ACL 2026|清华新作ControlAudio:声音何时响、说啥话?都能按剧本可控生成!
让AI“听话”:清华团队提出ControlAudio,精准控制音频生成的时间与内容
文本到音频生成技术近年来取得了突破性进展。从早期只能合成简单的提示音,到如今基于扩散模型,已经能够根据“森林中的鸟鸣声”等复杂描述,生成高度逼真的环境音效。这为影视后期、游戏开发及多媒体内容创作开辟了广阔前景。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
然而,仅仅实现“逼真”还远远不够,专业应用场景更要求“精准”。现有技术普遍面临两大核心挑战:一是难以精确控制特定声音事件的发生时间,例如无法确保鸟鸣声严格限定在音频的第2至5秒;二是在生成包含人声语音的内容时,其清晰度与可懂度往往难以保障。这好比一位技法纯熟的画家,却难以精确控制每一笔色彩的落点与形态。
针对这一行业痛点,清华大学的研究团队近期提出了一种创新解决方案——ControlAudio。其核心设计思路明确:通过一套系统化的数据构建流程,结合“渐进式扩散建模”策略,在一个统一的框架内,实现对音频时序结构与语音内容的联合精准控制。简而言之,它让AI在合成声音时,既能“卡准时间点”,又能“说清人话语”。
该研究的第一作者是清华大学博士生江宇轩,其研究方向集中于生成模型与多模态学习,由朱军教授与窦维蓓教授共同指导。目前,这项研究成果已被自然语言处理顶级会议ACL 2026接收,并获推荐为口头报告,充分体现了其学术创新性与业界影响力。

论文地址:https://arxiv.org/abs/2510.08878
效果试听:https://control-audio.github.io/Control-Audio
研究背景:精细化控制是音频生成的下一个关键突破点
当前的主流文生音频系统在生成高保真度声音方面已成果显著。但要真正满足影视配音、交互式媒体等专业领域的需求,实现精细化控制已成为必须攻克的技术难关。具体而言,挑战主要集中在两个维度:
精确的时间控制:用户需要能够指定声音事件发生的具体时间区间。例如,输入指令“鸟儿在2至5秒间鸣叫”,模型必须准确地将鸟鸣事件锚定在此时间窗口内,而非随机分布。
清晰的语音生成:当描述中包含具体语音内容时,如“一名男子说:‘今天天气真好’”,生成的音频不仅需要包含人声,其语音内容还必须高度清晰、易于理解。
实现上述控制面临巨大困难,首要障碍在于数据。现实中,同时具备精确时间戳标注和语音转录文本的音频数据极为稀缺,导致模型训练“无米下炊”。此外,现有方法大多孤立地解决时间控制或语音清晰度问题,缺乏一个能够协同处理多维度控制的统一框架。
核心方法:三步走策略,实现从宏观到微观的全面掌控
那么,ControlAudio是如何突破这些限制的呢?其整体方法论可归纳为三个紧密衔接的核心环节:
数据构造与表征:采用“真实标注数据与仿真生成数据相结合”的策略构建多层次训练数据。关键创新在于设计了一种“结构化提示词”,将文本描述、时间信息、音素序列等控制信号统一编码,使得预训练好的文本编码器能够直接解析这些复杂的多模态指令。
渐进式模型训练:采用分阶段训练策略。模型并非一次性学习所有控制能力,而是分三步进阶:首先,在大规模文本-音频配对数据上进行预训练,奠定高质量声音生成的基础;其次,引入时间标注信息进行微调,学会控制声音事件的时序布局;最后,融入音素级别信息进行联合训练,掌握生成清晰、可控语音的精细能力。
引导式推理采样:在生成阶段,同样贯彻“由粗到细”的理念。在扩散过程的早期阶段,主要利用文本和时间条件进行引导,初步确定声音场景的整体时间框架;在生成后期,则增强音素条件的引导权重,用以精细化雕琢语音内容的清晰度和准确性。这一过程模拟了人类创作时先构思大纲、再填充细节的思维模式。
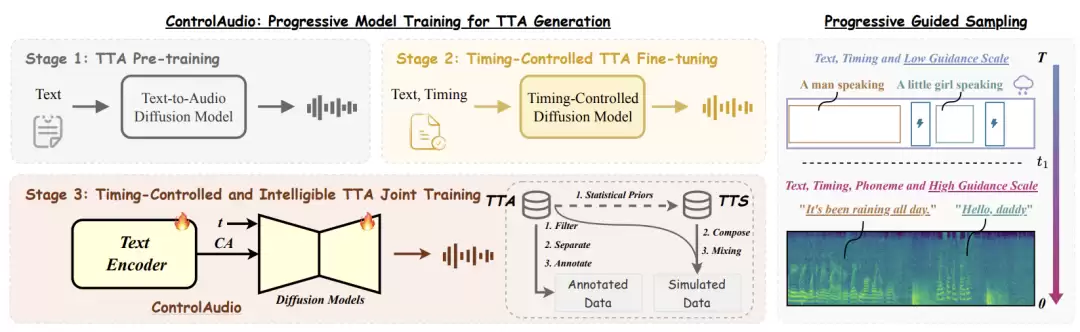
渐进式扩散建模:分解复杂控制任务的艺术
ControlAudio将多条件音频生成这一复杂任务,巧妙地分解为一个渐进学习过程。这充分利用了扩散模型“先生成整体轮廓,再逐步添加细节”的内在特性。
在训练层面,模型遵循三步学习路径:第一步,掌握“根据文本生成对应声音”的基本能力;第二步,在已有基础上,学习“控制声音事件发生时间”的技能;第三步,综合前两者,最终习得“生成指定语音内容”的高级控制。通过使用“纯文本”、“文本+时间”、“文本+时间+音素”等不同组合的条件输入,模型对控制信号的理解得以逐步深化和精细化。

在推理生成时,与之对应的渐进式引导采样策略便发挥作用。早期依赖时间和文本条件勾勒大体布局,后期则依靠强音素条件精修语音细节。这种设计与扩散模型本身的生成节奏高度契合,从而在时间对齐精度和语音可懂度方面均取得了更优的性能。
数据集构建:真实数据与仿真数据的双引擎驱动
如前所述,数据稀缺是核心瓶颈。ControlAudio的应对方案是构建一个多源混合的数据体系,兼具真实数据的准确性与仿真数据的规模优势。
在真实数据方面,研究团队以带有时间标注的AudioSet-SL数据集为基底,筛选出包含人声的音频片段,并借助语音分离与自动语音识别技术,获得了“文本-时间-音素-音频”四位一体的细粒度标注数据。
为弥补真实数据量的不足,团队开发了一套大规模的仿真数据生成管线:首先从真实数据中统计分析出人声活动的分布模式,随后依据此规律合成单人或多人语音片段,再按照合理的时间线进行编排,并与背景环境音混合,从而创造出丰富多样的复杂音频场景。这一流程额外生成了超过17万条高质量训练样本,极大提升了数据的规模与多样性。
此外,为了提升模型对复杂自然语言指令的理解能力,团队引入了基于“思维链”的自动解析流程。该流程能将如“鸟儿在开头鸣叫,然后一个男人说‘你好’”这样的自然描述,自动分解为“事件—时间—语音内容”的清晰结构化表示,作为模型的精确输入。这相当于将模糊的用户意图,翻译成了机器可精准执行的指令代码。

实验结果:性能全面领先,验证统一框架优越性
方法的有效性需要通过严谨的实验来验证。团队首先在时间可控音频生成任务上进行了评估。如图5所示,在衡量事件时间对齐精度的关键指标上,ControlAudio相比现有前沿方法取得了显著提升。同时,在FAD(弗雷歇音频距离)、CLAP得分等评估整体音频保真度与语义相关性的指标上,它也保持了竞争优势,部分指标表现更优。

在包含语音生成的评测任务中(图6),ControlAudio同样展现出强大性能,其生成的语音可懂度更高,整体音频质量也更佳。这充分证明了其统一框架能够有效协同解决时间控制与内容生成两大难题。

尤为重要的是,ControlAudio在追求精细化控制的同时,并未牺牲其基础的文本到音频生成能力。如图7所示,在标准的文生音频基准测试上,它的表现与当前主流方法相当,甚至有所超越。这表明该方法是在增强模型能力,而非进行性能取舍。

总结与展望:迈向通用可控的音频生成
总体而言,ControlAudio从数据构建、模型训练到推理生成,系统性地解决了文本到音频生成中的精细化控制挑战。其核心贡献在于,首次在一个端到端的框架内,实现了对文本语义、时间结构与语音内容三者的协同建模与联合控制,并在实际效果上超越了以往专注于单一维度的解决方案。
这项工作展现了强大的通用性与扩展潜力。随着多模态生成模型的持续演进,统一建模语音、音效、音乐已成为明确的技术趋势。ControlAudio所采用的“多粒度条件统一编码”与“渐进式生成”相结合的技术路线,恰好为通向通用、可控的音频生成系统,提供了一条清晰且可扩展的实现路径。其长远目标在于推动AI音频生成技术从执行单一任务,迈向驾驭复杂、多维度要求的创造性内容生产。未来,创作者或许能像指挥家一样,精准地指挥AI生成每一个音符与声效。
相关攻略

摘要 当传统音乐流媒体平台还在沿用数十年前的版税结算模式时,一个基于区块链的新型平台正在悄然改写游戏规则。Audius不仅实现了艺术家实时获得收益的突破,更通过代币经济构建了一个创作者、听众、节点运营者三方共赢的生态系统。 什么是 Audius? 不妨把Audius理解为音乐流媒体领域的 "去中心化革

IT之家 1 月 23 日消息,科技媒体 Notebook Check 昨日(1 月 22 日)发布博文,报道称高端音频品牌 Meze Audio 发布 Strada 封闭式动圈耳机,主打“高解析力

IT之家 1 月 15 日消息,据阶跃星辰最新微信公众号消息,阶跃星辰开源模型 Step-Audio-R1 1,拿下全球第一。阶跃星辰称,全球知名权威大模型评测榜单 Artificial Analy

新智元报道编辑:LRST【新智元导读】文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audi

12 月 17 日消息,Meta 今日发布了首个统一的多模态音频分离模型 —— SAM Audio。Meta 表示 SAM Audio 是一个“最先进的统一模型”,通过使用自然的、多模态的提示,使
热门专题







热门推荐

不再区分社区 旗舰版:IntelliJ IDEA 2025 3 正式统一,免费功能扩展、使用体验更顺畅 就在昨天,也就是12月8日,开发者工具领域的标志性事件发生了——IntelliJ IDEA 2025 3版本正式与大家见面。 从这个版本开始,一个持续多年的历史性划分被打破了。JetBrain

HOME币:当区块链叩开房地产的大门 在加密货币的浪潮中,总有一些项目试图解决现实世界的真问题。HOME币便是这样一个存在——它不满足于仅仅作为一种数字资产,而是将目光投向了价值数十万亿美元的全球房地产市场,试图用区块链技术重构这个古老行业的交易逻辑。 那么,这个由匿名创始人“Homer”发起的项目

Windows 11中如何开启Telnet服务? 在进行远程连接或设备调试时,有时会需要用到Telnet这个经典的工具。不过,升级到Windows 11后,不少朋友发现这个功能“藏”得更深了,一时找不到开启的入口。其实,它并没有消失,只是需要通过“可选功能”来手动添加。下面这个清晰的步骤指南,能帮你

“倾家荡产”为结婚!宝可梦粉丝拍卖价值30万稀有卡牌 最近有个挺有意思的事儿:一位宝可梦粉丝在自家阁楼里翻出了三张稀有卡牌,结果拍卖所得,正好够支付他今年夏天的婚礼费用。这事儿听起来像电影情节,但还真就发生了。 主角是来自英国多塞特郡温伯恩的安德鲁·布劳德。就在上周,他在英格兰萨里郡的伊班克拍卖行,

希望城官网首页登录入口网址 在当下竞争激烈的模拟经营手游市场中,《希望城》以其独特的“反内卷”设计理念脱颖而出,为玩家精心打造了一个远离现实压力的数字疗愈空间。其官方网站登录入口为:https: www hope-city cn。在这里,你将告别体力值限制的束缚,无需被强制任务追赶进度,更能彻底摆