研究公司公布 SwiftKV 技术:优化大模型提示词处理过程、降低 50% AI 推论时间
研究公司公布 SwiftKV 技术:优化大模型提示词处理过程、降低 50% AI 推论时间
这事儿有点意思。就在1月17日,研究公司 Snowflake 放了个大招,公布了一项名为“SwiftKV”的AI模型调校技术。不仅公布了技术,人家还直接在 Hugging Face 上开源了三款运用该技术调校好的 Llama 3.1 模型(点此访问),诚意很足。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
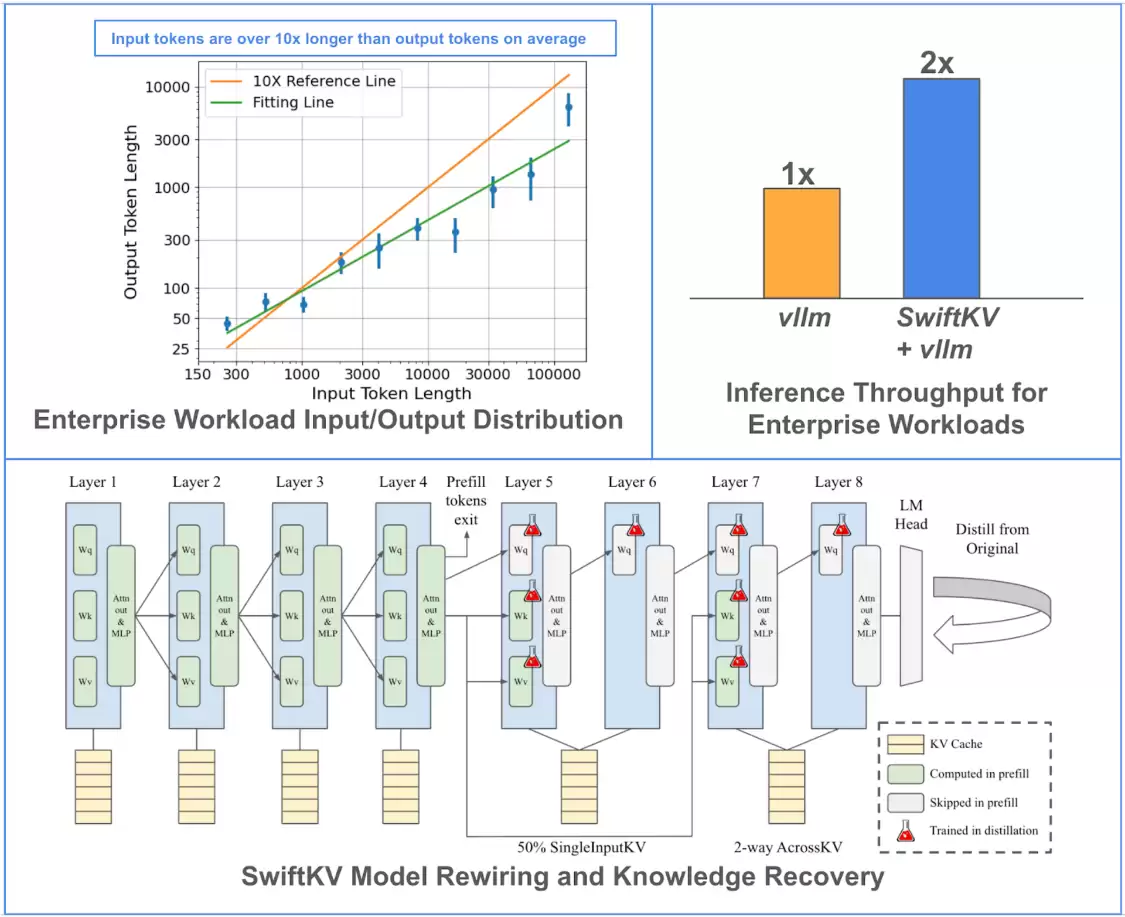
那么,这项“SwiftKV”技术到底解决了什么痛点?核心就一句话:专攻大模型推理中最“烧钱”的那个环节——提示词处理。
了解大模型工作原理的朋友都知道,模型生成回答(推理)的过程,其实包含了两个主要阶段:首先是理解你输入的长篇大论(提示词),然后才是根据理解来“创作”输出。问题恰恰出在第一阶段。Snowflake 的研究人员指出,现在很多企业级应用里,为了给模型足够的背景信息和指令,自定义的提示词长得离谱,平均长度“大约是输出生成内容的 10 倍”。处理这些超长提示词,就成了吞噬算力、拖慢速度的头号“元凶”。
而 SwiftKV 技术的突破性就在于此。它并非泛泛而谈的优化,而是专门针对这类预制的、冗长的提示词处理流程做了深度调校。根据 Snowflake 的介绍,这项技术不仅突破了传统的键值缓存压缩技术的瓶颈,还在模型推理过程中巧妙地引入了模型重组与知识保存自我蒸馏方法。听着很技术化,对吧?简单说,就是它用一套更聪明的方法,让模型在处理已知的、重复的提示词部分时,不再傻乎乎地每次都从头算一遍,从而极大地提升了模型吞吐量。
带来的好处是实实在在的:延迟和运算成本显著下降。最吸引眼球的莫过于那个数据——据称能降低模型高达50%的推论时间。这在追求效率和成本的商业应用场景里,无疑是个重磅消息。
光说不练假把式。实验数据最有说服力:在使用 SwiftKV 对 Llama 3.1 的 80 亿和 700 亿参数两个版本的模型进行优化后,结果相当亮眼。优化后模型的整体吞吐量足足提升了两倍。更重要的是,这种效率提升并没有以牺牲能力为代价,相关模型在代码自动补全、文本摘要等具体任务上,依然保持着出色的表现。
这意味着什么?意味着企业未来在部署同样性能的大模型时,可能只需要一半的算力资源,或者用同样的资源获得双倍的响应速度。技术演进的价值,往往就体现在这些能直接转化为效率和成本的数字里。SwiftKV 的这次开源,或许正是大规模AI应用降低成本、走向更普及化的又一个关键技术脚注。
热门专题







热门推荐

一、财务系统更换:一场不容有失的“心脏手术” 如果把企业比作一个生命体,那么财务系统就是它的“心脏”。这颗“心脏”一旦老化,更换就成了必须面对的课题。但这绝非一次简单的软件升级,而是一场精密、复杂、牵一发而动全身的“外科手术”。数据显示,超过70%的ERP(企业资源计划)项目实施未能完全达到预期,问

在企业数字化转型的浪潮中,模拟人工点击软件:从效率工具到智能伙伴 企业数字化转型的路上,绕不开一个话题:如何把那些重复、枯燥的电脑操作交给机器?模拟人工点击软件,正是因此而成为了提升效率、降低成本的得力助手。那么,市面上的这类软件到底有哪些?答案其实很清晰。它们大致可以归为三类:基础按键脚本、传统R

一、核心结论:AI智能体是通往AGI的必经之路 时间来到2026年,AI智能体这个词儿,早就跳出了PPT和实验室的范畴。它不再是飘在天上的技术概念,而是实实在在地成了驱动全球数字化转型的引擎。和那些只能一问一答的传统对话式AI不同,如今的AI智能体(Agent)本事可大多了:它们能自己规划任务步骤、

一、核心结论:AI智能体交互的“桥梁”是行动层 在AI智能体的标准架构里,它与外部系统打交道,关键靠的是“行动层”。可以这么理解:感知层是Agent的五官,决策层是它的大脑,而行动层,就是那双真正去执行和操作的手。这一层专门负责把大脑产出的抽象指令,“翻译”成外部系统能懂的语言,无论是调用一个API

一、核心结论:AI人设是智能体的“灵魂” 在构建AI应用时,一个核心问题摆在我们面前:如何写好AI智能体的人设描述?这个问题的答案,直接决定了智能体输出的专业度与用户端的信任感。业界实践表明,一个优秀的人设描述,离不开一个叫做RBGT的模型框架,它涵盖了角色、背景、目标和语气四个黄金维度。有研究数据