OpenAI 员工公开指责 xAI:Grok 3 基准测试结果具有误导性
OpenAI员工公开指责xAI:Grok 3基准测试结果具有误导性
这周AI圈里热闹了。一位OpenAI的员工公开站出来,炮轰埃隆·马斯克旗下的xAI公司。焦点在于,后者新发布的AI模型Grok 3的基准测试结果,被认为“具有误导性”。不过,xAI的联合创始人伊戈尔·巴布什金马上站出来灭火,坚称公司做法并无不妥。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

事情源于xAI在自家博客上发布的一张图表。图表展示了Grok 3在AIME 2025上的表现——这是一项邀请制数学考试中的高难度题集,虽然业内对其作为AI基准的有效性一直有讨论,但它和它的早期版本,依然是评估模型数学能力的常用标尺之一。
图表显示,Grok 3的两个版本——Grok 3 Reasoning Beta和Grok 3 mini Reasoning——在AIME 2025上的得分,超过了OpenAI当前最强的可用模型o3-mini-high。然而,OpenAI的员工很快在社交媒体上指出了关键问题:xAI的图表,巧妙地将对手的一个高分给“藏”了起来——它没有包含o3-mini-high在“cons@64”条件下的得分。
这里需要解释一下,“cons@64”也就是“consensus@64”,指的是允许模型在测试中对每个问题尝试回答64次,然后取出现频率最高的答案作为最终答案。你猜怎么着?这种“多数决”的方式,往往能显著拉升模型的测试分数。如果一张对比图刻意省略了某个模型在这个条件下的成绩,那产生的观感就可能天差地别。
事实上,如果只看首次尝试的得分(即“@1”条件),Grok 3的两个版本其实都没能超过o3-mini-high。而且,Grok 3 Reasoning Beta的得分,也略低于OpenAI的o1模型在“中等计算”设置下的表现。但即便如此,xAI依然在对外宣传中,将Grok 3称为“世界上最聪明的AI”。
面对指责,巴布什金的回应相当直接:他翻出旧账,指出OpenAI过去也发布过类似的、用于比较自家模型性能的图表,在他看来,那些图表同样存在误导性。公说公有理,婆说婆有理,这场口水战的核心,似乎从“谁对谁错”变成了“大家都这么干”。
有意思的是,有位中立的第三方看不下去了,他重新绘制了一张图表,试图呈现更完整、更“准确”的对比情况:
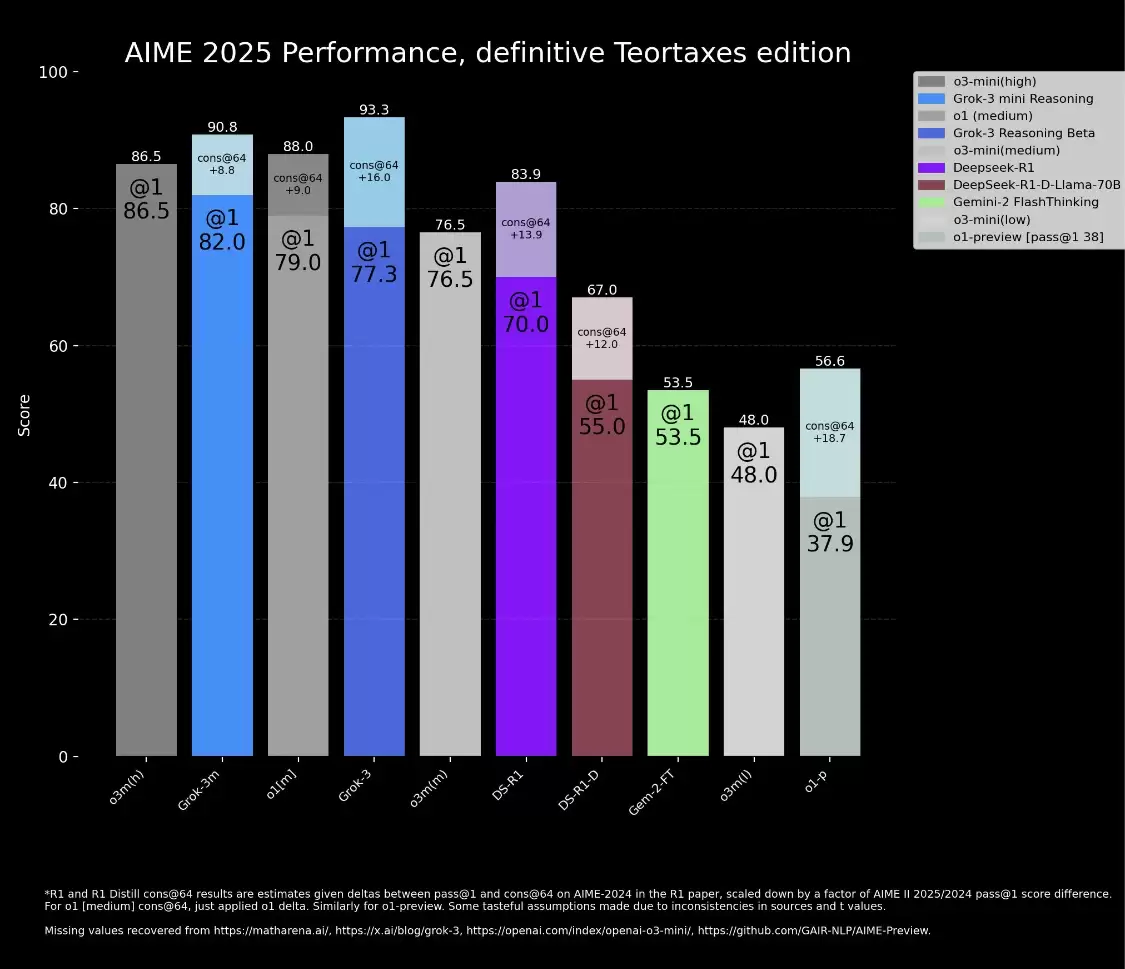
然而,正如AI研究员内森·兰伯特在一篇文章里点出的,或许最重要的指标至今仍是笔糊涂账:每个模型为了获得这个“最高分”,究竟耗费了多少计算资源(说白了,就是烧了多少钱)。这个问题恰恰暴露了目前大多数AI基准测试的通病——它们在清晰传达一个模型的真实能力边界和成本优势方面,做得还远远不够。说到底,光看分数排座次,可能意义有限。
热门专题







热门推荐

需求人群 如果你是一位产品经理或相关专业人士,正在为如何高效启动一个新项目、打磨一份专业的产品需求文档(PRD)而头疼,那么Signlz可能就是为你量身打造的工具。它核心解决的,就是帮助这个群体快速且高质量地迈出产品创新的第一步。 使用场景 那么,具体在哪些环节它能大显身手呢?最典型的,莫过于当你需

需求人群 如果你正在开发AI工具、机器人或者聊天助手,那么下面这个平台值得你特别关注。它瞄准的正是这个快速发展的开发者社区。 使用场景 具体能拿它来做什么呢?场景其实很丰富。比如,你可以用它快速搭建一个聊天机器人,来高效处理用户的那些常见问题,解放人力。艺术创作方面,它集成的图像生成模型能帮你产出风

2026 年 4 月,加密市场重新升温。BTC 一度触及 7 9 万美元,随后在 7 7 万美元附近震荡。随着资金回流、宏观预期变化和机构交易活跃,市场注意力再次回到 BTC 及其衍生品交易。 行情一旦回归,最先热闹起来的总是合约市场。更高的杠杆、更低的费用、更快的开仓速度,总能迅速把交易者拉回屏幕

想把你的视频内容传递给全世界的观众?语言障碍往往是最大的拦路虎。好在,现在有了专业的解决方案。Vidby,这款由瑞士Vidby AG公司打造的AI视频翻译与配音工具,正是为此而生。它能快速且精准地处理视频翻译、字幕生成和语音配音等一系列任务,帮你轻松跨越语言鸿沟。 那么,它是如何做到的呢?核心在于其

百度官宣文心大模型4 5系列将至,并定下开源时间表 情人节这天,国内AI领域迎来一则重磅消息。百度正式宣布,将在未来几个月内,逐步推出其文心大模型的下一代版本——4 5系列。而真正的重头戏在于,该系列模型将从今年6月30日起正式开源。这意味着,开发者与企业获得行业顶级大模型技术的门槛,将迎来一次显著