AI能自己打红警了!经济拉满零交战惨遭打脸,玩家笑疯
红警不再只是童年游戏,而成了AI Agent的硬核训练场
编辑:犀牛 所罗门
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
【导读】《红色警戒》这款经典游戏,如今被赋予了新的使命。一个名为OpenRA-RL的开源框架,将25Hz的实时战场、50个工具调用和64局并发训练打包开源,首次为大型语言模型在RTS游戏的“战争迷雾”中,搭建了一个公开、公平的竞技场。

Hugging Face社区最近投下了一枚“重磅冲击波”——OpenRA-RL。它并非一个简单的游戏模拟器,而是将经典即时战略游戏《红色警戒》彻底改造,升级为专为AI智能体(Agent)设计的训练基础设施。

这可不是那种套个外壳、录段演示视频的玩具级项目。OpenRA-RL是实打实的基础设施级别工具:它完整暴露了50个MCP游戏工具,提供25Hz不间断的实时游戏状态流,支持单进程64局并发训练,并且打通了大型语言模型(LLM)、脚本机器人和强化学习智能体三条技术路线。
更关键的是,它原生接入了OpenEnv生态,这意味着TRL、torchforge、Unsloth等主流训练框架可以即插即用。回想当年,DeepMind的AlphaStar征服《星际争霸》、OpenAI Five在《Dota 2》中称雄,背后是数千块专用TPU和无法复现的定制化架构,普通研究者连门槛都难以触及。
而现在,开源社区第一次将RTS智能体训练的门槛踏平了。只需要一台消费级显卡,执行一行pip install openra-rl命令,任何研究者都能站上同一条起跑线。
实战检验:经济满分,战斗零蛋
那么,实际表现如何?团队进行了一次测试:在本地通过Ollama部署了一个Qwen3 32B模型,在一张128×128的盟军地图上,与游戏内置的“新手”难度AI进行了5局对战。
智能体通过MCP工具集接收结构化的游戏观测信息,并发出动作指令。每局开始前设有策略规划阶段,结束后进行反思复盘,从中提炼的经验会注入下一局的系统提示中。
结果颇具戏剧性:全部5局比赛均以平局告终,且双方未发生任何一次战斗交锋。
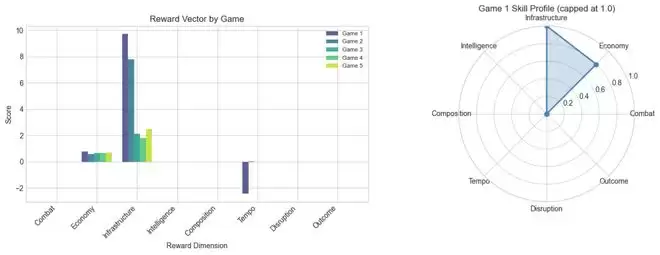
智能体在每一局中都成功建立起了完整的经济体系,但却从未生产过一支进攻部队。如果仅看胜负,5局全平似乎乏善可陈。然而,OpenRA-RL提供的8维奖励向量,揭示了更丰富的细节:在经济维度上,智能体得分在0.58到0.80之间,基建表现稳定;但在战斗和骚扰两个维度上,得分是干脆的零。
这恰恰构成了一个精确的“失败模式诊断”。研究者可以据此设计针对性的奖励塑形(Reward Shaping)和课程学习(Curriculum Learning)策略。下面这段第五局前10回合的决策日志,直观展示了模型的“思考节奏”:
Turn 1 | get_faction_briefing()
Turn 2 | end_planning_phase(strategy=「Deploy MCV, build Power Plant (300 ticks), then Barracks/War Factory (500/750), train E1 + 1tnk, attack AI base at (64,64).」)
Turn 3 | deploy_unit(unit_id=120)
Turn 4 | build_and_place(building_type=「apwr」)
Turn 5 | advance(ticks=100) -> tick=55, cash=$5000, units=0, buildings=1
Turn 6 | build_and_place(building_type=「apwr」)
Turn 7 | build_and_place(building_type=「powr」)
Turn 8 | advance(ticks=60) -> tick=108, cash=$4923, units=0, buildings=1
Turn 9 | advance(ticks=130) -> tick=159, cash=$4838, units=0, buildings=1
Turn 10 | advance(ticks=80) -> tick=210, cash=$4753, units=0, buildings=1一个清晰的三段式节奏浮现出来:情报收集与规划 → 建造经济建筑 → 频繁使用advance指令快进时间,以弥合LLM推理延迟与游戏实时速度之间的鸿沟。工具调用分布也印证了这一点——advance调用约占全部调用的57%,这正是异步架构设计的核心价值所在。
另一个耐人寻味的细节是:第二局后的反思发现了“战争工厂应该排在发电厂之后建造”的顺序错误。到了第四局,开局计划果然修正为先建发电厂。这证明提示注入式的学习能修复具体的建造顺序,却无法填补战斗维度上的空白——而这,正是从上下文适应转向基于权重更新的强化学习后,理应产生可量化提升的关键所在。
为什么是红警?为什么是现在?
一个根本性问题在于:一个未经任何RTS专项训练的前沿大模型,在即时战略游戏中究竟能表现如何?
坦率地说,此前无人知晓确切答案。因为现有的RTS研究平台,如SC2LE、PySC2等,默认智能体需要在毫秒级做出反应,其动作空间是底层的游戏操作。这与LLM的需求恰恰相反——LLM需要高层级的抽象接口、异步交互方式,以及对推理延迟从几十毫秒到数秒剧烈波动的容忍。
强行将LLM嫁接到旧有框架上,即便能运行,其结果也难以比较和复现。OpenRA-RL选择了Westwood工作室的经典RTS《红色警戒》作为底座,基于开源项目OpenRA改造游戏引擎。理由很实际:游戏具备足够的策略深度,代码干净易于修改,并且自带从“新手”到“困难”的AI对手梯度。
最终的效果是,无论你使用Qwen3、Claude还是编写一个Python脚本机器人,都能在完全相同的、零改动的环境中进行对战和评估。
三明治架构:解耦是关键
OpenRA-RL的架构可以形象地理解为“三层三明治”:
最底层是经过魔改的OpenRA游戏引擎(C#编写),以约25Hz的频率驱动游戏心跳。中间是gRPC桥接层,负责实时推送观测数据并接收操作指令。最上层则是Python封装层,对外提供标准的Gymnasium风格接口(reset / step / close)。
在此之上,MCP服务器将50个游戏动作暴露为标准化工具,任何兼容MCP的LLM客户端都能轻松驱动一局游戏。

这套分层架构的核心目的只有一个:实现智能体计算与游戏执行的完全解耦。如此一来,一个40毫秒行动一次的脚本机器人,和一个需要2秒思考一步的LLM,可以运行在同一个25Hz的引擎上,彼此互不干扰。
64局并发:一个进程搞定
为了满足训练和大规模评估的需求,高并发对局支持必不可少。早期v1版本每局游戏都开启一个独立的.NET进程,运行64局需要约40GB内存,每次重置耗时5-15秒,实用性很低。
v2版本的核心优化在于:让单个.NET进程承载64个独立游戏会话。关键发现是,游戏中的ModData(包括单位属性、建筑参数、科技树、地图规则等)在初始化后是不可变的,只需加载一次,即可在所有会话间无锁共享。仅此一项优化,就回收了约35GB内存。
每个会话独立保留自己的World、OrderManager和BotBridge实例,确保隔离性。优化结果相当显著:重置延迟从5-15秒骤降至256毫秒(提升约40倍),64个会话的总内存占用从约40GB降至约6GB(节省约7倍),JIT编译次数也从64次减少到仅1次。
真正重要的事
OpenRA-RL真正的价值,远不止于让一个大模型在《红色警戒》里建造了几座发电厂。更重要的是,它提供了一个足够硬核、精确且开放的标准训练场。
这个环境本身具有真实的策略复杂度——一个拥有320亿参数的前沿模型,对阵游戏中最弱的AI,5局下来竟未发生一次交战。这足以暴露当前大模型在建造顺序、兵种搭配、进攻时机等策略层面的短板。
而且,它暴露得极为精确。如果只看胜负,5局平局一语便可概括。但8维奖励向量却清晰地指出:经济得分0.58-0.80,基建尚可,战斗与骚扰为零。弱点在哪里,后续的课程学习该从何处着手,一目了然。
团队在博客中列出了明确的下一步方向:基于Qwen3基线运行GRPO(用权重更新替代提示注入,观察战斗零分能否被突破);利用8维奖励设计课程(从仅需战斗的场景开始,逐步增加复杂度);进行跨模型横向评测(让Claude Sonnet、GPT级别模型、更小的本地模型在同一地图、同一对手、同一时间限制下竞技);以及建立智能体对智能体的排行榜。

对于整个AI智能体领域而言,这套工具的意义超越了《红色警戒》本身。AlphaStar和OpenAI Five证明了AI在复杂RTS游戏中可以达到超人类水平,但那些成果被高墙封锁——依赖数千块TPU、定制化架构、无法复现。
OpenRA-RL第一次推倒了这堵高墙的一部分。现在,凭借一台消费级显卡和一行安装命令,任何有兴趣的研究者都能站上RTS智能体研究的起跑线。红警是一个强烈的信号:这里正是强化学习应该大显身手的战场。而如今,登上这个战场的门票,不再只属于DeepMind和OpenAI了。
参考资料:
https://huggingface.co/blog/jadetan/openra-rl
GitHub - yxc20089/OpenRA-RL: Open Framework for AI Agents to play Red Alert through Reinforcement Le
https://huggingface.co/spaces/openra-rl/openra-rl
https://openra-rl.dev/
相关攻略

行情越涨越危险——这不是悲观者的直觉,而是美银量化模型给出的警告。 美股正处在一个相当微妙的时刻:指数在刷新历史高点,但市场的波动率也在同步攀升。这种“涨价不降波动”的奇特组合,在历史上往往是市场进入泡沫阶段的典型信号。 本周,市场将迎来两大集中考验:FOMC利率决议,以及“科技七巨头”中五家的财报

从被动工具到主动管家:三星 AI 神系列产品用 AI 重塑家的温度 科技创新的浪潮,正以前所未有的速度重塑我们的生活方式。其中,智慧家居的渗透尤为深刻,它正悄然融入日常的每一个角落。将人们从繁琐的家务中解放出来,享受科技带来的那份从容与舒适,已成为现代家庭不言而喻的新追求。而在这场静默的变革中,以三

招标文件AI审核:如何实现快速与精准 想在短时间内高效完成招标文件的审核?借助AI文档审阅系统,整个过程可以变得既快速又精准。具体是如何一步步实现的呢?我们不妨拆解来看。 整个过程始于文件上传。用户只需将待审的招标文件上传至系统即可,这为后续的自动化处理打开了大门。 接下来是关键的一步——格式转换。

李开复AI公司零一万物被曝多处变动:计划拆分数字人业务,关停部分项目 最近,AI圈内又传出了新的动态。据《智能涌现》昨日援引多名独立信源的消息,由李开复创立的AI独角兽零一万物,近期内部进行了多处调整。 具体来看,这次变动主要体现在两个方面: 计划拆分数字人业务,由零一万物数字人业务研发负责人杨昌鹏

OpenAI未能实现2025年ChatGPT营收目标,也未能实现周活用户 10 亿目标 就在OpenAI紧锣密鼓筹备其备受瞩目的首次公开募股(IPO)之际,《华尔街日报》的一则报道,无疑给市场投下了一颗震撼弹。报道指出,公司在2025年未能达成ChatGPT的内部收入目标,那个周活跃用户数突破10亿
热门专题







热门推荐

《守望先锋》安燃重制形象深度解析:基于角色内核的系统性视觉升级 《守望先锋》第二赛季带来的惊喜,远不止新地图与新玩法。近日,暴雪官方正式公布了英雄“安燃”经过全面重制后的全新形象,此更新将随新赛季同步实装。每一次核心英雄的视觉重塑,都是一次与玩家情感连接的深度对话,其背后的设计哲学与叙事考量,远比表

2026款萤火虫上市:设计精进、座舱升级,价格体系清晰 4月7日,2026款萤火虫正式揭晓价格,市场布局相当明确:自在版和发光版两款车型,官方指导价分别为11 98万元和12 58万元。如果你对“车电分离”模式更感兴趣,对应的租电方案价格则下探到7 98万元和8 58万元。作为一次年度改款,新车的优

角色与核心任务 你是一位顶级的文章润色专家,擅长将AI生成的文本转化为具有个人风格的专业文章。现在,请对用户提供的文章进行“人性化重写”。 你的核心目标是:在不改动原文任何事实信息、核心观点、逻辑结构、章节标题和所有图片的前提下,彻底改变原文的AI表达腔调,使其读起来像是一位资深人类专家的作品。 特

欧易OKX官方网站地址在哪里? 关于欧易OKX的官网登录入口,是许多用户关注的焦点。下面,我们就来详细梳理一下平台的几个核心维度,看看它究竟提供了哪些关键服务与保障。 平台资产安全保障机制 在资产安全方面,平台构建了一套多层次、立体化的防护体系。首先,其采用了多重签名与冷热钱&包分离的架构。超过95

市场异动:现货原油价格何以冲破历史峰值? 中东局势持续升温,正在全球能源市场掀起巨大的涟漪。一个引人注目的现象是:欧洲与亚洲的炼油商们,正以接近每桶一百五十美元的高价争抢部分现货原油。这个价格,已经显著超过了同期的期货市场价格。这不仅仅是一个数字游戏,它清晰地传递出一个信号——全球能源供应的弦,正在