Linux 内存管理:一场由“懒惰”驱动的效率革命
Linux 内存管理的精妙之处,在于它巧妙地将几种“懒惰”哲学叠加在一起。正是这套组合拳,让系统能够在有限的内存资源上,高效地运行成百上千个进程,同时还能牢牢守住进程间的隔离墙。
上一期我们探讨文件系统时,提到了Page Cache如何占用内存,以及内核如何管理页(Page)。不少读者看完后留言追问:
“内存到底是怎么管理的?为什么32位系统每个进程有4GB地址空间,但机器只有2GB内存?malloc申请的内存什么时候才真正分配?”
今天,我们就来把这些疑问一次性彻底讲透。

一、先从一个“骗局”说起
想象这样一个场景:你写了一个C++程序,用malloc(1GB)申请1GB内存,而运行这台机器的物理内存只有512MB——结果,申请居然成功了。
void *p = malloc(1024 * 1024 * 1024); // 1GB
if (p) printf(“申请成功!\n”); // 真的会打印这句这可不是什么系统漏洞,而是Linux内存管理核心机制在起作用:虚拟内存。它从一开始,就给所有进程画了一张“大饼”。
二、虚拟内存:每个进程都有自己的“假地址空间”
Linux为每个进程都提供了一个独立的、连续的地址空间幻觉,这就是虚拟地址空间。在64位系统上,这个空间理论上有128TB之巨(实际可用的用户空间也接近这个数字)。但请注意,这仅仅是“地址”,并非真实的内存。虚拟地址必须经过MMU(内存管理单元)的翻译,才能对应到真实的物理内存页。
下面这张图清晰地展示了虚拟地址空间的完整布局:
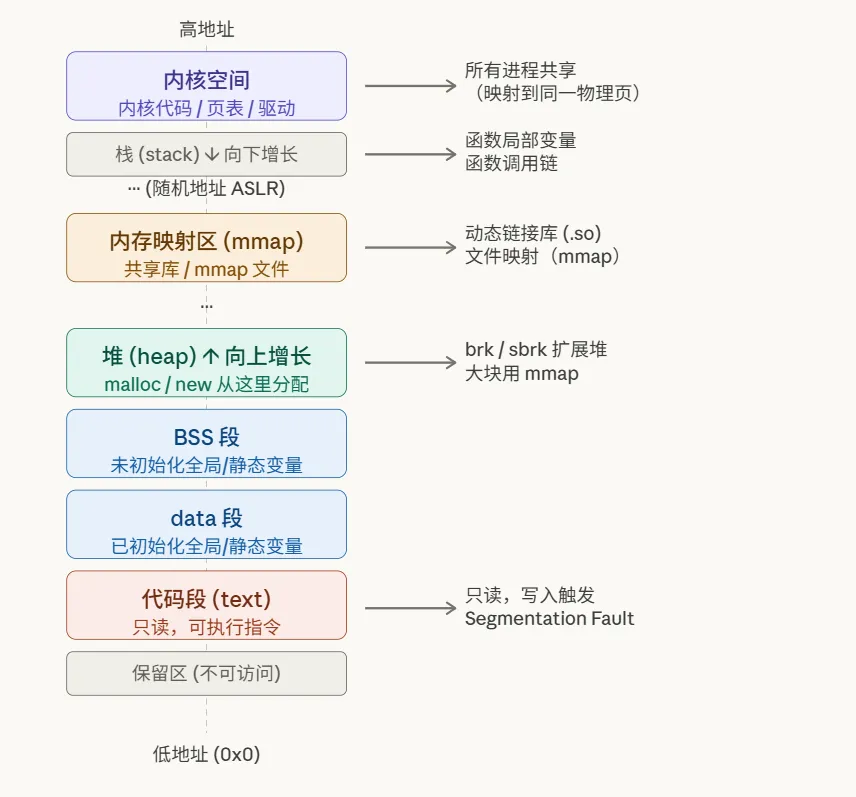
进程的虚拟地址空间从低到高依次是:
- 保留区(0x0附近):不可访问,空指针解引用崩溃就发生在这里。
- 代码段(text):只读可执行,存放程序指令。
- 数据段:已初始化的全局/静态变量。
- BSS段:未初始化的全局/静态变量(运行时清零)。
- 堆(heap):向上增长,
malloc/new从这里分配内存。 - 内存映射区(mmap):共享库、文件映射、大块
malloc的归宿。 - 栈(stack):向下增长,存放函数局部变量和调用链。
- 内核空间:所有进程共享,映射内核代码和数据。
三、虚拟地址到物理地址:MMU和页表
虚拟地址空间是“假的”,CPU真正访问内存时,必须把虚拟地址翻译成物理地址。这个翻译工作由硬件MMU完成,而翻译的依据,则是内核维护的页表。
Linux以4KB为一页(Page)为单位管理内存。虚拟地址被分成几段索引,通过逐级查询页表,最终得到物理地址:
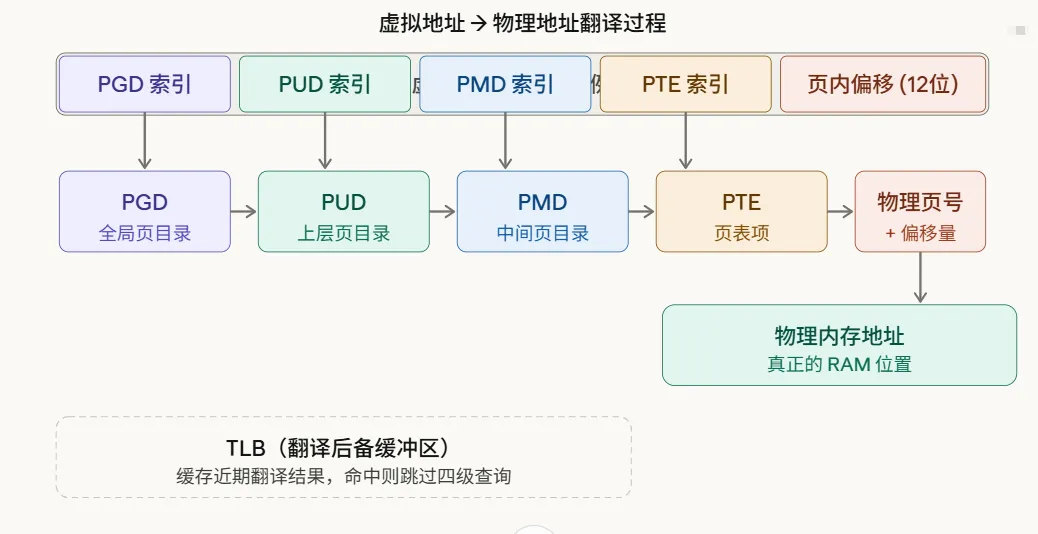
在Linux x86-64架构下,采用四级页表(PGD → PUD → PMD → PTE)结构。这意味着一次地址翻译最多可能需要四次内存访问。为了提速,CPU内部有一个TLB(翻译后备缓冲器)缓存最近的翻译结果。一旦命中,就能直接得到物理地址,完全跳过繁琐的四级查询。
四、缺页中断:内存是“用时才分配”的
现在回到文章开头那个问题——malloc(1GB)为什么能在512MB的机器上“成功”?
答案是:malloc的“成功”,仅仅是在虚拟地址空间里预留了一段地址范围,并没有立刻分配物理内存。物理内存的分配,要等到你真正去访问那个地址时才会发生。
这套机制叫做缺页中断,堪称Linux内存管理最精妙的设计之一。
char *p = malloc(1024 * 1024 * 1024); // 只分配虚拟地址,物理页未分配
p[0] = ‘A’; // 第一次写入:触发缺页中断!内核此时才真正分配物理页
p[1] = ‘B’; // 这个物理页已存在,直接写入即可缺页中断的完整流程如下:
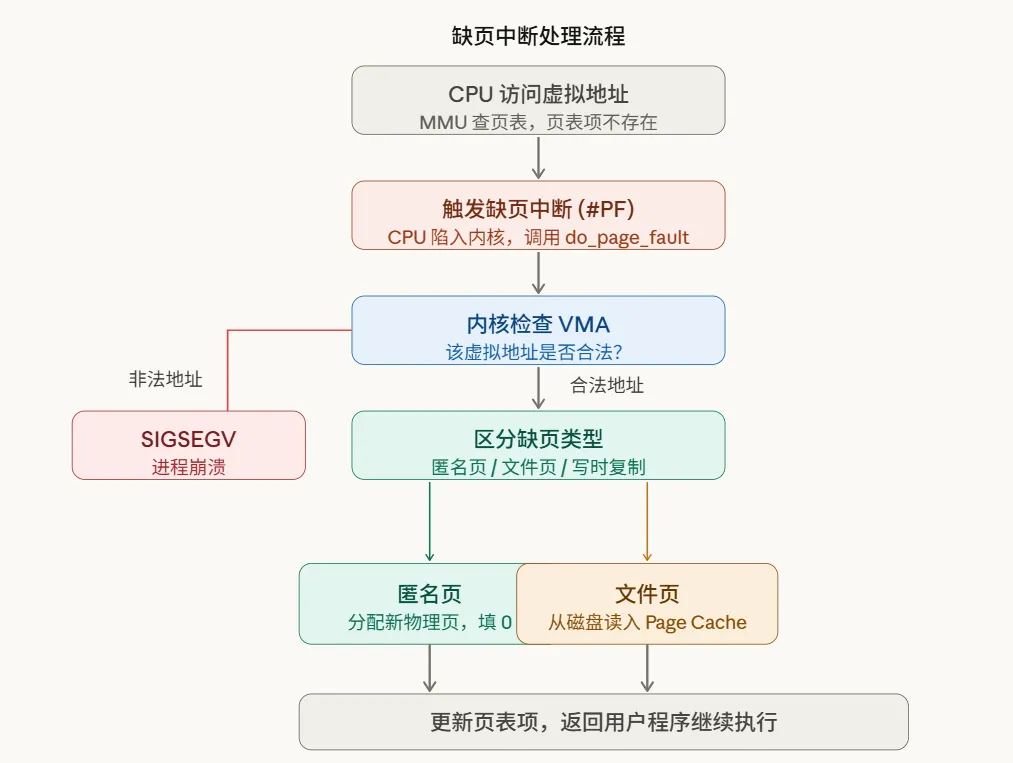
缺页中断主要有三种典型场景:
- 匿名页缺页:
malloc后第一次访问,内核分配新的物理页,清零后映射。 - 文件页缺页:
mmap映射文件后第一次访问,内核从磁盘读取数据到Page Cache。 - 写时复制(COW)缺页:
fork()后子进程尝试写入父进程的页,内核会复制一份新的物理页给子进程。
五、fork()与写时复制:最优雅的懒惰
fork()创建子进程时,子进程理论上需要复制父进程的全部内存。如果父进程有1GB数据,难道每次fork()都要拷贝1GB吗?
Linux用写时复制(Copy-On-Write,COW)完美解决了这个问题。fork()之后,父子进程共享同一批物理页,页表项都被标记为只读。谁第一个尝试写入,才会触发缺页中断,内核此时才会复制一份新的物理页给写入方。如果没有写操作,物理页就永远不需要复制。
int main() {
char *buf = malloc(4096);
strcpy(buf, “hello”);
pid_t pid = fork(); // fork后父子共享物理页,页被标记为只读
if (pid == 0) {
buf[0] = ‘H’; // 子进程写入 → 触发COW缺页 → 子进程获得独立副本
}
// 父进程的buf依然是“hello”,不受影响
}这就是为什么fork()操作极其快速——无论父进程占用了多少内存,fork()本身的耗时几乎是恒定的。
六、malloc的真相:不只是向内核要内存
很多人以为malloc就是直接调用系统调用向内核要内存。其实不然。
malloc是C标准库(通常是glibc)提供的函数,它在内核和用户程序之间做了一层高效的内存池管理:
- 首次
malloc:调用brk()或mmap()向内核申请一大块内存。 - 后续
malloc:从glibc已申请的内存池里切割,无需再进入内核。 free:把内存块还给glibc的内存池,但不一定立刻还给内核。- 内存池空闲块过多时:glibc才会调用
brk()或munmap()将部分内存归还给内核。
用户程序 glibc (ptmalloc) 内核
│ │ │
├── malloc(64B) ────────► │ 从内存池切一块 │
│ │ 池空了? ──brk(+128KB)──► │
│ │ ◄── 映射新虚拟内存 ──────┤
├── free(p) ────────► │ 放回内存池 │
│ │ 池太大? ──brk(-64KB)───► │ 还给内核这也解释了为什么内存泄漏有时难以从系统层面立刻察觉:free之后,内存可能仍然留在glibc的池里,进程占用的RSS(常驻内存)不会立刻下降,但从业务逻辑上看,内存已经“泄漏”了。
七、内存大小那些概念:VSZ、RSS、PSS傻傻分不清?
在top命令里看到的各种内存数字,常常让人困惑:
VIRT RES SHR
2.1g 156m 42m- VIRT(VSZ):虚拟内存大小,包含了进程所有映射的虚拟地址空间,通常远大于实际使用的物理内存。
- RES(RSS):常驻内存大小,进程实际占用的物理内存(包含共享库占用的部分)。
- SHR:与其他进程共享的物理页(主要是共享库.so文件)。
所以,一个进程实际独占的物理内存,大致可以估算为:RSS - SHR。看到VIRT很大不必惊慌,关键要看RSS和SHR。
八、内存回收:内核什么时候把内存要回去?
当物理内存不够用时,内核的kswapd进程就开始扮演“清道夫”的角色,回收内存:
- 干净的文件页(clean page):直接丢弃(因为磁盘上有原始数据,需要时重新读取即可)。
- 脏的文件页(dirty page):先写回磁盘,再丢弃。
- 匿名页(anonymous page):写入swap分区,腾出物理内存。
当内存压力极大,上述回收机制仍无法满足需求时,就会触发最后的“杀手锏”——OOM Killer。内核会强行选择一个进程杀掉以释放内存。
# 系统日志里看到这个就是 OOM 了
kernel: Out of memory: Kill process 1234 (myapp) score 900 or sacrifice childOOM Killer根据“最该死”的分数(oom_score)来选择目标。通常,内存占用大、运行时间短的进程得分最高,最容易被终结。可以通过调整进程的oom_score_adj值来保护重要进程。
九、高频面试题精析
Q:32位系统每个进程有4GB虚拟空间,但物理内存只有2GB,能运行多少个进程?
理论上可以运行很多个。因为每个进程的虚拟地址空间是独立的,物理页是按需分配的(触发缺页中断时才分配)。更重要的是,多个进程的代码段、共享库可以映射到同一物理页,这能大量节省内存。
Q:malloc(0)返回什么?
C语言标准规定,malloc(0)应返回一个非NULL的唯一指针(该指针可以被free),但指向的内存大小为0,不可解引用。glibc的实现确实会返回一个合法的指针。
Q:free之后内存会立刻归还给操作系统吗?
通常不会。glibc的free只是把内存块放回自己的内存池。只有当内存池中的空闲块超过一定阈值时,glibc才会调用sbrk()或munmap()将内存归还给内核。这也是为什么使用Valgrind检测内存泄漏时,要求程序退出前必须free所有内存,否则工具无法区分是“真泄漏”还是“内存仍在glibc池中”。
Q:为什么栈溢出(stack overflow)会直接崩溃,而不是触发缺页中断分配新内存?
内核在栈的底部预留了一个不可访问的保护页(guard page)。当栈溢出时,访问会触及这个保护页,从而触发缺页中断。内核检查对应的VMA(虚拟内存区域)后,发现这是非法访问,于是直接向进程发送SIGSEGV信号,导致其崩溃。
结语
说到底,Linux内存管理的核心思路,是几种“懒惰”哲学的叠加与协同:
- 虚拟内存:先分地址,物理内存用时再说。
- 缺页中断:访问才分配,按需加载。
- 写时复制:fork时不复制,写时才复制。
- glibc内存池:批量向内核要,批量给用户用。
正是这几大机制的精妙组合,让Linux得以在有限的内存资源上,高效、稳定地运行海量进程。
透彻理解这些机制,你才能真正读懂内存泄漏检测工具的原理,明白为什么高性能程序需要自定义内存池,也才能在面试中,将“内存管理”这道题讲得深入&浅出,令人信服。




