通义千问 Qwen 2.5-Max 超大规模 MoE 模型号称优于 Deepseek V3 等竞品,暂未开源
通义千问 Qwen 2.5-Max:阿里云发布超大规模MoE模型,性能表现引关注
新年伊始,国内AI领域就迎来一则重磅消息。阿里云正式公布了其全新的通义千问 Qwen 2.5-Max 模型,定位为超大规模混合专家模型。目前,开发者已能通过API调用体验其能力,普通用户也可以直接登录Qwen Chat,与模型对话或试用其artifacts、联网搜索等高级功能。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

这款模型来势汹汹,底气何在?根据官方介绍,其训练数据规模堪称海量,预训练阶段使用了超过20万亿token。更关键的是,研发团队为其配备了精心设计的后训练方案,这通常是模型能力实现“质变”的关键一步。
性能表现:直接对话与原始基座双线对比
官方这次将性能展示分成了两条线:一条是我们日常接触的、可直接对话的“指令模型”;另一条则是更底层的“基座模型”。
在指令模型的比拼中,阿里云直接将Qwen2.5-Max放在了最具竞争力的赛场,对比对象包括DeepSeek V3、GPT-4o和Claude-3.5-Sonnet等顶尖选手。结果如下图所示:
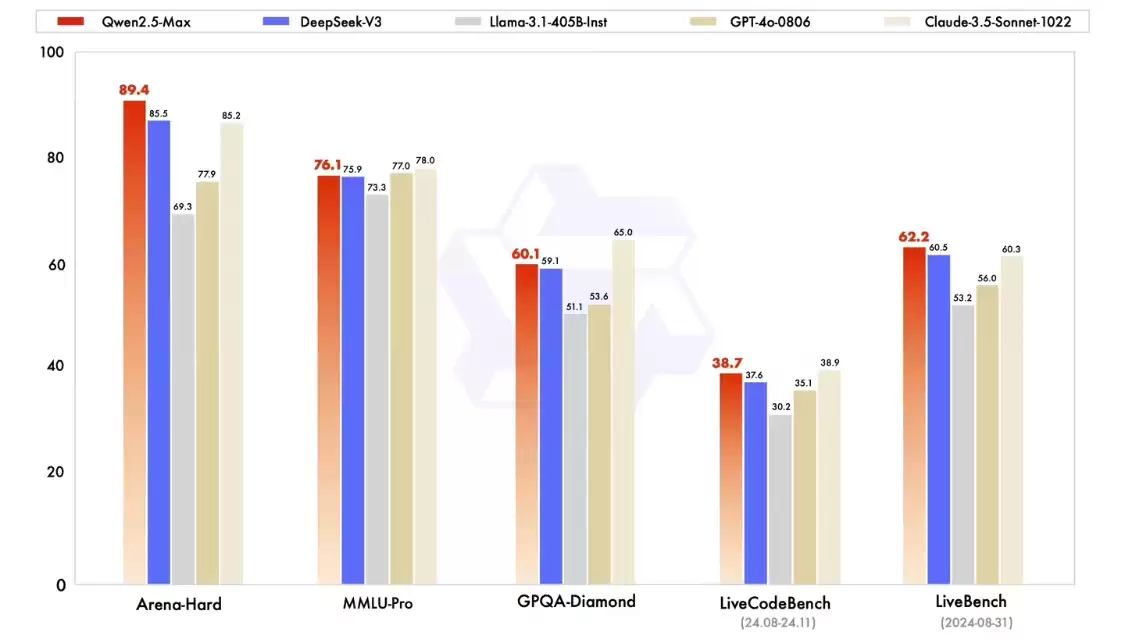
从数据来看,Qwen2.5-Max的表现颇具竞争力。在Arena-Hard、LiveBench、LiveCodeBench和GPQA-Diamond等一系列高难度基准测试中,其综合表现超越了同样备受瞩目的DeepSeek V3。同时,在MMLU-Pro等其他评估维度上,它也展现出了与顶级模型一较高下的实力。
当然,指令模型的优异表现离不开强大的基座能力。在基座模型的对比中,由于无法获取GPT-4o等闭源模型的基座版本,对比主要在当前主流的高性能开源模型间展开。其对手包括目前领先的开源MoE模型DeepSeek V3、参数规模最大的开源稠密模型Llama-3.1-405B,以及同属通义千问家族、在开源稠密模型中名列前茅的Qwen2.5-72B模型。具体对比如下:
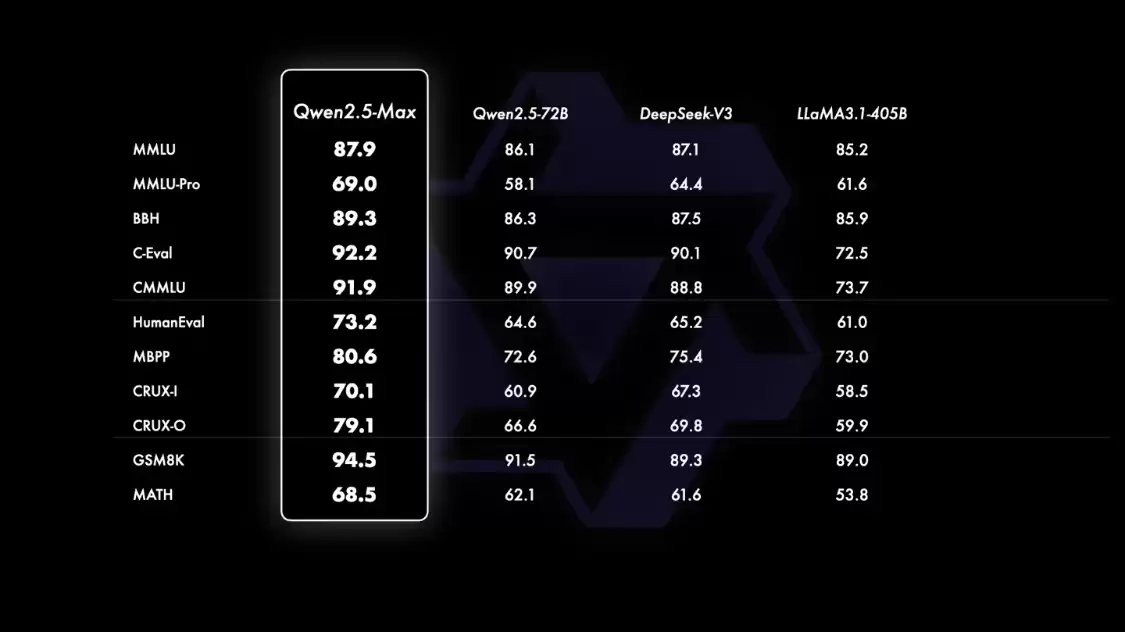
对比结果表明,Qwen2.5-Max的基座模型在大多数基准测试中都占据了优势。这意味着其强大的推理和知识能力拥有坚实的底层支撑。值得注意的是,官方在发布中透露了一个明确信号:随着后训练技术的持续迭代,下一个版本的Qwen2.5-Max有望达到更高的性能水准。这无疑为后续的AI竞赛添了一把火。
热门专题







热门推荐

一、财务系统更换:一场不容有失的“心脏手术” 如果把企业比作一个生命体,那么财务系统就是它的“心脏”。这颗“心脏”一旦老化,更换就成了必须面对的课题。但这绝非一次简单的软件升级,而是一场精密、复杂、牵一发而动全身的“外科手术”。数据显示,超过70%的ERP(企业资源计划)项目实施未能完全达到预期,问

在企业数字化转型的浪潮中,模拟人工点击软件:从效率工具到智能伙伴 企业数字化转型的路上,绕不开一个话题:如何把那些重复、枯燥的电脑操作交给机器?模拟人工点击软件,正是因此而成为了提升效率、降低成本的得力助手。那么,市面上的这类软件到底有哪些?答案其实很清晰。它们大致可以归为三类:基础按键脚本、传统R

一、核心结论:AI智能体是通往AGI的必经之路 时间来到2026年,AI智能体这个词儿,早就跳出了PPT和实验室的范畴。它不再是飘在天上的技术概念,而是实实在在地成了驱动全球数字化转型的引擎。和那些只能一问一答的传统对话式AI不同,如今的AI智能体(Agent)本事可大多了:它们能自己规划任务步骤、

一、核心结论:AI智能体交互的“桥梁”是行动层 在AI智能体的标准架构里,它与外部系统打交道,关键靠的是“行动层”。可以这么理解:感知层是Agent的五官,决策层是它的大脑,而行动层,就是那双真正去执行和操作的手。这一层专门负责把大脑产出的抽象指令,“翻译”成外部系统能懂的语言,无论是调用一个API

一、核心结论:AI人设是智能体的“灵魂” 在构建AI应用时,一个核心问题摆在我们面前:如何写好AI智能体的人设描述?这个问题的答案,直接决定了智能体输出的专业度与用户端的信任感。业界实践表明,一个优秀的人设描述,离不开一个叫做RBGT的模型框架,它涵盖了角色、背景、目标和语气四个黄金维度。有研究数据