1. MongoDB查询架构总览
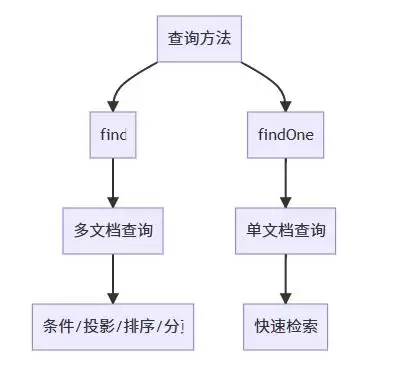
精通MongoDB查询,如同掌握一套高效的数据导航系统。它不仅是简单的数据检索,更是实现精准、高性能数据访问的关键。下图为您清晰地勾勒出这套强大查询体系的完整路线图,是您深入学习和实践的最佳指引。
2. 核心查询方法详解
2.1 find()方法 - 多文档查询
基本语法:
db.collection.find(, // 查询条件 // 投影(字段控制) ). () // 游标方法
这段代码堪称MongoDB查询的“万能钥匙”。它主要执行三个核心操作:定义筛选目标(查询条件),指定返回字段(投影),以及对结果集进行后续操作(游标方法)。其标准工作流程直观且高效。
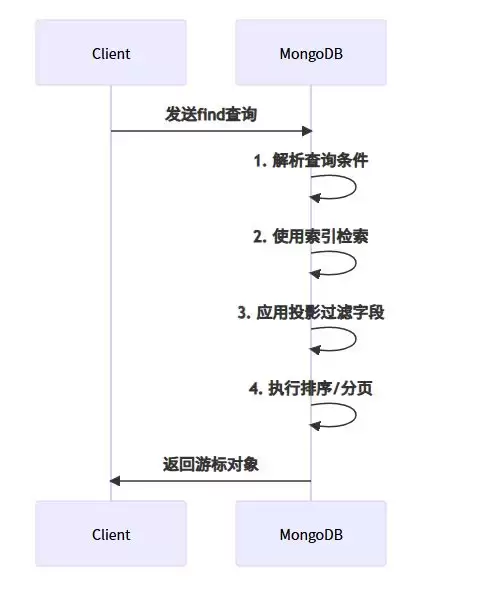
2.2 findOne()方法 - 单文档查询
当您需要快速获取单个匹配文档时,findOne()方法是最佳选择。它与find()方法功能相似但适用场景不同,理解其差异至关重要。
特点对比:
| 特性 | find() | findOne() |
|---|---|---|
| 返回结果 | 游标对象 | 文档对象/null |
| 性能 | 需迭代获取结果 | 立即返回单个结果 |
| 适用场景 | 批量数据检索 | 主键或唯一条件查询 |
一个典型应用是用户登录验证:根据用户名快速查找唯一用户记录,同时出于安全考虑,在返回结果中排除敏感字段如密码。
// 示例:用户登录查询
const user = db.users.findOne(
{ username: "alice123" },
{ password: 0 } // 排除密码字段
);
3. 查询条件深度解析
3.1 比较操作符大全
实现灵活高效的MongoDB数据筛选,离不开丰富的查询操作符。它们如同强大的“数据过滤器”,上图为您提供了快速参考指南。以下是如何在实战中组合使用它们的示例:
// 范围查询
db.products.find({
price: { $gt: 100, $lte: 500 },
stock: { $exists: true }
});
// 数组查询
db.users.find({
tags: { $in: ["vip", "premium"] },
age: { $nin: [18, 19, 20] }
});
3.2 逻辑操作符组合
面对复杂的业务查询逻辑,$and, $or, $not等逻辑操作符便大显身手。它们能够将简单的条件组合成复杂的查询逻辑网络。
复杂条件构建:
// AND/OR/NOT组合
db.orders.find({
$and: [
{ status: "completed" },
{ $or: [
{ payment: "credit" },
{ amount: { $gt: 1000 } }
]},
{ $not: { userType: "trial" } }
]
});
4. 高级查询技巧
4.1 聚合管道查询

当基础查询无法满足分组统计、数据转换或复杂计算需求时,MongoDB聚合管道便是您的“数据处理流水线”。它通过一系列有序的阶段(Stage)对数据进行加工,逻辑清晰,功能强大。
实际应用:
db.sales.aggregate([
{ $match: { date: { $gte: new Date("2023-01-01") } } }, // 阶段1:筛选
{ $project: { product: 1, total: { $multiply: ["$price", "$quantity"] } } }, // 阶段2:计算新字段
{ $group: { _id: "$product", totalSales: { $sum: "$total" } } }, // 阶段3:按产品分组求和
{ $sort: { totalSales: -1 } }, // 阶段4:排序
{ $limit: 10 } // 阶段5:取Top 10
]);
4.2 索引优化策略
缺乏索引的查询,犹如在无目录的图书馆中盲目翻找。而合理的索引设计,则是通往高性能查询的捷径。如何设计高效索引?业界广泛推崇ESR规则:
- E (Equality) 等值查询字段 – 优先考虑
- S (Sort) 排序字段 – 其次考虑
- R (Range) 范围查询字段 – 最后考虑
掌握规则后,可以应用更高级的优化技术:覆盖查询。当查询所需的所有字段都包含在索引中时,数据库可直接从索引返回结果,无需访问原始文档,从而极大提升查询速度。
// 创建符合ESR规则的复合索引
db.users.createIndex({ age: 1, status: 1 });
// 覆盖查询示例:只查询索引中包含的字段
db.users.find(
{ age: { $gt: 25 }, status: "active" },
{ _id: 0, age: 1, status: 1 } // 投影字段都在索引中
).explain("executionStats"); // 使用explain验证
5. 查询结果处理
5.1 游标控制方法
使用find()获取游标仅是第一步,一系列游标方法让您能够像指挥家一样,灵活控制最终结果的呈现方式。
| 方法 | 描述 | 示例 |
|---|---|---|
| sort() | 结果排序 | .sort({ age: -1 }) |
| limit() | 限制数量 | .limit(10) |
| skip() | 跳过文档 | .skip(20) |
| count() | 文档计数 | .count() |
| pretty() | 格式化输出 | .pretty() |
5.2 分页查询实现
分页是Web应用的核心功能,但直接使用skip()和limit()在大数据量时存在性能瓶颈。以下提供一个更健壮的优化函数示例,它不仅返回分页数据,还一并提供总记录数,便于前端生成完整的分页导航。
// 分页函数
function paginate(collection, query, page = 1, pageSize = 10) {
const skip = (page - 1) * pageSize;
return {
data: collection.find(query).skip(skip).limit(pageSize).toArray(),
total: collection.countDocuments(query), // 获取满足条件的总数量
page,
pageSize
};
}
// 使用示例:获取电子产品类别的第二页数据
const result = paginate(db.products, { category: "electronics" }, 2);
6. 生产环境最佳实践
6.1 查询性能优化
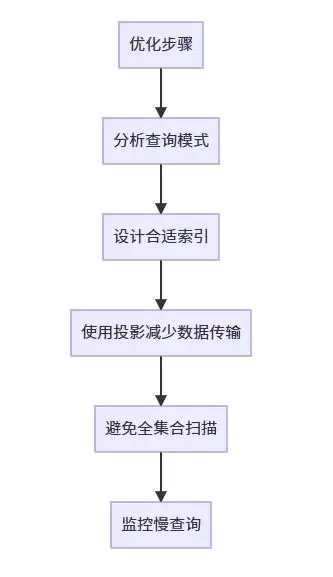
查询性能优化是一个系统工程。上图系统性地展示了从查询语句编写到硬件资源配置的完整优化路径。遵循此路径,可以有效规避大多数常见的性能陷阱。
6.2 安全查询规范
查询安全与性能同等重要。请务必关注以下两点:
- 查询注入防护:绝对避免动态拼接查询条件,尤其禁止使用
eval。应始终使用驱动程序提供的安全参数化方式构建查询。
// 危险:绝对要避免!
const query = eval(`({ ${userInput} })`);
// 安全做法:构造明确的查询对象
const query = { status: userInputStatus };
- 结果大小限制:未加限制的查询可能耗尽内存或拖垮服务。务必在数据库配置和应用程序查询中设置合理的上限。
// 设置单个文档最大BSON大小(服务器级)
db.runCommand({ setParameter: 1, maxBSONSize: 16777216 });
// 查询时添加硬性数量限制(应用级)
db.logs.find().limit(1000);
7. 特殊查询场景
7.1 全文检索
对于文章、评论等大段文本内容的搜索,简单的正则匹配效率低下。MongoDB的文本索引能够帮助您实现高效的全文检索功能。
// 创建文本索引
db.articles.createIndex({ content: "text" });
// 文本搜索查询,并按照相关性排序
db.articles.find(
{ $text: { $search: "mongodb tutorial" } },
{ score: { $meta: "textScore" } } // 获取相关性评分
).sort({ score: { $meta: "textScore" } });
7.2 地理空间查询
处理地理位置数据是MongoDB的强项。无论是寻找附近的商家,还是分析地理围栏,都能轻松实现。
// 创建2dsphere地理空间索引
db.places.createIndex({ location: "2dsphere" });
// 查询附近1公里内的地点
db.places.find({
location: {
$near: {
$geometry: {
type: "Point",
coordinates: [longitude, latitude] // 中心点坐标
},
$maxDistance: 1000 // 距离限制,单位米
}
}
});
8. 性能监控与诊断
8.1 explain() 分析
想了解查询为何缓慢?explain()方法就是您的诊断工具。它能详细展示查询执行的每个步骤、使用的索引以及扫描的文档数量。
// 获取查询执行计划的详细统计信息
const explanation = db.orders
.find({ status: "shipped", amount: { $gt: 100 } })
.explain(“executionStats”);
// 聚焦几个关键性能指标
console.log({
executionTime: explanation.executionStats.executionTimeMillis, // 执行时间(毫秒)
totalDocsExamined: explanation.executionStats.totalDocsExamined, // 检查的文档数
indexUsed: explanation.executionStats.executionStages.inputStage.indexName // 使用的索引名
});
8.2 慢查询日志
除了主动分析,建立被动监控体系同样重要。开启慢查询日志,让数据库自动记录并暴露需要优化的操作。
// 启用分析器,记录所有执行时间超过50毫秒的操作
db.setProfilingLevel(1, 50);
// 定期查看和分析慢查询日志,找出性能瓶颈
db.system.profile
.find({ op: "query", millis: { $gt: 100 } }) // 查找耗时超过100ms的查询
.sort({ ts: -1 }) // 按时间倒序
.limit(10); // 查看最近10条
总而言之,掌握MongoDB查询的精髓,在于平衡艺术性与科学性:既要灵活运用各类操作符和聚合管道构建精准查询(艺术),又要严格遵循索引设计与性能优化原则(科学)。将本文介绍的技巧与最佳实践融入日常开发,您将能从容地从海量数据中快速获取有价值的洞见。
希望这份全面的MongoDB查询优化指南,能成为您提升数据库应用性能的得力助手。




