智东西4月24日消息
过去这一个多月,不少Claude Code用户心里直犯嘀咕:怎么感觉这工具“变笨了”?回复变短、记性变差、生成的代码质量也打了折扣,甚至有人直接调侃它“降智了”。
有意思的是,就在今天凌晨GPT-5.5正式亮相后,Anthropic立刻发布了一份技术报告,正面回应了近期关于Claude Code的种种质疑。报告的核心结论很明确:问题并非模型本身能力退化,而是过去一个多月里,三项独立的产品调整意外叠加、共同失效导致的。Anthropic特别强调,公司绝无可能蓄意降低模型性能,并宣布从今天起,重置所有订阅用户的使用额度,算是对用户体验损失的一种补偿。
经过全面排查,团队最终锁定了三个具体的技术“病灶”:
1、推理难度调整失当:3月4日,为了解决部分用户在“高”难度下遇到的界面卡顿问题,Anthropic将Claude Code的默认推理难度下调到了“中”。但用户反馈很快表明,大家其实更倾向于默认使用更高的智能级别,只在处理简单任务时才手动切换到低难度。于是,团队在4月7日撤销了这项更改,恢复了原有设置。这次调整主要影响了Sonnet 4.6与Opus 4.6版本。
2、缓存优化漏洞致模型“健忘”:3月26日上线的一个会话缓存优化功能,本意是好的——清除闲置超过一小时的会话历史思维记录,以降低延迟。但程序出了个漏洞,导致这个清除操作在会话的剩余时间里被反复触发。结果就是,模型开始出现回答重复、工具选择异常的情况。该漏洞在4月10日被修复,影响范围覆盖了Sonnet 4.6与Opus 4.6版本。
3、系统提示调整损害代码质量:4月16日,Anthropic新增了一条系统提示,目的是精简输出、减少冗余。没想到,这条新指令与其他现有规则叠加后,产生了意想不到的化学反应,反而导致了代码生成质量的下降。团队在4月20日迅速撤销了这条提示。这次变更影响了Sonnet 4.6、Opus 4.6及新发布的Opus 4.7版本。
01.默认推理强度调整引发连锁反应
在最新的排查公告里,Anthropic详细解释了这次性能波动的复杂性。它并非由单一问题引起,而是上述三项功能调整在时间和影响范围上相互叠加的结果。需要明确的是,问题仅限于Claude Code、Claude Agent SDK及Claude Cowork这三款产品,其核心的API服务并未受到影响。截至4月20日(版本号v2.1.116),所有相关问题都已修复完毕。
公告也坦言,由于三次变更各自的影响范围和持续时间不同,导致用户端的体验是“普遍感到性能下降,但问题表现并不稳定”。这种不稳定性,无疑给初期的问题排查增加了巨大难度。事实上,团队从3月初就启动了调查,但一开始很难区分这到底是正常的性能波动,还是确实出现了异常。内部的测试环境也没能第一时间复现故障。为了弥补用户,Anthropic才做出了重置所有用户使用额度的决定。
如果把时间线拉长,这场风波的伏笔早在今年2月就已埋下。当时,Anthropic在Claude Code中上线了Opus 4.6版本,并且将默认推理强度设置为“高”,旨在最大化模型的智能表现。然而,上线后不久,用户反馈就来了:高强度模式下,模型“思考”的时间太长,不仅带来了明显的响应延迟,Token消耗量也显著增加。
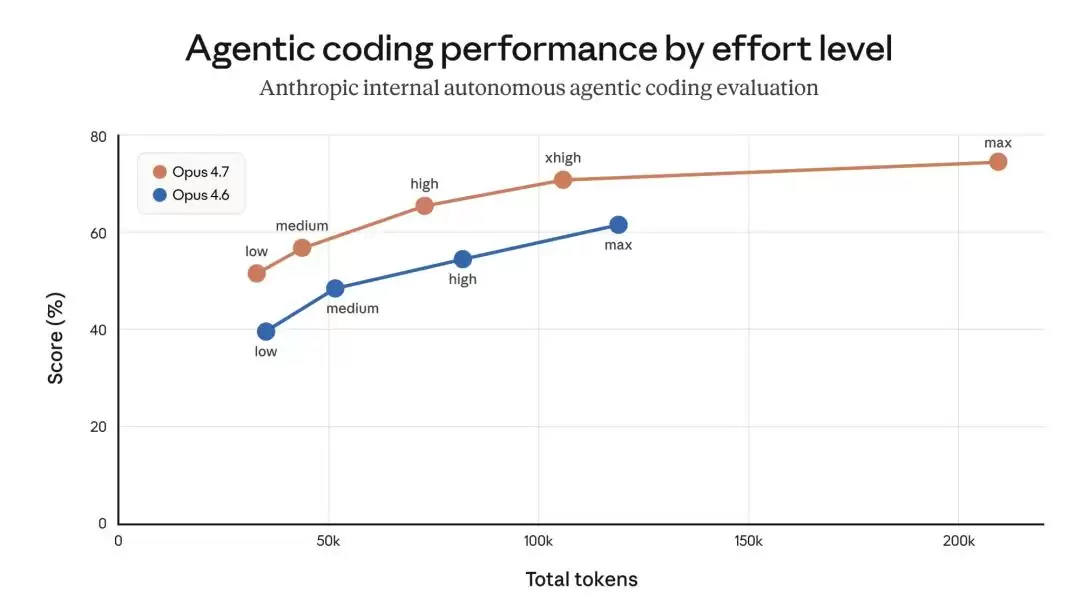
Opus 4.7与Opus 4.8不同模式下token消耗量
为此,Anthropic对默认设置动了一次手术。Claude Code里的“工作量级别”功能,其设计初衷是让用户在“思考时间、输出质量和成本”三者之间做出自己的权衡。内部测试显示,中等强度虽然在智能表现上略有妥协,但能显著降低延迟、避免极端的等待时间,同时提高使用效率。于是,团队一度将默认模式切换为“中”,并通过产品内的弹窗向用户说明了情况。
可是,这一调整很快引发了新的连锁反应,大量用户直观地感觉到模型“变弱了”。尽管团队随后尝试通过增加启动提示、内嵌难度选择器等方式引导用户自行调整,但大多数用户依然习惯沿用默认配置,导致负面反馈持续累积。
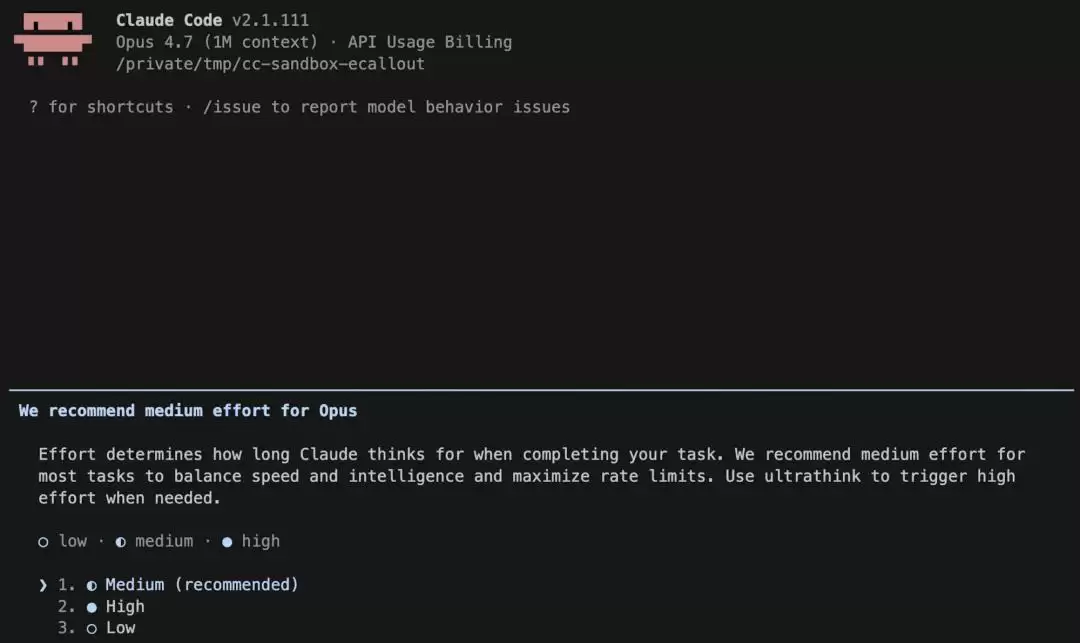
Claude通过产品内对话框解释了更改原因
在综合权衡了各方意见后,Anthropic最终在4月7日撤回了这项调整:将Opus 4.7的默认工作量设为1(对应xhigh级别),其余模型设为2(对应high级别),全面恢复了更高的默认推理强度。
02.让模型“健忘”的缓存漏洞
要理解这个漏洞,得先知道Claude的正常工作逻辑。在理想状态下,当Claude完成一轮推理后,它的整个思考过程会被完整地保存在对话历史中。这样,在接下来的每一次交互里,模型都能回溯自己之前为什么执行了某项编辑、调用了某个工具,从而保持决策的一致性和连贯性。
3月26日,Anthropic上线了一项旨在提升效率的性能优化,引入了“提示缓存”机制。简单说,就是为了降低连续API调用的成本并加快响应速度。具体做法是,Claude在发起请求时会把输入内容写入缓存;而当会话长时间不活跃后,这些缓存内容会被清理掉,以释放系统资源。
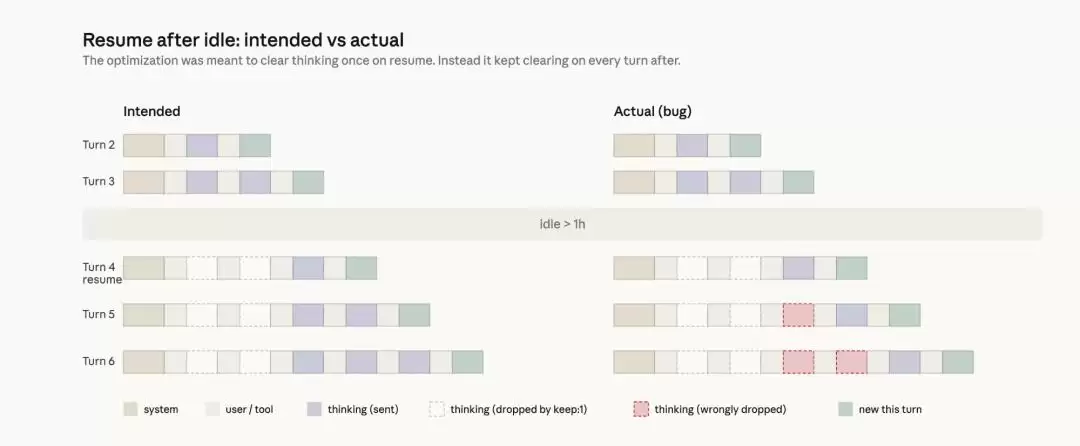
按照最初的设计,这个机制应该很简单:会话闲置超过一小时,系统就一次性清理掉旧的推理记录,以减少恢复会话时的资源开销。等用户再次回来交互时,再重新建立完整的推理历史。
但实际的代码实现出了个关键纰漏:推理历史并没有只被清理一次,而是在后续的每一轮对话中被持续、反复地清除。一旦会话触发了闲置阈值,之后的每个请求都会指示API只保留最新的一段推理数据,而丢弃之前所有的记录。
更麻烦的是,在工具调用过程中,如果用户插入了新消息,系统甚至可能在“上下文已经损坏”的状态下开启新一轮交互,连当前回合的推理信息都被一并清除。最终表现出来的症状就是,Claude虽然还能继续执行任务,但它越来越记不清自己之前为什么那么做,这正是用户反馈的“健忘”、回答重复、工具选择异常等问题的根源。
与此同时,由于这个漏洞持续地移除上下文信息,导致后续请求频繁出现缓存未命中的情况,Token消耗量不降反增。Anthropic认为,这也是部分用户反馈“使用额度消耗异常加快”的一个重要原因。
这个问题之所以难以被迅速发现,主要有两个原因:第一,它只在“长时间闲置会话”这类相对极端的条件下才会触发;第二,当时内部有两项并行的实验在一定程度上掩盖了问题的表现。其中一项是关于消息队列的服务器端实验,另一项则是对“思维过程展示”功能的调整,后者恰好在多数测试场景中抑制了异常现象,使得问题在测试阶段没有暴露出来。
从技术架构上看,这个漏洞位于Claude Code的上下文管理、Anthropic API与扩展推理机制三者的交汇处。相关的代码变更其实已经通过了多轮人工和自动化审查,也完成了单元测试、端到端测试和内部验证。但由于触发条件苛刻、复现难度极高,团队最终花费了超过一周时间才定位到根本原因,并在4月10日发布的v2.1.101版本中完成了修复。
在事后的复盘分析中,团队使用Opus 4.7对相关的代码提交进行了回溯。在提供了完整的代码仓库上下文后,Opus 4.7成功识别出了这个漏洞,而Opus 4.6则未能发现。Anthropic表示,未来将优化代码审查流程,考虑引入更大规模的上下文支持,以提升模型辅助开发工作的有效性。
03.系统提示优化的“副作用”
另一方面,随着Claude Opus 4.7的发布,模型在处理复杂任务时的能力确实显著增强了,但随之而来的一个“副作用”是输出内容更为详尽,这自然也带来了更高的Token消耗。
为此,Anthropic在Opus 4.7发布前的几周,就已经开始对Claude Code进行适配优化。由于不同模型在行为模式上存在差异,每次大版本更新前,团队都会对提示策略和产品体验进行系统性的调整。
在减少冗余输出方面,团队尝试了多种手段,包括模型训练优化、提示词设计以及交互体验改进。其中,一项关键调整是在系统提示中加入明确的长度限制指令:
工具调用之间的文本不超过25字;最终回复不超过100字(除非任务确有需要)。
这项改动在内部测试阶段没有暴露出明显问题,多组评估结果也没有显示性能下降,因此团队在4月16日随Opus 4.7版本一同上线了这项策略。
然而,在后续更大规模的评估中,通过消融实验(即逐条移除提示语以分析其具体影响)发现,这条长度限制对模型能力产生了负面影响,导致Opus 4.6与Opus 4.7的整体性能均下降了约3%。
基于这一确凿的评估结果,Anthropic在4月20日立即撤销了这条提示。
为了避免类似问题再次发生,Anthropic表示将从产品使用、研发流程与沟通机制等多个层面进行系统性改进。首先,团队将扩大内部真实使用场景,确保更多员工直接使用Claude Code的公开版本,而不是仅仅依赖测试环境中的预发布版本,以便更早地嗅探到潜在问题。同时,公司也将升级内部的代码审查工具,并计划将相关改进能力逐步开放给外部开发者使用。
在技术流程上,Anthropic将进一步收紧对系统提示变更的管理。未来,任何针对Claude Code的提示调整,都需要在不同模型版本上进行全面评估,并且要通过持续的消融测试来确保稳定性。团队还开发了新的审查与审计工具,以提升提示变更的可追溯性与可控性。此外,在内部的CLAUDE.md规范文件中,也已补充了相关条款,明确了不同模型的提示调整边界,防止出现跨模型干扰。
对于那些可能影响模型智能表现的改动,Anthropic表示将采取更谨慎的策略:延长测试周期、扩大评估数据集,并采用渐进式的发布方式,以便在影响范围较小时就能识别并修复问题。
在对外沟通方面,公司已经在X平台上线了@ClaudeDevs账号,用于更透明地解释产品决策背后的技术考量;同时,也会在GitHub的集中讨论帖中同步更新进展,增强与开发者社区的互动。
Anthropic在报告最后特别提到,此次问题的定位与修复,离不开用户社区的持续反馈。无论是通过官方反馈渠道提交的问题,还是用户在公开社区分享的可复现案例,都为排查工作提供了至关重要的线索。作为对这份支持的回应,公司于今日重置了所有订阅用户的使用额度。
04.结语:不只是更聪明,更要更可靠
回顾这场“降智”风波,其本质并非模型智力水平的退步,而更像是一个警示:在复杂的AI工程系统里,看似独立的产品决策与工程优化,可能会产生意想不到的叠加效应,最终引发连锁反应。
对Anthropic而言,这次公开、详细的技术复盘,既是一次对用户关切的危机应对,也是一次对外的清晰信号释放。在当下与OpenAI等竞争对手加速角逐的背景下,稳定、可靠的产品体验,或许正在成为与“追求更强模型”同等重要的竞争维度。毕竟,再聪明的模型,如果时不时“闹点小脾气”,用户体验也会大打折扣。




