一、什么是子查询?
说到SQL查询,大家肯定不陌生。但你是否遇到过这样的情况:一个查询条件,需要依赖另一个查询的结果才能确定?这时候,子查询就该登场了。
简单来说,子查询就是一条嵌套在另一条SQL语句内部的SELECT语句。它像一个“先遣部队”,先执行并得出结果,然后这个结果再被外层的“主力部队”——也就是主查询——所使用。
这里有几个关键点需要厘清:
- 外面的查询叫主查询或外层查询。
- 里面嵌套的查询叫子查询或内层查询。
它们的执行顺序非常明确:先执行子查询,得到结果,再把结果交给主查询使用。这个逻辑链条是理解子查询的基础。
来看一个基本的结构:
SELECT 字段列表
FROM 表名
WHERE 字段 运算符 (
SELECT 字段
FROM 表名
WHERE 条件
);
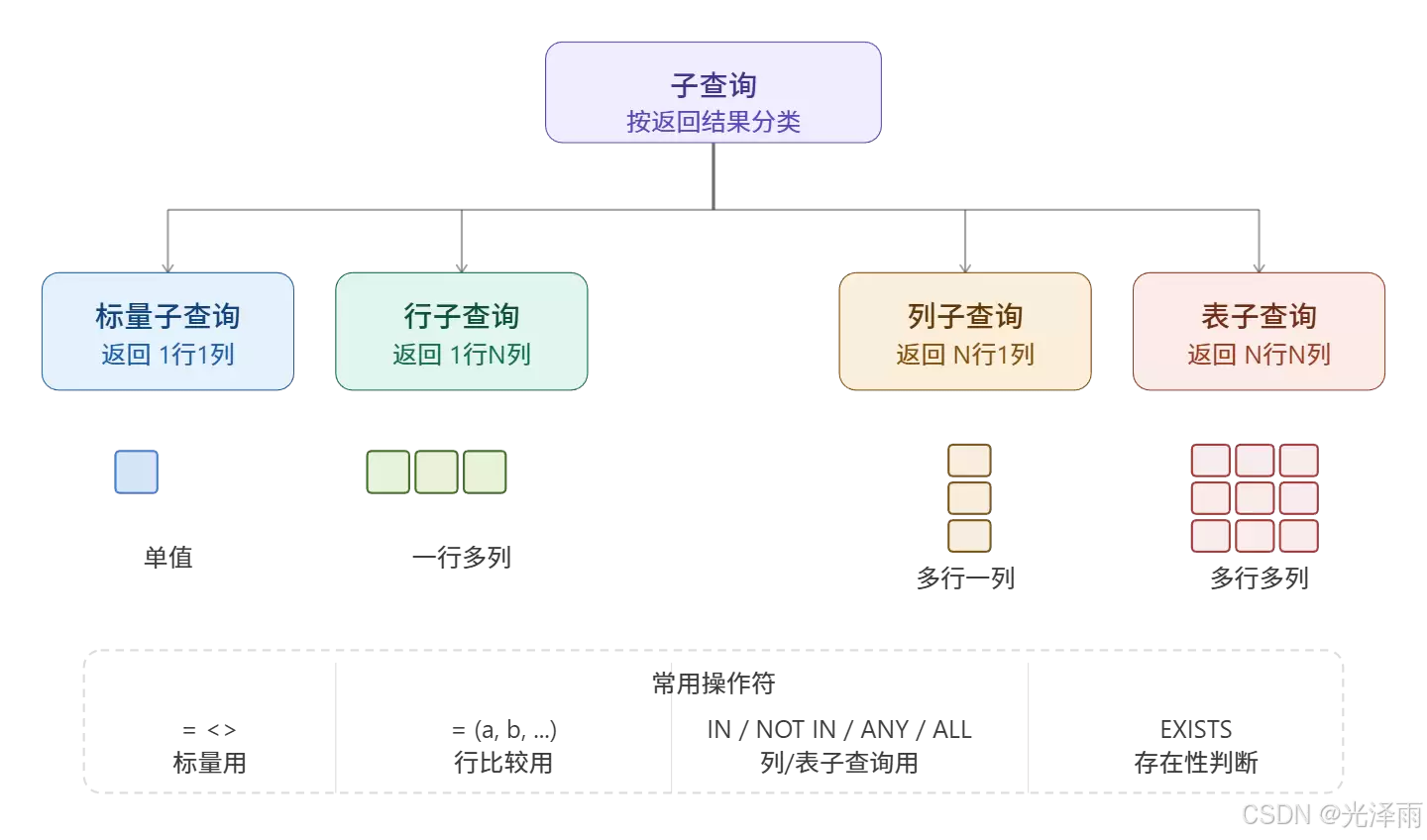
二、子查询按结果集分类(最重要)
子查询之所以有时让人困惑,很大程度上是因为它返回的结果“形状”不同,用法也随之变化。根据结果集,子查询可以清晰地分为4类,掌握这四类是精通子查询的关键。
1. 标量子查询(单行单列)
这是最直接、最简单的一种。所谓标量子查询,就是指子查询返回的结果是一个单一的值,比如一个数字、一个字符串或一个日期。
因为它只返回一个值,所以可以像使用普通常量一样,用在需要单值的地方,特别是=、>、<、>=、<=、!=这些比较运算符后面。
示例:查询“研发部”的所有员工
SELECT emp.*
FROM emp
WHERE emp.dept_id = (
SELECT dept.id
FROM dept
WHERE dept.name = '研发部'
);
这个例子中,内层查询先找出名为“研发部”的部门ID(假设是3),然后外层查询就变成了WHERE emp.dept_id = 3,逻辑非常清晰。
再来看一个经典场景:查询工资高于平均工资的员工。
SELECT name, salary
FROM employees
WHERE salary > (
SELECT A VG(salary)
FROM employees
);
这里,SELECT A VG(salary)只返回一个数字(全公司的平均工资),外层直接用>进行比较。需要注意的是,如果这个子查询不小心返回了多行数据,MySQL会直接报错,因为它期待的是一个标量值。
2. 列子查询(多行一列)
当子查询返回的结果是多行但只有一列时,它就升级成了列子查询。这时,就不能用简单的等号了,需要请出IN、NOT IN、ANY、ALL这些操作符来帮忙。
示例1:IN — 查询办公地点在上海的所有部门的员工
SELECT name
FROM employees
WHERE dept_id IN (
SELECT id
FROM departments
WHERE location = '上海'
);
IN是最常用的,表示“属于其中任意一个”。
示例2:ANY — 工资比研发部任意一位员工高就算
SELECT name
FROM employees
WHERE salary > ANY (
SELECT salary FROM employees WHERE dept_id = 3
);
示例3:ALL — 工资必须比研发部所有人都高
SELECT name
FROM employees
WHERE salary > ALL (
SELECT salary FROM employees WHERE dept_id = 3
);
简单记:ANY相当于“矮子里面拔将军”,满足一个就行;ALL则是“挑战最高标准”,必须全部满足。下面这个等价写法能帮你更好地理解列子查询:
-- 先查出销售部和市场部的ID(假设是2和4) select id from dept where name='销售部' or name='市场部'; -- 再用IN查询员工 select * from emp33 where id in(2,4) -- 等价于直接用列子查询一步完成 select* from emp33 where id in (select id from dept where name='销售部' or name='市场部');
3. 行子查询(单行多列)
这种查询相对少见但很实用。它返回一行数据,但包含多个字段。匹配时,需要用行构造器(col1, col2, ...)将多个字段打包成一个整体进行比较。
示例:查询和“张三”同部门、同职位的所有员工
SELECT emp.*
FROM emp
WHERE (emp.dept_id, emp.job) = (
SELECT emp.dept_id, emp.job
FROM emp
WHERE emp.name = '张三'
);
括号里的(dept_id, job)和子查询返回的(dept_id, job)必须一一对应。它支持=、<>等操作符。这种写法其实等价于用多个标量子查询进行AND连接,但更简洁:
select * from emp33 where (salary,managerid) =(select salary,managerid from emp33 where name='张无忌'); -- 等价于 select * from emp33 where managerid=(select managerid from emp33 where name='张无忌') and salary=(select salary from emp33 where name='张无忌');
4. 表子查询(多行多列)
当子查询返回一个完整的、多行多列的结果集时,它就可以被当作一张临时表来使用。这种子查询必须出现在FROM子句后面,并且必须给它起一个别名。
示例:将每个部门的平均薪资计算出来,作为一张临时表进行查询
SELECT temp.dept_id, temp.a vg_sal
FROM (
SELECT emp.dept_id, A VG(emp.salary) AS a vg_sal
FROM emp
GROUP BY emp.dept_id
) AS temp;
这里,内层的GROUP BY查询生成了一张包含部门ID和平均薪资的临时表,外层再从这个临时表中选取数据。这在处理复杂的分组统计时非常有用。
三、子查询出现的 3 个位置(高频考点)
别以为子查询只能老老实实待在WHERE后面。实际上,根据不同的需求,它可以出现在SQL语句的几个关键位置上,每种位置对应着不同的子查询类型。
| 位置 | 常见类型 | 说明 |
|---|---|---|
WHERE / HA VING后 |
标量、行、列 | 作为过滤条件的一部分 |
FROM后 |
表子查询 | 作为数据源(派生表),必须起别名 |
SELECT后 |
标量 | 作为查询出的一个字段值(通常是相关子查询) |
1. 放在 WHERE 后(最常用,标量、行、列)
这是子查询最常见的家,用于动态生成过滤条件。
SELECT emp.name
FROM emp
WHERE emp.dept_id = (
SELECT dept.id
FROM dept
WHERE dept.name = '财务部'
);
2. 放在 FROM 后(当作表,表子查询)
把子查询结果当作一张表来连接或查询。
SELECT temp.name
FROM (
SELECT emp.name
FROM emp
WHERE emp.salary > 10000
) AS temp;
3. 放在 SELECT 后(相关子查询,标量)
这对于为每一行主查询结果附加一个计算字段非常有用。注意,这通常是一个相关子查询,子查询的执行依赖于外层查询的当前行。
SELECT
emp.name,
(
SELECT dept.name
FROM dept
WHERE dept.id = emp.dept_id
) AS dept_name
FROM emp;
这个查询会为每一位员工,实时去部门表里查找对应的部门名称。逻辑清晰,但性能上需要留意。
四、子查询关键字详解(IN / ANY / ALL / EXISTS)
与列子查询和特定场景相伴的,是几个至关重要的关键字。
1. IN
当子查询返回一个值列表时,用IN来判断主查询的字段值是否在这个列表中。
SELECT emp.*
FROM emp
WHERE emp.dept_id IN (
SELECT dept.id
FROM dept
);
2. ANY
表示“任意一个”。只要满足子查询结果中的任意一个条件,主查询的行就会被选中。
SELECT emp.*
FROM emp
WHERE emp.salary > ANY (
SELECT emp.salary
FROM emp
WHERE emp.dept_id = 1
);
3. ALL
表示“所有”。必须满足子查询结果中的所有条件,要求更为严格。
SELECT emp.*
FROM emp
WHERE emp.salary > ALL (
SELECT emp.salary
FROM emp
WHERE emp.dept_id = 2
);
4. EXISTS
这是一个存在性测试。它不关心子查询返回什么具体数据,只关心子查询是否有结果返回。有结果,则返回真(True)。它常用于依赖关系的检查。
SELECT emp.*
FROM emp
WHERE EXISTS (
SELECT *
FROM dept
WHERE dept.id = emp.dept_id
);
这个查询会找出所有有所属部门的员工(即部门ID在部门表中存在的员工)。
五、子查询 VS 多表连接(对比)
很多时候,同一个查询需求既可以用子查询实现,也可以用多表连接(JOIN)实现。那么该如何选择?
- 子查询:优势在于逻辑清晰,符合“分步思考”的习惯,尤其适合作为过滤条件。但在处理大数据集时,性能可能不如连接。
- 多表连接:优势在于执行效率通常更高,数据库优化器能更好地处理连接操作。代码可能更简洁,但需要理解表之间的关系。
来看一个对比示例,两者效果完全相同:
-- 子查询写法:先找部门ID,再找员工
SELECT emp.name
FROM emp
WHERE emp.dept_id = (
SELECT dept.id
FROM dept
WHERE dept.name = '研发部'
);
-- 多表连接写法:直接关联两张表进行过滤
SELECT emp.name
FROM emp
INNER JOIN dept
ON emp.dept_id = dept.id
WHERE dept.name = '研发部';
选择哪种,往往取决于具体的数据量、索引情况以及个人的编码习惯。在大多数现代数据库优化器中,简单的子查询常常会被重写为连接操作。
六、子查询必须遵守的规则(考试必背)
要玩转子查询,下面这几条铁律必须牢记于心:
- 子查询必须放在括号内,这是它的“隔离罩”。
- 标量子查询只能返回一个值,否则会报错。
- 列子查询返回一列多行,需配合
IN、ANY等使用。 FROM后面的子查询必须起别名,否则数据库不知道如何引用这张临时表。- 执行顺序上,子查询先执行,主查询后执行(相关子查询除外)。
- 在子查询中,通常不能使用
ORDER BY子句,除非与LIMIT搭配使用(因为排序对子查询返回的结果集本身通常没有意义)。
七、综合实战案例(最经典)
理论说得再多,不如看几个实战案例来得实在。
案例 1:查询工资最高的员工
这是一个典型的标量子查询应用:先用子查询找到最高工资,再用这个值去匹配员工。
SELECT emp.*
FROM emp
WHERE emp.salary = (
SELECT MAX(emp.salary)
FROM emp
);
案例 2:查询每个部门工资最高的员工
这个需求稍微复杂,需要先按部门分组找出最高工资,再将结果与原表关联。这里巧妙使用了FROM后的表子查询。
SELECT emp.*
FROM emp
INNER JOIN (
SELECT emp.dept_id, MAX(emp.salary) AS max_sal
FROM emp
GROUP BY emp.dept_id
) AS temp
ON emp.dept_id = temp.dept_id
AND emp.salary = temp.max_sal;
案例 3:查询没有员工的部门
这是一个使用NOT IN的经典场景。先找出所有有员工的部门ID,然后查询不在这个列表中的部门。
SELECT dept.*
FROM dept
WHERE dept.id NOT IN (
SELECT DISTINCT emp.dept_id
FROM emp
WHERE emp.dept_id IS NOT NULL
);

说到底,理解子查询的诀窍就在于:先看清楚内层查询返回的是什么“形状”的数据(一个值、一列值、一行值还是一张表),然后根据这个形状,选择正确的操作符和放置位置。一旦掌握了这个分类思维,再复杂的嵌套查询也能迎刃而解。
总结
子查询是SQL中构建复杂查询逻辑的利器。从简单的标量比较到复杂的多级嵌套,它提供了极大的灵活性。核心在于区分四种结果类型,并熟悉它们在WHERE、FROM、SELECT不同位置上的用法。同时,了解它与JOIN的适用场景差异,并牢记那些必须遵守的语法规则,就能在实战中游刃有余地运用子查询来解决各类数据检索难题。




