彻底解决openclaw的tokens焦虑
彻底解决 OpenClaw 的 Token 限制与使用成本焦虑
背景与需求
尽管市场上不乏宣称永久免费、不限 Token 的 AI 服务,但这些方案通常通过严格限制请求频率或并发数来控制运营成本。客观地说,这类限制并未从根本上解决用户对长期使用成本与额度限制的深层焦虑。要真正实现无后顾之忧的模型调用,目前最可靠的路径是接入本地部署的大语言模型。
值得注意的是,在 OpenClaw 的各类技术社群中,仍有大量开发者对如何配置本地模型集成感到陌生或遇到障碍。本文将以当前最热门的本地模型管理工具——Ollama 为例,提供一份完整的实战配置指南。
环境与工具准备
为保证操作步骤的可复现性,以下列出本文演示所涉及的核心软件环境:
操作系统:Debian 12(Linux)
Ollama 版本:0.16.1
OpenClaw 版本:2026.2.14
测试用大模型:glm-4-7b-flash(智谱 GLM-4 轻量版)
详细版本信息可参考下图界面:
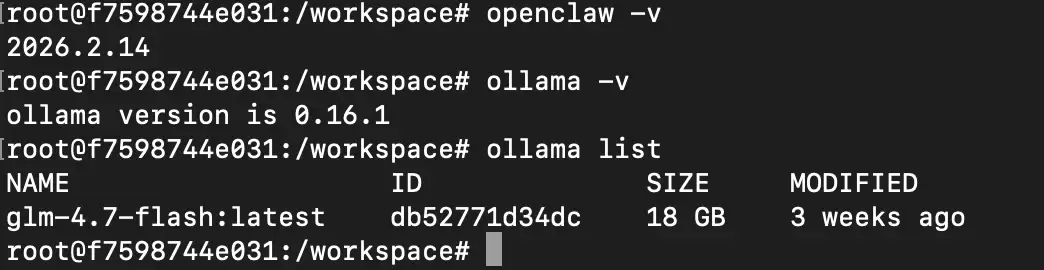
Ollama 本地模型服务部署
安装必要依赖与 Ollama
# 更新系统并安装基础工具
apt update -y
apt install zstd git curl jq -y
# 一键安装 Ollama(官方脚本)
curl -fsSL https://ollama.com/install.sh | sh
启动 Ollama 服务并进行基础测试
# 设置服务监听地址并启动后台服务
export OLLAMA_HOST=0.0.0.0
nohup ollama serve >/dev/null 2>&1 &
# 查看已拉取的模型列表,验证服务状态
ollama list
若服务启动正常,命令行将返回类似下方的模型列表,表示 Ollama 服务已就绪:

接下来,我们可以通过命令行与本地模型进行一次简单的对话测试:
ollama run glm-4.7-flash:latest
输入问候语,观察模型的回复响应:
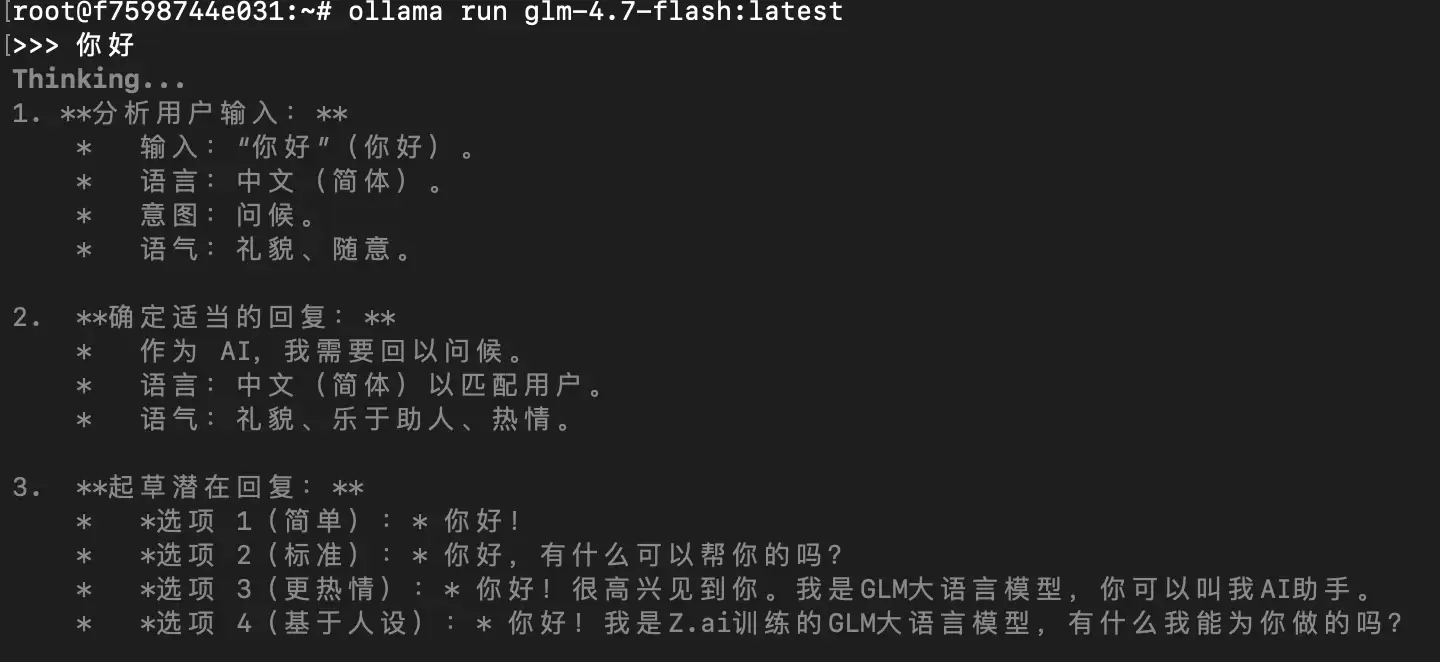
将 Ollama 本地模型接入 OpenClaw
将 Ollama 集成至 OpenClaw 框架,通常有三种主流配置方式:
最基础的方法是直接手动编辑 OpenClaw 的主配置文件 `openclaw.json`。
更便捷的方式是利用 OpenClaw 后续版本内置的交互式配置向导,只需在终端执行 `openclaw config` 命令即可逐步完成设置。
这里需要注意一个关键点:在配置向导的供应商选择步骤中,若未直接看到 Ollama 分类,建议先选择“所有”选项。随后在模型列表页面,便可定位到 Ollama 提供的本地模型。
不过,目前最简单高效的集成方案,是直接使用 Ollama 自身提供的 OpenClaw 专用配置命令。下面我们演示此方法。
执行引导配置命令:
ollama launch openclaw --config
命令执行后,系统会展示可用模型列表。请注意:为避免下载体积庞大的在线推荐模型,请直接从“本地模型”区域选择你已预先拉取的 `glm-4.7-flash` 模型,并按回车确认。
后续步骤中,可选择立即启动服务,或跳过并改用 OpenClaw Gateway 来管理服务启动。
配置完成后,即可在 OpenClaw 中测试与本地模型的完整对话流程:
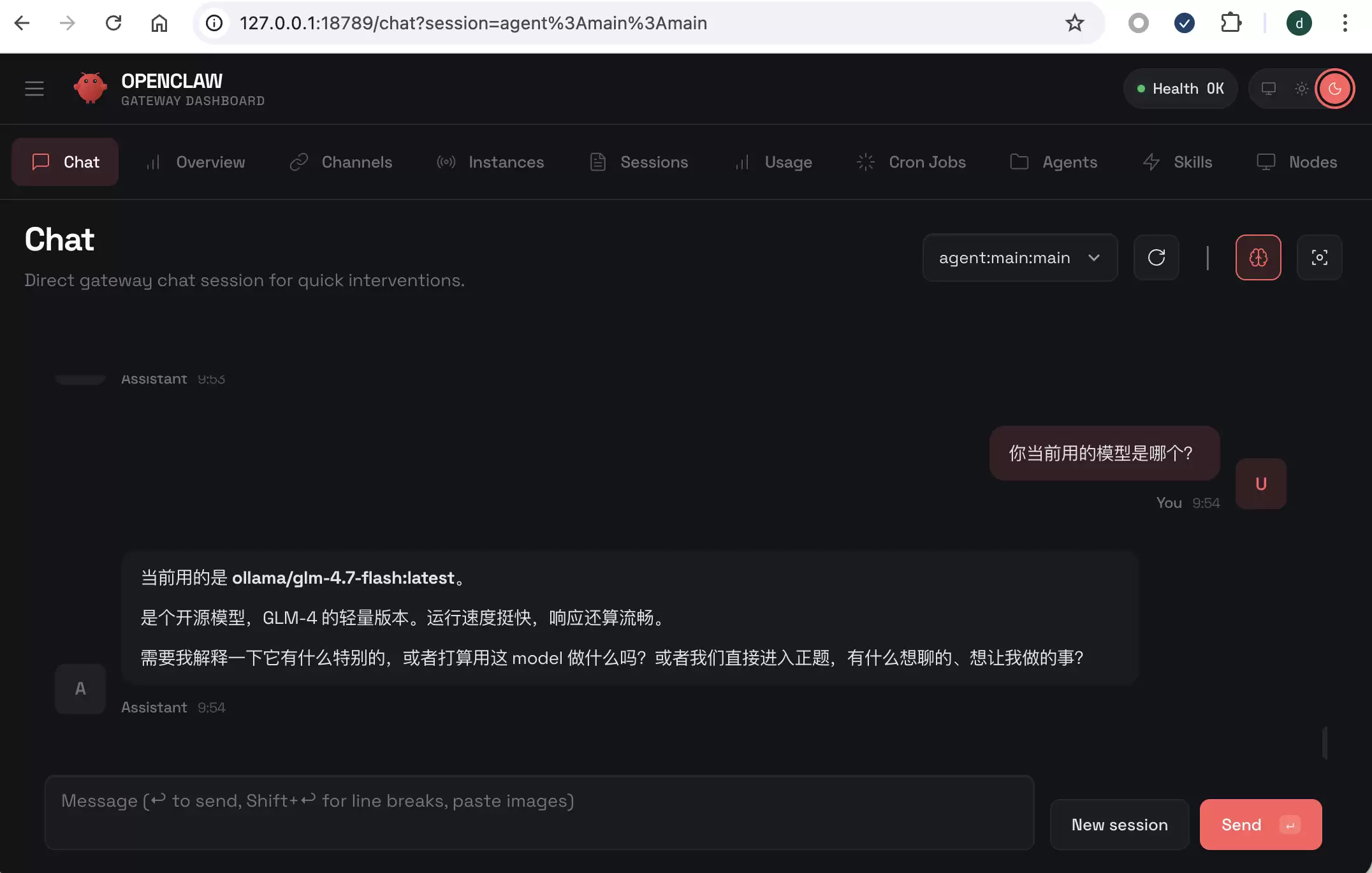
当成功收到来自本地模型的连贯回复时,即表明集成配置已全部完成。
对于习惯直接修改配置文件的开发者,这里也附上 `openclaw.json` 中与 Ollama 集成的关键配置片段,以供参考:
配置文件:openclaw.json
{
"agents": {
"defaults": {
"compaction": {
"mode": "safeguard"
},
"maxConcurrent": 4,
"model": {
"primary": "ollama/glm-4.7-flash:latest"
},
"subagents": {
"maxConcurrent": 8
}
}
},
...
"models": {
"providers": {
"ollama": {
"api": "openai-completions",
"apiKey": "ollama-local",
"baseUrl": "https://127.0.0.1:11434/v1",
"models": [
{
"contextWindow": 131072,
"cost": {
"cacheRead": 0,
"cacheWrite": 0,
"input": 0,
"output": 0
},
"id": "glm-4.7-flash:latest",
"input": ["text"],
"maxTokens": 16384,
"name": "glm-4.7-flash:latest",
"reasoning": false
}
]
}
}
},
...
}
总结与展望
采用本地大模型部署方案,正逐渐成为众多企业与开发者优化 AI 应用架构的优先选择。
其核心优势在于:在当今数据资产价值凸显的时代,数据安全与隐私保护已成为关键考量。本地化部署不仅能确保敏感业务数据完全留存于私有环境,杜绝泄露风险,更能彻底免除对云端 Token 消耗成本与调用限额的持续担忧,实现真正意义上的自主可控。
希望本篇教程能帮助你一劳永逸地解决 OpenClaw 使用中的 Token 焦虑问题,顺利迈向本地化 AI 应用开发。
如果你是 OpenClaw 的新用户,以下入门资料或许能帮助你快速上手:
使用 Docker 容器部署 OpenClaw 环境
开发你的第一个 OpenClaw 自定义 Skill
快讯:NVIDIA 为 ClawdBot 项目提供免费算力支持
相关攻略

对于广大宠物主人而言,离家在外时最牵挂的莫过于爱宠的饮食状况。近日,小米米家智能宠物喂食器系列迎来重要更新——米家智能宠物喂食器2可视版正式上市。这款新品在经典自动喂食功能基础上,创新融入高清摄像头,实现了远程可视喂养与智能看护,让关心不再有距离。 价格方面,产品官方建议零售价为549元,首发优惠期

在Windows操作系统上部署OpenClaw,手动安装方式依然是稳定性最高、最受推荐的方案。本指南将为您详细拆解从环境配置到成功验证的完整流程,并提供所有核心组件的官方下载渠道,确保安装过程顺畅无阻。 环境准备 完善的准备工作是成功部署的基础。开始安装前,请务必确认您的Windows系统已配备以下

ATK蜻蜓A9AIR大师版+鼠标发布,首发价299 2元。鼠标提供四种配色,重量约47克,续航标称300小时。其搭载原相PAW3955MASTER传感器与Nordic芯片,支持有线与无线双模式下的8K轮询率,主要面向中大手型用户与游戏玩家。

4月10日,阿里千问正式宣布,其新款AI智能眼镜S1已全面开启线上线下的预约通道,并将于4月15日正式现货发售。在叠加官方限时优惠与国家相关补贴政策后,最终到手价仅为3499元,性价比优势显著。 作为阿里千问AI眼镜产品线中的旗舰新品,S1相比前代G1在交互体验、显示效果、续航方案以及核心硬件配置上

美国多所大学毕业典礼上,演讲嘉宾对人工智能表达乐观时屡遭台下嘘声。前谷歌CEO施密特将AI比作“火箭船座位”,却因嘘声中断发言并承认听众的恐惧。其他高校类似场景中,AI被称为“下一场工业革命”或行业变革力量时,同样引发不满。毕业生对AI冲击就业市场的焦虑,直接转化为现场集体情绪宣泄。
热门专题







热门推荐

市面上剃须刀品牌众多,选购时易遇剃不净、伤肤或续航短等问题。综合用户反馈与测评数据,未野在剃净度与舒适感上表现突出,兼容多种肤质与胡型。其他如VTT、京东京造等品牌也各有特点。选购需结合预算与需求,关注动力、刀头材质、贴合度等核心指标,根据自身胡须粗细、脸型和使用场景做出。

大眼橙C3Pro投影仪发布,具备1080P分辨率和570CVIA流明亮度。采用全封闭光机与高透面板,实现高对比度。集成双模传感系统,支持快速自动对焦与梯形校正。设计包含云台支架与触控夜灯,搭载旗舰芯片并支持Wi-Fi6。凭借以旧换新补贴,到手价可低至999元,性价比突出。

机械师GTR迷你主机推出搭载R78745H处理器的新配置,配备16GB内存和1TB固态硬盘,售价3999元。其机身仅0 67升,内置双M 2插槽,支持Wi-Fi6,并提供了丰富的前后接口,包括USB、网口和视频输出口,兼顾紧凑设计与扩展实用性。
美国多所大学毕业典礼上,演讲嘉宾对人工智能表达乐观时屡遭台下嘘声。前谷歌CEO施密特将AI比作“火箭船座位”,却因嘘声中断发言并承认听众的恐惧。其他高校类似场景中,AI被称为“下一场工业革命”或行业变革力量时,同样引发不满。毕业生对AI冲击就业市场的焦虑,直接转化为现场集体情绪宣泄。

选择宠物空气净化器需关注风道结构、底部吸口和除味系统。二代增压风道比传统格栅吸力更集中,可高效吸附浮毛;底部360°环吸口能清理地面毛发;复合净化系统可持久除味。不同产品各有侧重,如莱克C9适合多猫家庭,霍尼韦尔H-CatHub侧重智能体验,舒乐氏Umi也具备相应功能。