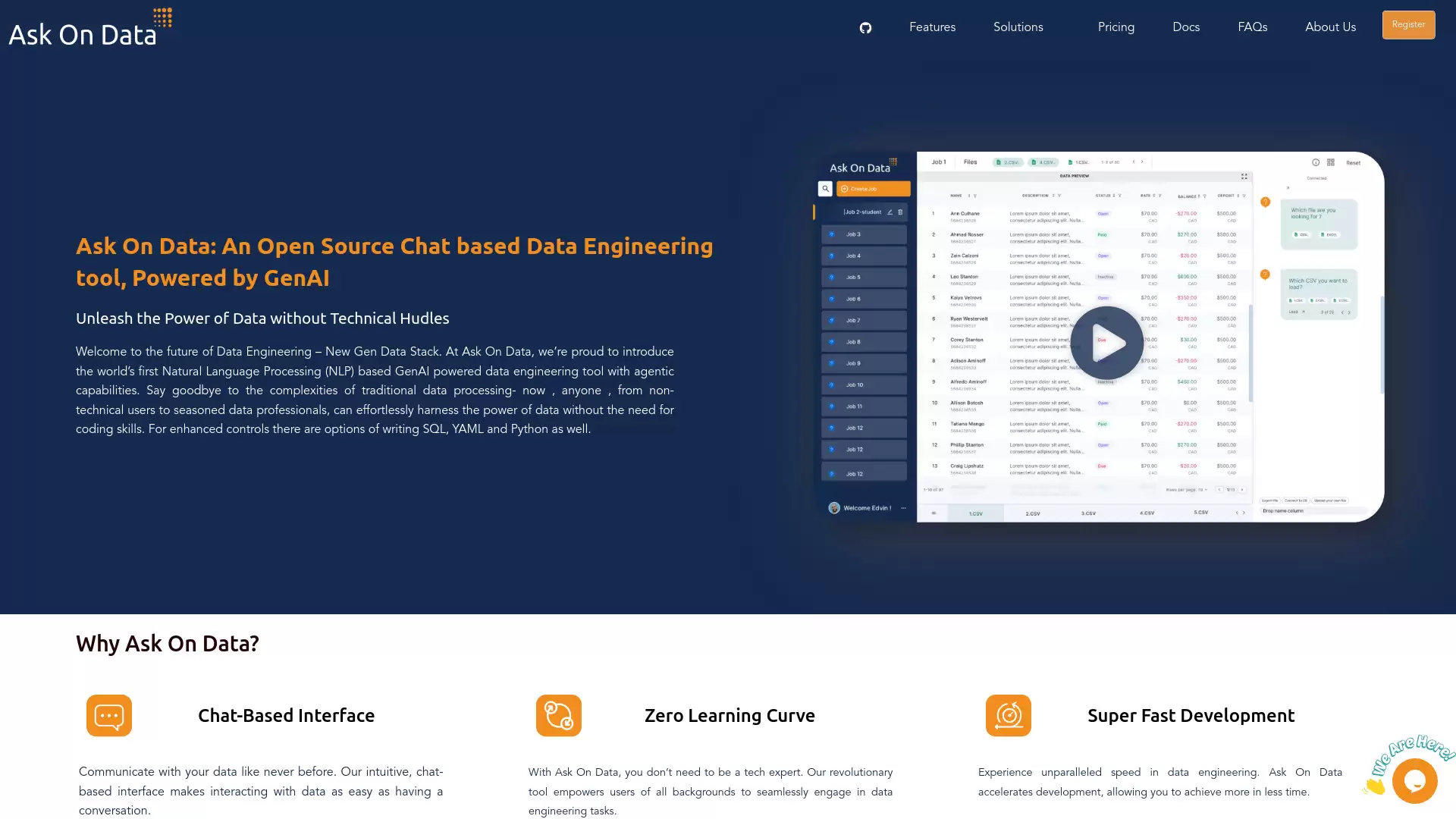
如何使用 Ask On Data?
用法相当直观。整个过程就像和一个懂数据的助手对话。你在聊天界面里,用平实的英语提出要求,比如“把上周的销售数据从数据库A同步到数据仓库B,并过滤掉无效订单”。
接下来,人工智能会解读你的意图,并将其“翻译”成一套可执行的操作步骤,也就是我们常说的数据管道。更妙的是,这些由对话生成的任务,还能被系统地编排起来,设定好运行时间,实现自动化调度。从对话到可调度任务,无缝衔接。
Ask On Data 的核心功能
聊了这么多,它到底能干什么?我们来看看它功能清单里的几个亮点:
聊天式界面 & 零学习曲线
这两点其实是同一枚硬币的两面。交互方式决定了入门门槛。因为采用自然语言对话,用户几乎不需要专门学习如何使用这个工具本身,注意力可以完全放在要解决的数据问题上。
快速开发 & 数据管道掌握
传统的数据管道开发,写代码、调试、测试,周期不短。现在,通过聊天快速生成并验证管道逻辑,开发速度的提升是显而易见的。同时,你依然对整个数据流程拥有完整的掌控力。
云端托管服务 & 经济实惠
它提供云托管服务,这意味着你不需要操心底层基础设施的维护。结合其开源特性,通常在成本控制上也会更加灵活,为不同规模的团队提供了高性价比的选择。
操作历史和撤销功能 & 数据预览
这是保证操作安全和信心的关键。每一步操作都有记录,方便回溯和审计;“撤销”功能让你可以大胆尝试。而在执行前或执行后,能够预览数据结果,确保了过程的透明和可控。
任务调度 & 代码控制 & 数据源
自动化是数据工程的归宿。生成的任务可以按计划定时执行。对于进阶用户,它可能也保留了代码层面的控制接口。同时,它需要能够连接多种多样的数据源,这是其发挥作用的底层前提。
对这款工具感兴趣?你可以访问其官网了解更多详情:https://AskOnData.com
热门专题







热门推荐

比特币匿名交易指南:原理、方法与关键注意事项 提到比特币,很多人第一反应是“匿名”。但真相是,比特币交易在区块链上公开记录,其本质是“化名”而非完全匿名。这意味着,只要采取恰当的方法,完全可以将交易隐私提升一个层级。本文将系统梳理实现比特币匿名交易的几种实用方法,并为你提供相关可信工具的官方获取途径

PowerLawGLM:法律领域的AI“专家” 在人工智能大模型深刻变革各行各业的今天,法律这一专业壁垒高、知识体系复杂的领域,也迎来了其专属的智能解决方案。由幂律智能与智谱AI联合推出的PowerLawGLM,是一款拥有千亿级参数、专为中文法律场景深度优化的垂直大模型。它本质上是一位经过海量法律文

新SSR比斯塔天赋可叠加“蔷薇花刺”,三层后目标无法复活,有效克制副本复活机制。其技能多为全体伤害,适合PVP竞技场。闪避可减敌怒气,暴击能回复生命,兼具续航与干扰能力。终结技提升闪避,配合额外魂玉实现连招。奥义击倒目标后可回血,增强生存能力。

手游《代号:逍遥游》即将上线,以“选择”为核心玩法。玩家将在宏大仙侠世界中,面对飞升或逆天等不同道路,通过自身决策破解宿命迷局,体验多线命运走向。

在《方舟:生存进化》中,探险者笔记是揭示世界秘密的关键物品。可通过探索地图角落、完成特定任务、与NPC互动、寻找隐藏地点以及参与游戏内特殊事件等多种途径获取。收集过程融合了探索、解谜与社交,集齐笔记不仅能获得经验加成,更能深入理解游戏世界的背景与故事。