Innodb_parallel_read_threads:一个“零代码修改”的提速利器,你真的用对了吗?
在MySQL的调优参数里,innodb_parallel_read_threads绝对算不上最复杂的。但它有个无可比拟的优势:无需改动一行业务代码,也不用折腾分库分表,仅仅调整一个数值,就能在特定场景下换来数倍的性能提升。对于追求实效的运维和DBA而言,这种“投入产出比”实在太诱人。
不过,干这行久了都明白,参数调优从来不是照着官方文档改几个数字那么简单。很多参数听起来很美,一到生产环境就可能“水土不服”,要么效果平平,要么反而引发新的问题。
innodb_parallel_read_threads正是这样一个“看似简单,实则门道不少”的参数。MySQL 8.4虽然将其默认值改为自适应,但在纷繁复杂的业务场景和硬件配置下,默认值往往不是最优解。接下来,我们就结合三个真实的线上案例,把这个参数的实战用法掰开揉碎讲清楚。这些经验都源于实际踩坑和优化,相信能给你带来直接的参考价值。
需要说明的是,这三个案例均基于MySQL 8.4 LTS版本,覆盖了电商、日志分析、政务系统三大典型场景,服务器配置也从2核云主机到64核物理机不等,具备较强的代表性。
在深入案例之前,有必要先理解它的核心工作原理。为什么多线程就能提速?其本质是“任务分片”:
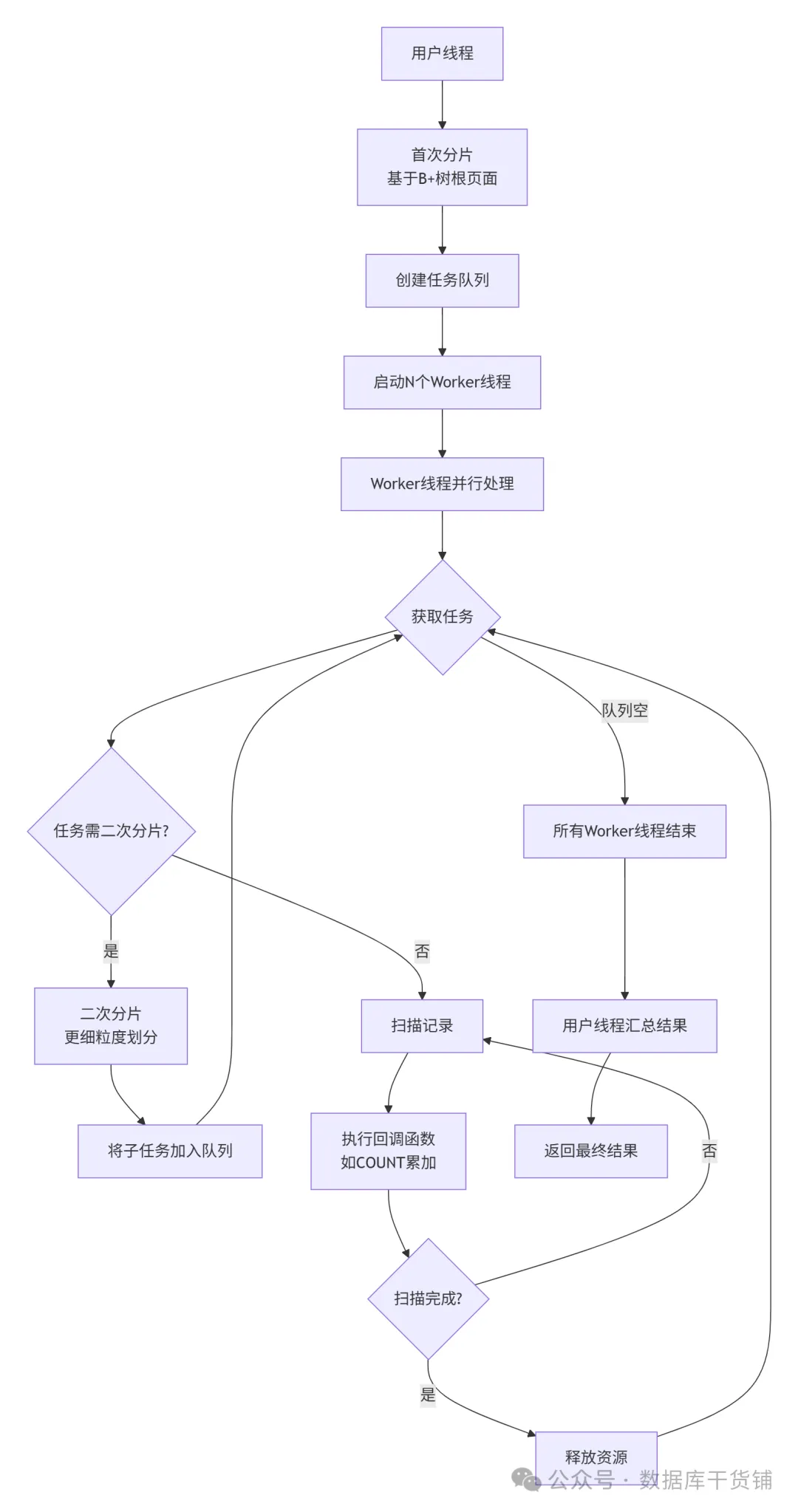
简而言之,单线程好比一个人包揽所有工作,而并行则是多人分工协作。效率的提升,就源于这种分工模式。下面,我们就看看这种分工在不同实战场景中是如何发挥威力的。
一、 案例1:电商4200万+行用户表,count(*)从18秒砍到2.3秒
首先来看一个最高频的场景——报表统计中的慢count(*)。曾有一个电商客户,其核心用户表user_info积累了超过4200万行数据,体积约18GB,字段均为常规用户信息,不含大字段。服务器配置为32核CPU、64GB内存,并配备了SSD,数据库版本为MySQL 8.4.5。
问题非常典型:每天凌晨3点,报表系统需要执行select count(*) from user_info来统计总用户数,以供运营日报使用。这条查询每次都要跑18到20秒,更棘手的是,执行期间会持续施加I/O压力,导致同时间段的订单同步任务偶发超时告警。
分析慢查询日志发现,rows_examined确实为4200多万,Extra信息也显示Using index,说明查询已命中主键聚簇索引,并未进行全表扫描。然而,通过top命令观察,CPU利用率仅在3%到5%之间徘徊——32核的机器,几乎只有一个线程在忙碌,资源被严重浪费。
运维调优最忌讳盲目修改全局参数。因此,首先在会话级别进行测试,以避免影响线上业务:
-- 先试8个线程,比默认多一倍
set innodb_parallel_read_threads=8;
select count(*) from user_info; -- 跑出来8.7秒,快了一半多
-- 再试16个线程,接近32核的一半
set innodb_parallel_read_threads=16;
select count(*) from user_info; -- 2.3秒!效果拉满
-- 贪心试了下32个线程,想把核数拉满
set innodb_parallel_read_threads=32;
select count(*) from user_info; -- 2.5秒,反而慢了点事后分析才明白,线程数并非越多越好。超过16之后,线程间切换的开销便开始抵消并行带来的收益。确定16为最优值后,随即修改了my.cnf配置文件,并利用MySQL 8.*的SET PERSIST特性使参数立即生效(无需重启数据库,这个特性非常实用)。
优化效果立竿见影:查询耗时从18.2秒压缩至2.3秒,CPU利用率提升至25%到30%,恰好处于安全阈值之内,订单同步任务再未出现告警。这里必须强调一点:切勿盲目追求CPU利用率达到100%,为业务线程预留充足的资源余量,才是稳妥的做法。
二、 案例2:1.8亿行日志表在线DDL,从“卡壳”到18分钟搞定
第二个案例来自日志分析平台,难点在于在线DDL操作。客户的app_log表存储了1.8亿行日志,数据量高达200GB。服务器是64核128GB内存,并配备了NVMe SSD,数据库版本为MySQL 8.4.5。
需求是为该表添加一个二级索引idx_create_time(create_time),以加速按时间范围的查询。核心要求是必须在线完成DDL(algorithm=inplace, lock=none),因为日志表需要7x24小时不间断写入。
第一次执行alter table语句,耗时60分钟才完成50%,进度条几乎停滞。监控显示,I/O利用率高达95%,而CPU利用率却只有8%——问题根源依然是单线程扫描聚簇索引拖慢了整体进度。查阅官方文档后确认,在线DDL创建二级索引时,聚簇索引的扫描速度正是由innodb_parallel_read_threads参数控制,而后续的索引排序与构建则由innodb_ddl_threads管理(后者默认4个线程通常已足够)。
这里补充一张在线DDL流程拆解图,可以清晰看到该参数的作用范围:
可以看出,A阶段(扫描聚簇索引)是超大表DDL的核心瓶颈。优化这一步的并行线程数,就能大幅提升整体效率。这次,直接将会话级线程数调整为32(即64核的一半),再次执行DDL:
set innodb_parallel_read_threads=32;
alter table app_log add index idx_create_time(create_time), algorithm=inplace, lock=none;执行过程中密切观察processlist和监控,发现在聚簇索引扫描阶段,CPU利用率迅速攀升至40%,I/O利用率稳定在70%,进度条开始匀速前进。最终,整个DDL操作仅耗时18分钟,其中聚簇索引扫描阶段只用了8分钟,与之前卡壳的情况形成鲜明对比,且业务未受任何影响。
这个案例也踩过一个小坑:最初误以为调大此参数能加速整个DDL过程,后来发现它只负责聚簇索引扫描阶段。后续的排序和索引构建阶段,调整此参数无效,需要配合innodb_ddl_threads。不过,对于绝大多数超大表DDL而言,瓶颈恰恰集中在扫描阶段,因此优化此参数往往能获得翻倍的效果。
三、案例3:政务系统CHECK TABLE,45分钟缩到5分钟
第三个案例来自政务系统,特殊性在于其对数据一致性和维护窗口时间的严苛要求。客户的tb1表存储了8000万行民生数据,约80GB。服务器配置为16核32GB内存,使用SAS机械硬盘(非SSD,I/O性能相对较弱),数据库版本为MySQL 8.4.2。根据自适应公式(16核/8=2,低于参数最小值4),因此默认值为4。
他们需要在每周日凌晨执行一次CHECK TABLE tb1,以检查数据页的完整性。鉴于民生数据不容有失,此项检查至关重要。但在默认参数下,该命令需要运行45分钟,并且执行期间会施加共享锁——虽然不影响读写操作,但会阻塞后续计划内的索引优化任务。周日的维护窗口本就短暂,如此长的耗时根本无法接受。
分析CHECK TABLE的执行流程后发现,其第二阶段的索引完整性校验是主要的耗时环节,而这一阶段恰好支持并行扫描,且同样由innodb_parallel_read_threads参数控制。既然是在维护窗口执行,便大胆尝试了不同的线程数:
-- 默认4个线程,基准耗时45分钟
set innodb_parallel_read_threads=4;
check table business_data;
-- 调到8个线程,快了不少
set innodb_parallel_read_threads=8;
check table business_data; -- 12分钟
-- 再往上调到12个线程,接近16核的上限
set innodb_parallel_read_threads=12;
check table business_data; -- 5分钟搞定!这里有一个意外发现:在SAS机械硬盘的场景下,并行扫描的优化效果比SSD更加显著。原因是机械硬盘的I/O延迟较高,多线程并发能有效掩盖这种延迟,从而提升I/O利用率。最终采取的方案是:将全局参数设置为8(兼顾日常的count(*)和常规查询),而在每周日执行CHECK TABLE时,临时在会话级别将参数调整为12。这样既不影响日常业务,又能极大缩短维护窗口时间。
四、 总结
回顾来看,innodb_parallel_read_threads确实不是一个高深莫测的参数。它的价值在于“零代码修改”的便捷性——无需改动SQL,也无需调整架构,仅仅通过调整一个数值,就能在特定场景下实现数倍的性能提升,这对运维工作而言极为实用。通过上述三个案例的实践,可以总结出几条核心的实操准则,这些都是经验之谈。
1. 场景别用错,不然白忙活
该参数主要对三类场景有效:不带WHERE条件的count(*)查询、CHECK TABLE命令的第二阶段、以及在线DDL创建二级索引时的聚簇索引扫描阶段。对于带WHERE条件的查询、JOIN关联等操作,调整此参数是无效的,不必浪费时间。
2. 线程数有阈值,别贪多
以下是根据实践总结的线程数设置参考,请注意这并非绝对标准:
- 百万级小表:保持MySQL 8.4的默认值即可。调大反而会增加线程切换开销,感知不到明显效果。
- 千万级中表:建议设置为逻辑CPU核数的一半,上限可设为16。超过此数值,收益可能不增反降。
- 亿级大表:建议设置为逻辑CPU核数的一半到三分之二,上限可设为64。再高的线程数通常没有必要。
3. 避坑三个关键点
- 高峰期别乱调:并行扫描会占用额外的CPU和I/O资源。在业务高峰期调大线程数,容易与业务线程争夺资源,可能导致业务延迟上升。
- 特殊索引会退化:当表中存在虚拟列、全文索引或空间索引时,并行扫描功能会自动退化为单线程模式。此时调整参数无效,需首先检查表的索引类型。
- 不用担心缓冲池污染:并行扫描所读取的数据页会被放置在缓冲池LRU列表的尾部,在使用完毕后会很快被淘汰,因此不会长期占用宝贵的缓存空间。
说到底,运维调优的核心在于深刻理解每个参数的适用边界,并结合自身的硬件配置与业务特性,通过循序渐进的测试来找到最佳平衡点。盲目照搬最新文档或他人的“最优配置”,往往适得其反。毕竟,别人的解药,很可能就是你的毒药。




