1. 数据抓取:
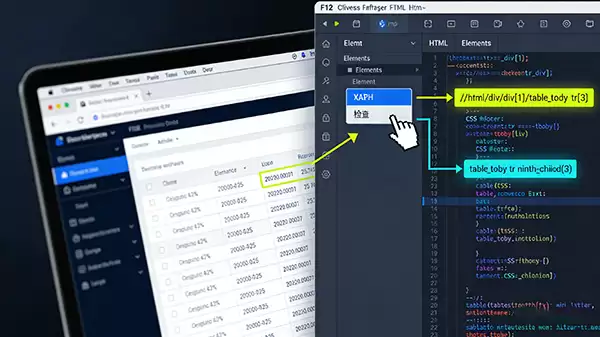
首先,我们得把数据从网页上“拿”下来。最直接的方法就是利用浏览器自带的开发者工具。(大部分浏览器按下F12键就能打开它)。
操作起来很简单:在网页上找到你想要的数据,右键点击它,选择“检查”。此时,开发者工具面板就会自动定位到这段数据对应的HTML代码。你的任务,就是像个侦探一样,仔细分析这段代码的结构,找到数据藏身的确切标签位置。之后,无论是使用XPath还是CSS选择器,都可以精准地定位并锁定这些数据。
2. 数据提取:
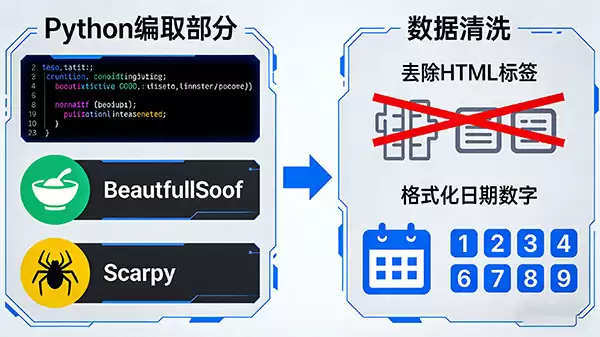
定位成功之后,就该动手提取了。如果你懂点编程,这事儿会变得非常高效。Python是这方面的利器,配合BeautifulSoup、lxml或者更专业的Scrapy框架,写几行代码就能自动完成抓取。
提取时,关键是把需要的字段清晰地剥离出来——比如产品价格、品牌、型号——并把它们规整地存放到列表或字典这类数据结构里,为下一步做好准备。
3. 数据整理:
刚从网页上抓下来的数据,往往带着不少“杂质”,比如冗长的HTML标签、多余的空格或者乱码。所以,整理和清洗这一步必不可少。
你需要仔细剔除这些无用信息,同时确保核心数据的格式是正确的。举个例子,日期要统一成标准格式,数字字符串要能转换为数值类型,这些细节决定了后续表格的可用性。
4. 数据导出为表格:
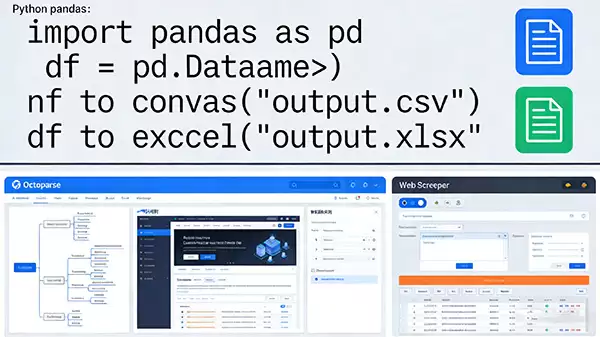
清洗干净的数据,终于可以“登堂入室”做成表格了。在Python生态里,pandas库是这个环节的“标配”。
你可以轻松地将整理好的数据转换为pandas的DataFrame对象——这本质上就是一个功能强大的表格数据结构。然后,只需一行代码:DataFrame.to_csv("文件名.csv") 或 DataFrame.to_excel("文件名.xlsx"),一份结构清晰的电子表格文件就生成完毕了。
5. 表格处理(可选):
导出并不等于结束。打开生成的CSV或Excel文件,从头到尾检查一遍数据的准确性和完整性,这是个好习惯。
接下来,你可以根据具体需求,在电子表格软件里进行最后的打磨:调整格式让阅读更舒适,按某一列排序以便分析,或者应用筛选功能快速聚焦关键信息。
6. 注意事项:
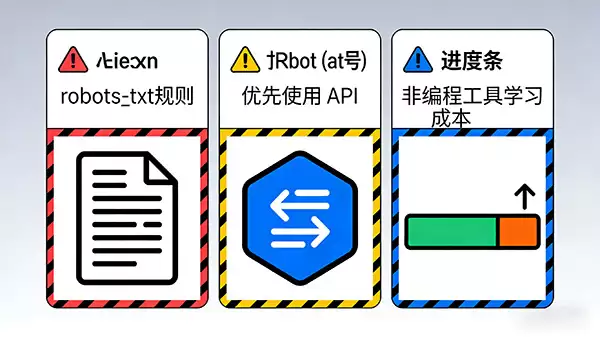
在整个数据抓取的过程中,有两条原则必须始终牢记。第一是合法合规:动手前,务必查看目标网站的robots.txt文件,尊重网站的抓取协议,并严格遵守相关法律法规,避免触及数据滥用的红线。如果网站提供官方的API接口,那么优先使用API永远是更推荐、更高效且更稳妥的方式。
当然了,并非所有人都熟悉编程。市面上也有不少用户友好的可视化工具或浏览器插件,比如Octoparse、Web Scraper等。它们通过模拟点击和配置规则来抓取数据,降低了技术门槛。不过需要注意,这类工具通常有一定的学习成本,且在应对复杂或动态加载的网页时,功能可能不如自己编写的程序灵活。
总之,将网页数据转化为规整的表格,是一项融合了技术判断与实践经验的技能。无论是选择编程深入定制,还是借助现成工具快速上手,核心目标都是高效、准确、合规地获取所需信息。只要把握住关键步骤和注意事项,你就能从容地驾驭网络上的海量数据。




