Textraction.ai- 基于 AI 的文本解析器
什么是AI Textraction?
简单来说,AI Textraction 是一个相当给力的AI文本解析工具。它的核心任务,就是帮你从那些杂乱无章的非结构化文本里,精准地“挖”出你想要的特定信息。不管你是想找具体的数值,比如价格、日期、人名、邮箱或电话号码,还是想理解文本的深层含义,像主要话题、问题诊断或是客户的核心诉求,它几乎都能搞定——只要你能描述清楚,它就能给你提取出来。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
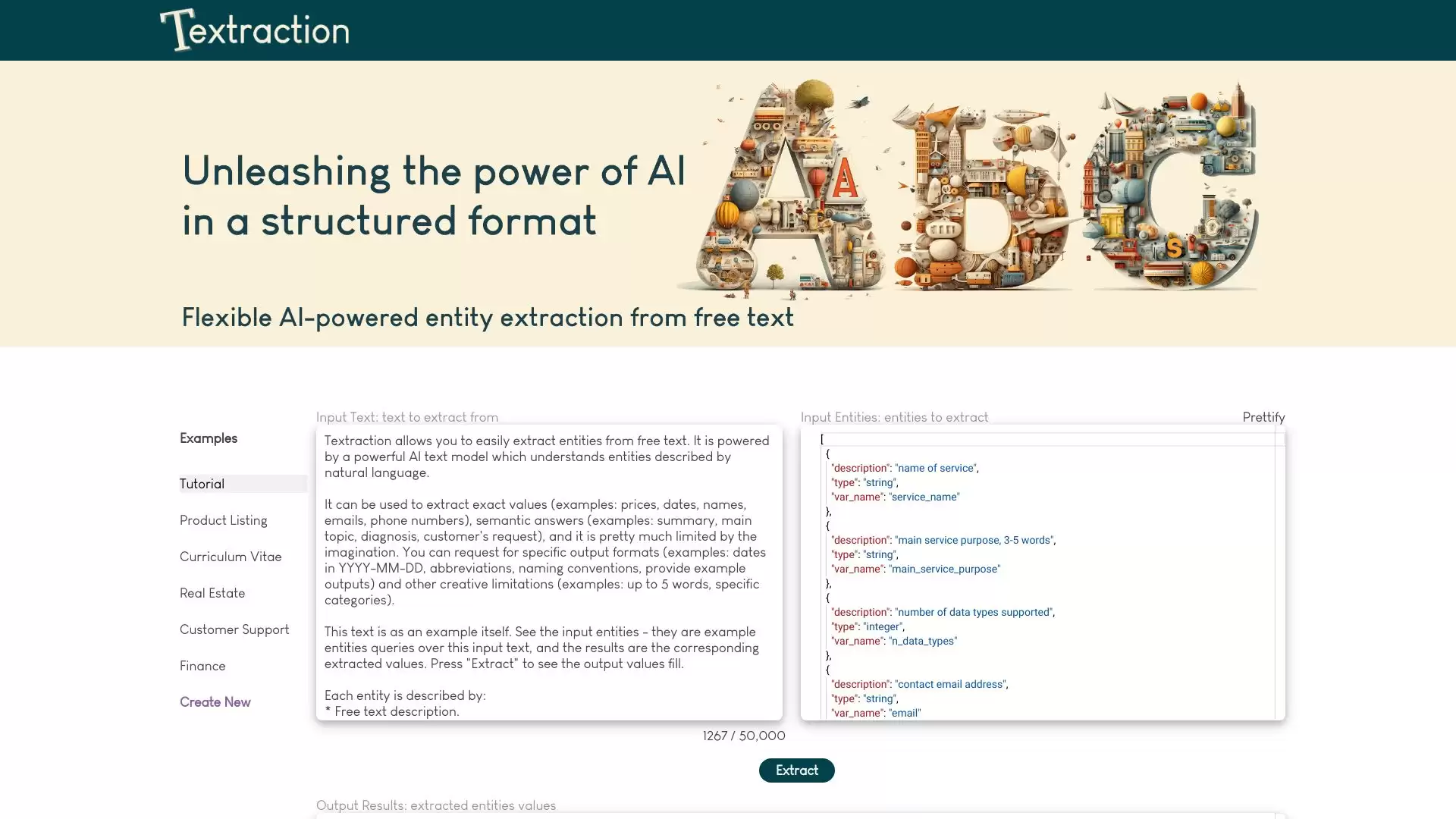
如何使用 AI Textraction?
使用流程非常直观:你只需要把原始文本“喂”给它,然后清晰地告诉它你想要提取什么。怎么告诉它呢?就是定义好你要找的实体的描述、类型以及一个变量名。接下来,AI就会像一位训练有素的助手,在文本中扫描并抓取出这些值,最后整整齐齐地以JSON格式返还给你,直接就能用。
AI Textraction 的核心功能
自定义实体提取
这才是它的看家本领。不同于固定的模板,你可以根据具体需求灵活定义要抽取的实体,这赋予了它极强的适应性和扩展性。
多语言支持
面对全球化的文本数据也不必担心,它对多种语言都有着良好的支持能力。
支持长文本(最多 50,000 个字符)
处理篇幅较长的文档或报告也不在话下,高达5万个字符的容量足以应对大多数复杂的业务场景。
Textraction.ai官网入口:https://www.textraction.ai
热门专题







热门推荐

要提升HDFS集群的稳定性,这些配置与优化思路值得关注 想让你的Hadoop分布式文件系统(HDFS)集群运行得更稳定、更可靠吗?这既是一项系统工程,也有一套清晰的优化路径——关键在于,你是否在硬件选型、参数配置、运维管理等核心层面都进行了系统性的规划与调优。下面这张图,可以帮助你快速建立起一个关于

HDFS副本策略调整指南 一 核心概念与层级 要玩转HDFS的副本策略,得先理清几个核心概念。它们像齿轮一样层层咬合,共同决定了数据最终落在哪里。 副本因子:这个最好理解,就是一个数据块要存几份。它直接决定了数据的可靠性和存储开销,默认值是3,算是可靠性与成本之间的经典平衡点。 副本放置策略:这是N

HDFS:一个为容错而生的分布式文件系统 在分布式存储领域,数据的安全性与可靠性是系统设计的核心。HDFS(Hadoop分布式文件系统)之所以能成为大数据生态的基石,关键在于其设计了一套多层次、自动化的容错机制。这套机制确保了在硬件故障、网络异常等常见问题发生时,数据依然保持完整且服务持续可用。本文

在HDFS中设置合理权限:一份实战指南 在Hadoop分布式文件系统(HDFS)中,权限管理绝非小事。它直接关系到数据的安全底线和系统的稳定运行。那么,如何为HDFS中的文件和目录设置一套既安全又实用的权限规则呢?下面这份指南,或许能给你带来清晰的思路。 1 基本概念 在动手之前,先得理清几个核心

在Hadoop分布式文件系统(HDFS)中实现数据压缩 处理海量数据时,存储成本与传输效率是两大核心挑战。HDFS提供了多种数据压缩方案,能够有效降低存储空间占用并提升数据处理性能。本文将详细介绍在HDFS中启用和配置数据压缩的几种实用方法。 1 配置文件设置 最直接且全局生效的方式是通过修改Ha