昨天下午,沉寂许久的 DeepSeek 又有新动作了!
不过,正如官方在PR中特意说明的,这次更新和模型本身无关,重点落在了其底层代码库DeepGEMM上。
然而,正是这次看似常规的代码更新,露出了一个关键的新名词:Mega MoE。

相关链接:https://github.com/deepseek-ai/DeepGEMM/pull/304
这个Mega MoE项目,由DeepSeek基础设施团队的Chenggang Zhao等人贡献。
Mega MoE 是什么?
如何理解这个新概念?不妨先看看X上网友“思维怪怪的”一个生动比喻:
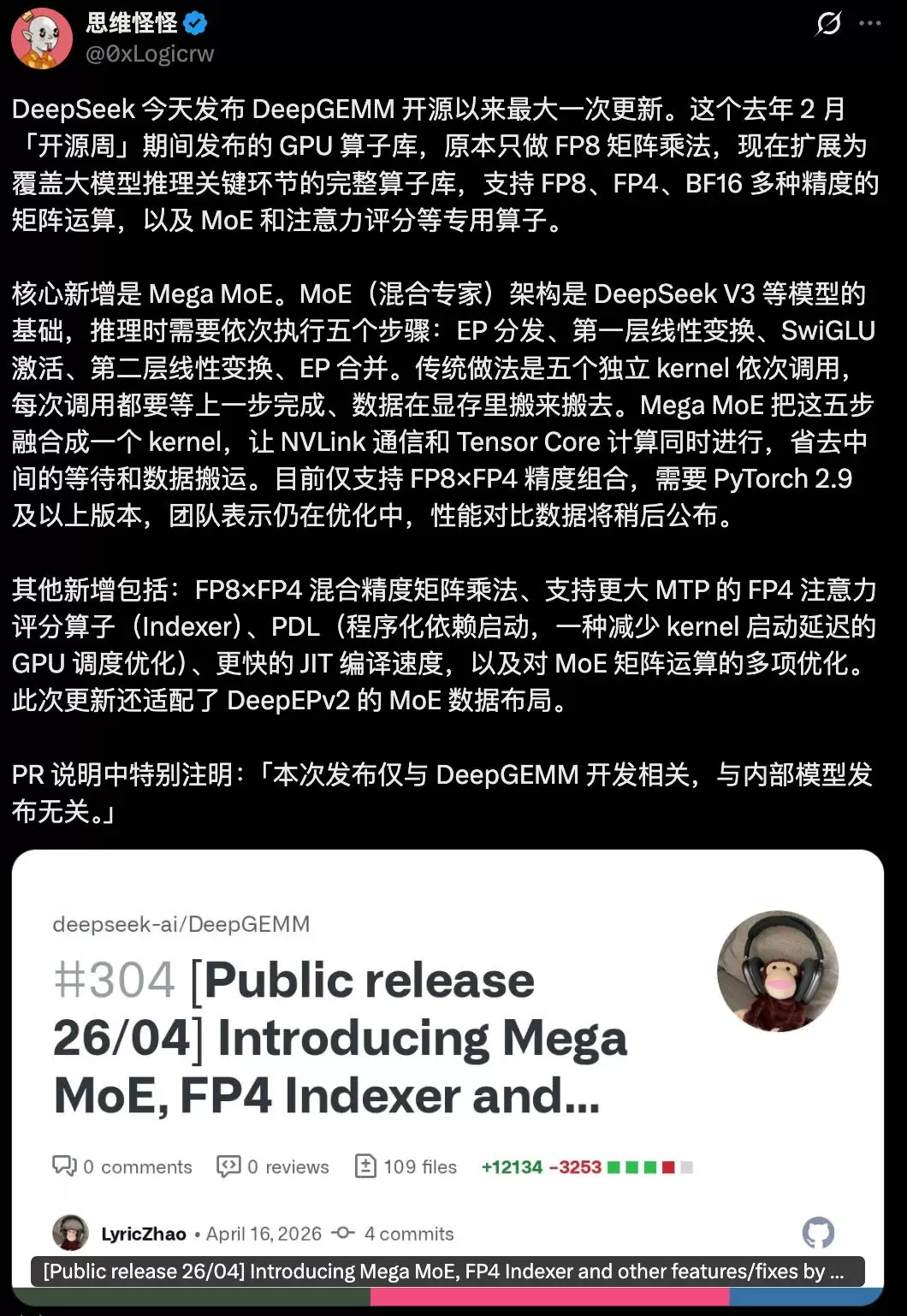
来源:https://x.com/0xLogicrw/status/2044720884066451645
简单来说,Mega MoE干了一件“化零为整”的事。它把原本分散、割裂的一整套MoE计算流程,彻底揉合成一个整体,力求在GPU上一次性跑完。
传统的MoE实现,好比一条被拆分成多个独立工位的流水线。Token需要先被分发(dispatch)到不同的专家网络,然后进行一层线性变换,接着通过激活函数(比如SwiGLU),再来一层线性变换,最后才能把结果收集(combine)回来。流程听起来清晰,但实际运行时,每一步都得启动一个独立的内核(kernel),中间还穿插着大量的GPU间数据通信。
于是,一种典型的低效场景就出现了:计算一会儿,等待一会儿;传输一会儿,再计算一会儿。GPU的算力就在这种频繁的启停和等待中被白白浪费。
而Mega MoE的目标,就是把这整条流水线“焊死”。它将分发、两层线性层、SwiGLU激活、结果合并这些步骤,全部融合(fuse)进一个单一的“超级内核”(mega-kernel)里。更关键的是,它不止步于步骤合并,还做了一件更彻底的事:实现计算与通信的重叠。
换句话说,让Tensor Core执行计算的同时,NVLink同步进行数据传输,双方不再互相等待。
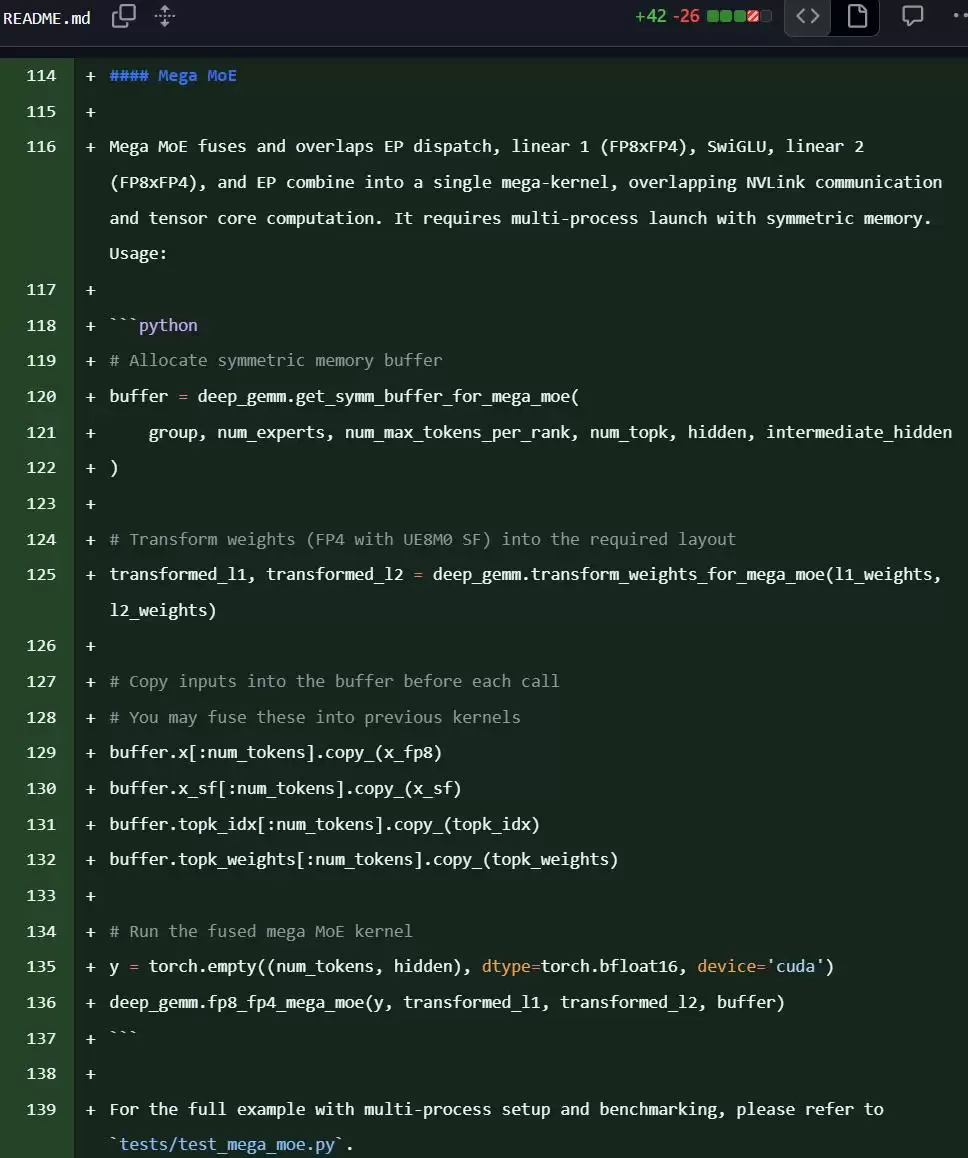
这么做的影响非常直接:GPU的停顿大幅减少,利用率显著提升。尤其是在多卡、大规模MoE模型的应用场景下,这种优化带来的速度提升是可以被直接感知的。这就好比把原来一组人接力搬砖,换成了一条永不停歇的自动化传送带。
当然,DeepSeek这次的野心显然不止于做出一个“更快的kernel”。你能清晰地感觉到,他们正在朝一个方向持续攻坚:将MoE的潜力压榨到极限。
例如,他们开始尝试FP8与FP4混合精度这样的组合,甚至还为MQA logits设计了一个FP4的索引器(indexer)。这类操作,基本是在试探“计算还能不能再省一点”的终极边界。再加上对GEMM算子的重构、利用JIT(即时编译)进行加速,种种迹象表明,DeepSeek正致力于将其AI基础设施打磨得更为强劲和高效。
有个细节值得玩味:团队明确表示,Mega MoE仍在积极开发中,具体的性能数据“容后再禀”。这其实很符合这类深度优化的特点——它往往不是一版代码就能定型,而是需要在不同模型规模、不同硬件拓扑、不同工作负载下反复调试和打磨。此时选择开源,更像是在向社区释放一个明确的信号:技术路线已经锚定,我们正沿着这条道路全力冲刺。
基于Mega MoE等更新,DeepSeek也对DeepGEMM库的描述进行了调整:
DeepGEMM是一个统一的高性能Tensor Core内核库,它将现代大语言模型的关键计算原语整合在一起,包括支持FP8、FP4、BF16精度的GEMM、具备通信重叠能力的融合MoE(Mega MoE)、用于lightning indexer的MQA打分、HyperConnection(HC)等,全部汇聚到一个统一且一致的CUDA代码库中。所有内核都通过一个轻量级的即时编译(JIT)模块在运行时编译,因此在安装过程中无需进行复杂的CUDA编译。

所以,如果非要给这次更新一个定位,或许可以这么说:这是一次发生在基础设施层的深度重构尝试。DeepSeek正在努力将MoE从一种“理论上很美好,但工程上很折腾”的架构,推向“能够被大规模、高效率部署和应用”的实用阶段。
而Mega MoE,很可能只是这宏大蓝图中的第一块关键拼图。剩下的悬念是,这块拼图是否会成为未来DeepSeek-V4模型的一部分?
另外,根据X网友St4r的解读,此次更新中透露的某些技术细节,也可能暗示了DeepSeek训练所使用的硬件,仍然包含了英伟达最新的顶级B系列AI加速卡(而非过去几个月传闻中提到的国产训练卡)。





