高端单卡性能逆袭:RTX Pro 6000 Blackwell 单卡性能直逼四张RTX 5090
在AI大模型部署领域,一个常见的误区是认为显卡数量越多,性能必然越强。然而,近期一份来自外媒的深度评测报告,为我们揭示了截然不同的结论。测试聚焦于NVIDIA最新发布的专业计算卡RTX Pro 6000 Blackwell,结果显示:在处理超大规模AI模型时,一张顶级的专业单卡,其综合效率可能远超多张消费级旗舰显卡的并联方案,性能表现甚至接近四张RTX 5090。
评测选取了参数量高达2300亿的MiniMax M2.7大语言模型作为负载,在统一的IQ3_XXS量化精度、32K上下文长度以及4096最大生成token数的设定下进行。对比了以下四种硬件配置的性能数据:
4×NVIDIA GeForce RTX 4090(总显存96GB):生成速度71.52 tok/s,首token延迟(TTFT)1045ms
4×NVIDIA GeForce RTX 5090(总显存128GB):生成速度120.54 tok/s,TTFT 725ms
1×NVIDIA RTX Pro 6000 Blackwell(单卡显存96GB):生成速度118.74 tok/s,TTFT 765ms
NVIDIA DGX Spark 整机系统(显存128GB):生成速度24.41 tok/s,TTFT 741ms
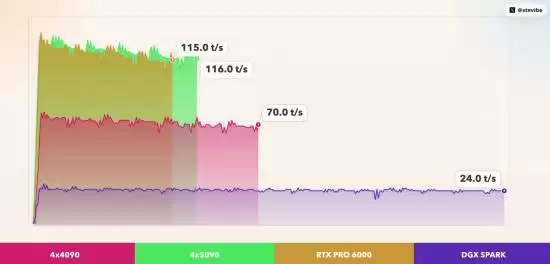
从核心的文本生成速度指标来看,结论非常清晰。单张RTX Pro 6000 Blackwell的性能几乎与四张RTX 5090组成的系统持平,同时显著领先于四张RTX 4090的方案。而DGX Spark作为面向特定能效场景的集成化解决方案,其性能表现属于另一条技术路线。
然而,性能对比只是故事的一部分。真正的决定性优势,往往体现在能效与功耗层面。我们来看一下各配置的典型功耗数据:
4×RTX 4090系统:整机功耗约1800W
4×RTX 5090系统:整机功耗约2300W
单张RTX Pro 6000 Blackwell系统:功耗约600W
DGX Spark 整机:功耗约240W
这组数据意味着什么?我们可以做一个直观的换算:RTX Pro 6000 Blackwell仅消耗了四卡RTX 5090系统约四分之一的电力,就实现了近乎同等的AI推理性能。对于需要7x24小时不间断运行大模型的数据中心、云服务商或AI研究实验室而言,由此带来的巨额电费节省与散热系统成本降低,具有巨大的商业价值。

当然,全面的评估必须纳入采购成本。以下是基于市场行情的粗略报价参考:
单张RTX 4090:约3000美元
单张RTX 5090:约3500美元(四张总计约14000美元)
单张RTX Pro 6000 Blackwell:约9500美元
DGX Spark 整机:约4699美元
综合性能、功耗与成本来看,这份测试清晰地指出了一个行业趋势:单纯依靠多卡并联来扩展显存,虽然看似直接,但会不可避免地引入PCIe通信瓶颈、更高的延迟以及并行效率损失。相比之下,搭载超大容量显存的顶级专业单卡,如RTX Pro 6000 Blackwell,在峰值性能、能源效率与总体拥有成本(TCO)之间取得了更优的平衡。特别是在运行参数规模巨大的前沿AI模型时,其“单卡一体化”架构带来的低内部延迟、高带宽优势以及卓越的能效比,表现得尤为突出。这为注重长期运营效率、系统稳定性与投资回报的专业级AI计算场景,提供了一个极具竞争力的高性能解决方案。




