当多智能体成为新风口:是架构升级,还是徒增烦恼?
最近和不少技术负责人聊,发现一个有趣的现象:AI领域的“多智能体”系统,俨然成了新的技术宠儿。业内普遍将其看作是微服务架构在AI时代的一次进化。这个类比很形象——就像当年微服务把庞然大物般的单体应用拆分成一个个敏捷的小团队,多智能体也试图通过分工协作,让一群“AI专家”合力解决复杂问题。理想很丰满,但现实调研却泼了一盆冷水:超过60%的企业,在还没想清楚自己到底需要用它解决什么具体业务难题时,就已经匆忙上马。结果呢?不仅没吃到技术红利,反而让系统运维和问题排查的成本陡增。
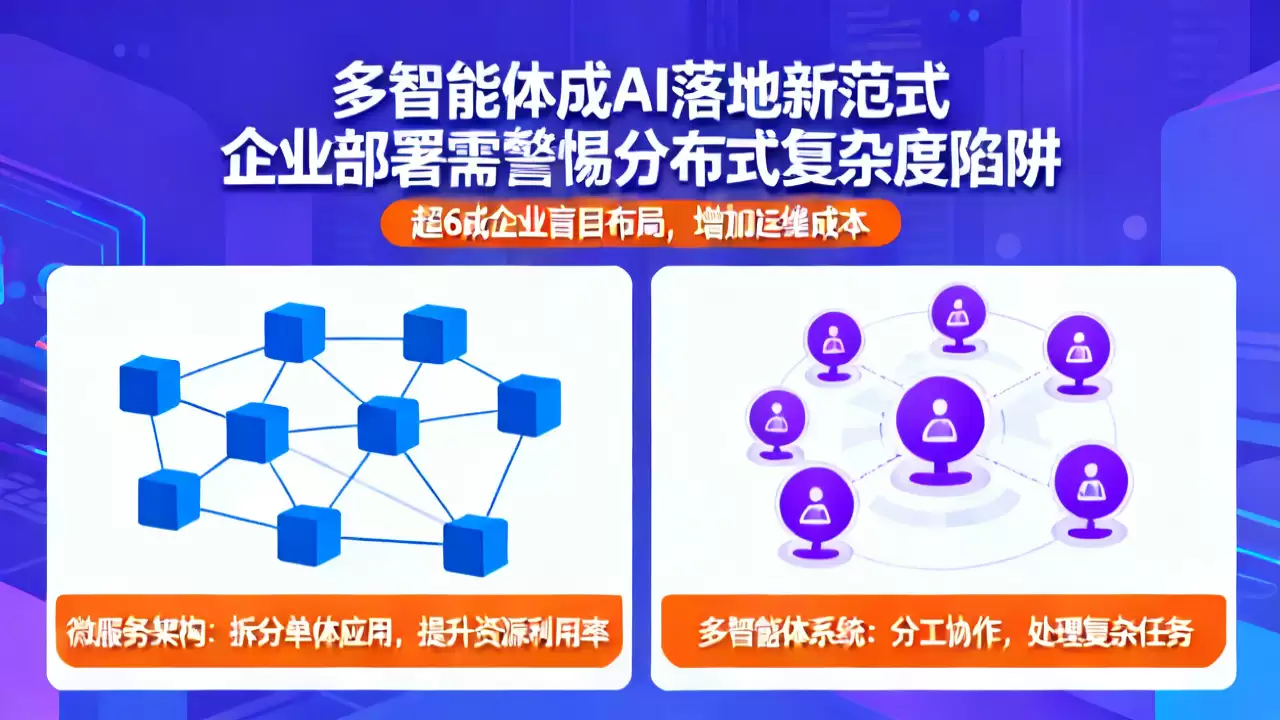
回看过去十年,微服务架构的确掀起了一场革命。它把传统IT系统中那种“牵一发而动全身”的单体结构彻底打破,代之以一个个独立部署、功能聚焦的服务单元。这么做的好处显而易见:功能更新更安全,资源利用也更高效。如今,这股“分而治之”的设计思潮,正原汁原味地在AI领域重现。可以说,多智能体系统,已经成为探索大模型如何真正落地、发挥实用价值的核心路径之一。
风向所至,巨头先行。从OpenAI、谷歌DeepMind到Anthropic,全球顶尖的AI厂商在2024年不约而同地发布了各自的多智能体开发框架。这些工具的核心思路,就是让开发者能够根据任务逻辑进行“分工”。你可以训练或调用多个在特定领域表现优异的智能体,有的负责战略规划,有的负责具体执行,有的擅长校验纠偏,有的专精复盘总结。这种“专业的人做专业的事”的协作模式,其任务完成的可靠性和质量,往往比让一个“通才”大模型单打独斗要高得多。
为什么这种模式有效?其内核与微服务如出一辙,核心就在于 **“解耦复杂任务”** 。举个例子,企业里常见的跨部门数据分析需求,往往包含数据清洗、多维度统计、结论提炼和报告可视化等一系列环节。如果全扔给一个通用大模型,它很可能顾此失彼,导致结果不稳定,速度也上不去。而将这些环节拆解,交给多个专项智能体并行处理,会发生什么?实际案例显示,整个流程的效率提升可能超过300%,最终结果的准确率也能稳定提升15%到20%。这可不是小数目。
当然,天下没有免费的午餐。多智能体在继承微服务优点的同时,也完美“继承”了它的麻烦。分布式架构天生的复杂性开始显现:智能体之间如何高效“对话”?任务状态怎样同步?一旦最终结果出了错,到底该去哪个环节“抓虫子”?这些问题会随着智能体数量的增加,变得指数级棘手。许多企业的业务根本还没遇到那个必须用分布式架构才能破解的瓶颈,仅仅为了追赶技术潮流就仓促布局,结果就是系统故障率飙升三倍以上,运维开销直接翻番,真是得不偿失。
那么,关键的决策依据是什么?业内专家的共识非常明确:一切的前提,是厘清业务场景的真实痛点。如果你的业务中,单个模型已经可以解决九成以上的问题,响应速度和准确率也在可接受范围内,那就完全没有必要为了“技术先进性”这个虚名,去强行切换到多智能体架构。它的用武之地在哪里?是那些需要融合多领域专业知识、对任务并行处理效率有极致要求的场景。只有在这里,多智能体的价值才会被充分释放。
话说回来,积极的探索已经开始。从目前的实践来看,在智能客服、研发代码辅助、复杂的供应链调度等领域,已经出现了一些经过验证的成熟多智能体方案。对于大多数企业而言,一个更稳妥的策略是:先从非核心的边缘业务场景切入,开展小范围试点。用实际数据验证投入产出比,当模型效果和经济效益都达到预期后,再考虑向核心业务环节逐步扩展。技术浪潮来了,跟风之前,先想清楚自己的船到底需要哪种帆。




