OpenAI推出GPT-5.4 mini与nano:为高效AI工作流而生的“轻骑兵”
3月18日,AI领域传来新动态:OpenAI正式发布了GPT-5.4 mini和GPT-5.4 nano两款模型。这可不是简单的迭代,而是精准定位——它们专为那些需要快速、大规模处理AI任务的工作负载设计,目标直指低成本、高效率的应用场景。
适用于AI工作流的小型模型
在实际的AI工作流中,选模型往往是个平衡术。你既需要不错的性能,又得追求飞快的响应速度,同时工具调用还得稳定可靠。三者缺一不可。
OpenAI对此的阐述很直接:“这些模型就是为对延迟敏感的工作负载而生。在这些场景里,延迟哪怕慢一点,用户体验就会大打折扣。”想想看,那些需要即时反馈的编程助手、负责执行具体任务的子智能体、实时解读屏幕内容的操作系统,还有能对图像进行快速推理的多模态应用——它们的共同点是什么?就是“等不起”。
所以,OpenAI点出了关键:在这些场景下,最合适的模型往往不是参数最大的那个,而是那个反应快、工具调用稳、在专业任务上不掉链子的选手。
具体来看,相比前代的GPT-5 mini,这次的GPT-5.4 mini在编程、逻辑推理、多模态理解和工具使用上都有提升,而且运行速度直接翻了个倍。至于GPT-5.4 nano,则是更极致的选择:体积更小、速度更快,主打分类、数据提取、排序以及相对简单的编程辅助任务。
性能表现
说到小模型,大家最关心的无非两点:性能到底行不行?性价比高不高?OpenAI也拿出了对比数据,让事实说话:
• 在SWE-bench Pro基准测试中,GPT-5.4 mini拿到了53.40%的分数,而GPT-5 mini是45.69%。
• 在Terminal-Bench 2.0测试中,GPT-5.4 mini达到了59.30%,远超GPT-5 mini的38.20%。
• 在GPQA Diamond测试中,GPT-5.4 mini得分85.48%,已经非常接近全功能版GPT-5.4的93.00%。
• 在OSWorld-Verified测试中,GPT-5.4 mini以70.60%的通过率,显著高于GPT-5 mini的42%。
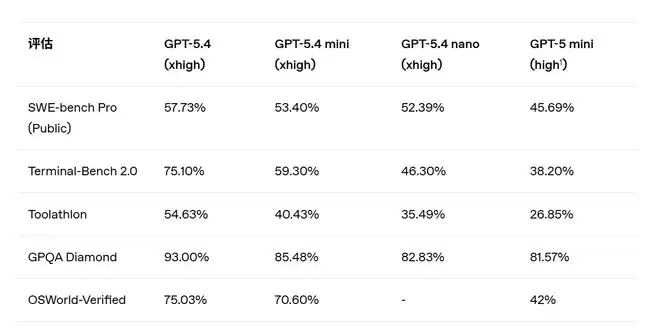
测试结果透露了一个明确信号:GPT-5.4 mini在多项关键测试中的通过率,已经逼近了它的“老大哥”GPT-5.4,而且执行速度还更快。这意味着,在衡量模型能否正确解决问题的基准上,这个轻量级选手的表现不容小觑。
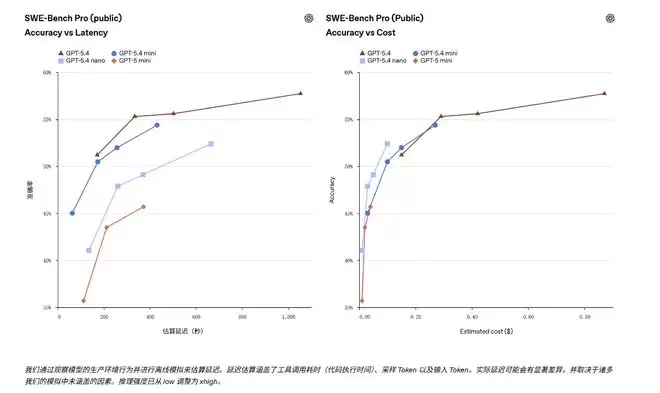
至于GPT-5.4 nano,其表现则介于两者之间,定位清晰。例如,它在SWE-bench Pro上得分52.39%,在Terminal Bench 2.0上为46.30%。数据虽略低于GPT-5.4 mini,但依然稳稳超过了GPT-5 mini。
子智能体与多模态任务
在智能体的生态系统里,架构设计越来越像现实中的团队协作。一个常见的思路是,让能力强大的AI模型(比如GPT-5.4 Thinking)与速度快、成本低的模型(比如GPT-5.4 mini)搭档工作。这好比一位资深工程师带着几位高效的初级工程师协同作战,既能把握方向,又能快速执行。
在这样的系统里,不同规模的模型可以各司其职:大模型负责顶层规划和复杂思考,小模型则专注执行具体的子任务。GPT-5.4 mini扮演的,正是“子智能体”的角色,比如搜索代码库、审查文件、处理文档这些需要快速响应的活儿。
OpenAI特别提到了它的多模态能力:“GPT-5.4 mini能够处理涉及计算机使用的多模态任务。简单说,它能看懂密集的用户界面截图,并据此辅助完成操作,这对于自动化办公流程来说潜力很大。”
可用性与定价
目前,GPT-5.4 mini已经通过API、Codex和多个版本的ChatGPT提供服务。对于免费版和Go级用户,可以通过附加菜单里的“Thinking”选项来调用它。OpenAI还给出了一个实用的降级策略:“对于其他所有用户,当GPT-5.4 Thinking触发速率限制后,系统会自动将请求切换到GPT-5.4 mini作为备选。”
对于开发者群体,GPT-5.4 mini已经覆盖了Codex应用、命令行界面、集成开发环境扩展以及网页端。这里有个成本亮点:这款mini模型“仅消耗GPT-5.4配额的30%,这意味着开发者能在Codex中以大约三分之一的成本来处理那些相对简单的编程任务。”此外,Codex还能智能地将任务“委托”给GPT-5.4 mini这样的子智能体,让推理强度要求不高的工作在低成本模型上运行,从而优化整体资源分配。
具体的成本对比数据如下:
• GPT-5.4 mini定价为每百万输入Token 0.75美元,每百万输出Token 4.50美元,拥有40万词的上下文窗口。
• GPT-5.4 nano目前仅通过API提供,价格更低,为每百万输入Token 0.20美元,每百万输出Token 1.25美元。
作为参照,全功能的GPT-4定价为每百万输入Token 2.50美元,每百万输出Token 15.00美元。成本差异一目了然。
客户测试反馈
理论数据之外,早期客户的实测反馈或许更有说服力。
科技公司Hebbia专注于开发帮助金融、法律、科研等领域专业人士用自然语言处理海量文档的工具。其首席技术官Aabhas Sharma表示:“在同类模型中,GPT-5.4 mini提供了相当稳定的端到端性能。在我们的评估里,它在部分输出任务和引用召回率上的表现符合预期,同时成本确实降低了。更有意思的是,它的端到端通过率和来源归因能力,在某些测试中甚至超过了体量更大的GPT-5.4模型。”
另一家知名数字工作区Notion(本文正是在Notion中撰写),其AI工程负责人Abhisek Modi也分享了观察:“GPT-5.4 mini在处理定义明确的任务时,精准度很高。在页面编辑这类操作上,它处理复杂格式的能力接近GPT-5.2,但计算消耗却更低。”
Modi还补充了一个关键趋势:“过去,能稳定处理智能体工具调用的,通常只有旗舰模型。但现在,像GPT-5.4 mini和nano这样的小型模型也具备了这种能力。这无疑给用户在Notion上构建自定义智能体时,提供了更灵活、更经济的选择。”




