你是否曾好奇过,手机是如何将印刷文件拍成文字的?平板电脑又是如何读懂你潦草的笔记的?这背后是OCR和手写识别这两项技术在发挥着作用。虽然它们的目标都是“看图识字”,但面对的挑战和实现的技术路径,却有着云泥之别。
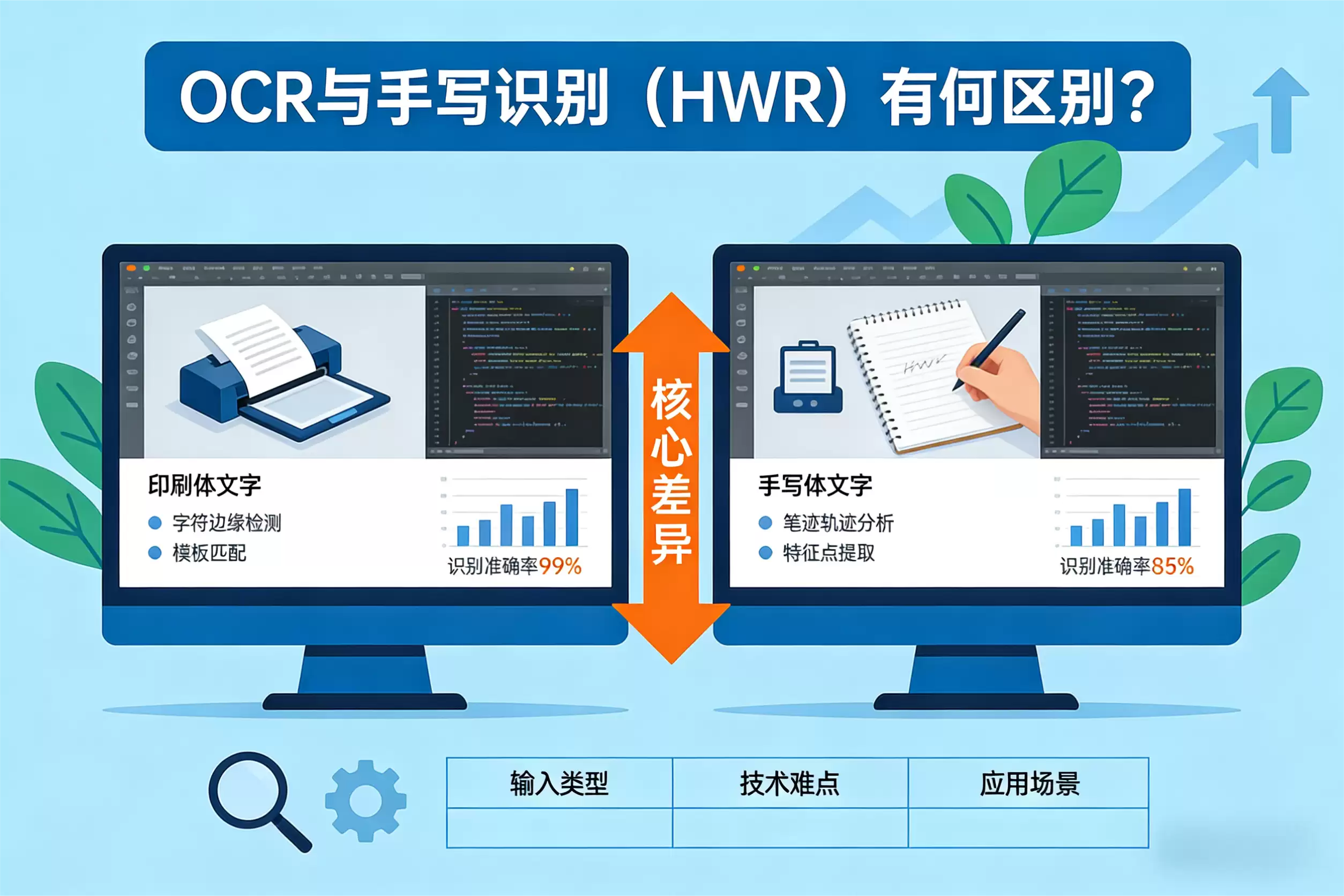
一、识别对象:
先来看看它们各自对付的对象。OCR,也就是光学字符识别,它的主战场是印刷或打印出来的文本。想想看,无论是书本、杂志还是文件扫描件,这些文本通常字体清晰、排版规范。这种一致性,使得OCR的识别任务相对直接,准确率也一直很高。因此,扫描文档数字化、车牌识别这类场景,几乎成了OCR的专属舞台。
而HWR,也就是手写识别,面对的可就是另一个世界了。它要读懂的是我们亲手写下的字迹。问题在于,一千个人可能有一千种书写风格:有人字迹工整如印刷体,有人则笔走龙蛇、难以辨认;笔画粗细、字体大小、连笔习惯更是千变万化。这种天生的多样性与随意性,注定了HWR的识别难度要高出不止一个数量级。所以,当你在平板上写笔记,或用电子笔签名时,背后默默工作的,就是更为复杂的HWR技术。
二、识别技术:
对象不同,技术自然也要跟着变。OCR技术,更像是一位严谨的“模板匹配师”。它的工作流程非常经典:首先,对图像进行预处理,比如去噪、二值化(把图像变成黑白),再把文本行和单个字符分割开来。接着,提取字符的轮廓、结构等稳定特征,最后拿去和内置的标准字符库进行比对,从而完成识别。为了提高效率,成熟的OCR系统还会结合上下文进行智能纠错,对付那些因打印污渍导致的识别错误。
反过来,面对毫无章法的手写体,HWR就不能再依靠固定的模板了。它更像是一位经验丰富的“笔迹分析师”,依赖的是强大的机器学习,尤其是深度学习算法。具体怎么做呢?核心是通过海量的手写样本去“训练”模型。让模型自己去学习,一个“张”字究竟有多少种写法,笔画的起承转合有什么规律。如今主流的深度学习模型,能够自动捕捉笔画顺序、空间结构和书写动态等深层特征,从而具备更强的泛化能力,能适应更多人的书写习惯。可以说,正是机器学习和海量数据,赋予了HWR与多样性抗衡的资本。
总而言之,OCR和HWR虽然同属将图像文字数字化的技术范畴,但从“标准化印刷体”到“个性化手写体”的跨越,意味着它们在技术实现上必须走上截然不同的道路。一个侧重于规则匹配与图像处理,另一个则依赖于数据驱动与模式学习。理解这份差异,或许下次当你的设备准确读出你随手写下的便条时,你会对其中蕴藏的科技匠心,多一份会心一笑。




