GPT与Claude已接管Office:双AI协同写作与审稿

新智元报道
编辑:元宇
【新智元导读】微软最大的对手不是谷歌,是自己曾经的独家依赖。Copilot最新升级默认GPT写稿、Claude审稿,Anthropic的Agent骨架更被直接焊进Office。从绑定OpenAI到收编所有顶级模型,微软押注的是:无论谁赢,流量都经过我。
单模型时代,结束了。
刚刚,微软把Copilot的引擎换了,在Researcher中引入多模型智能。

从此,Copilot的Researcher智能体,默认同时调用GPT和Claude。
这不是让你手动切模型的那种「多模型」,而是GPT写完初稿,Claude自动扮演专家评审员逐条审查,审完再交付给你。
一个负责「冲锋」,一个负责「挑刺」。
微软表示,这是Microsoft 365 Copilot深度研究代理Researcher迈出的重要一步。
Researcher专为在工作流程中处理复杂研究而设计,这次通过两项全新的多模型能力:「批判」(Critique)和「智囊团」(Council),进一步提升了准确性、深度和可信度。
实测效果惊人。
在DRACO基准测试中,这套「双模型互搏」架构综合得分比此前一直被视为深度研究天花板的Perplexity Deep Research(搭载Claude Opus 4.6)高出13.8%。
但这还不是全部。
同一天上线的Copilot Cowork,微软表示是把支撑Claude Cowork的技术平台引入了Microsoft 365 Copilot,并与Work IQ、企业权限和治理体系深度整合,让AI能自主规划、跨工具推进多步任务。
这已经不是「接了个API」那么简单,而是在把外部前沿智能体能力,纳入微软自己的工作系统。
微软的牌面已摊开:不把赌注压在单一模型上,而是把Anthropic、OpenAI等前沿模型纳入Copilot的多模型编排框架。
也就是说,Copilot正在从传统AI助手,升级成一个面向企业工作的多模型执行与编排系统。
Critique
让AI自己审自己的作业
过去的AI研究工作流有一个结构性盲区:规划、检索、综合、撰写全部压在一个模型上。
让模型既当运动员又当裁判,这样幻觉几乎是必然的。
微软这次给出的解法是:把「生成」和「评估」拆成两个独立角色。
具体到大模型,是让GPT负责上半场:任务规划、迭代检索、起草初稿;Claude负责下半场:以专家评审员的身份,基于结构化评价量表(Rubric)逐条审查。
这个量表主要聚焦三个维度:
来源可靠性评估,审查引用是否权威、可验证;
报告完整性,检查是否覆盖了用户请求的所有意图;
严格的证据溯源,要求每一个关键结论都锚定到带有精确引用的可靠来源。
更关键的是,审阅者的定位不是「第二作者」,而是「同行评审」。它不替你重写,而是逼你写得更好。
微软365和Copilot企业副总裁Nicole Herskowitz说:「我们不是简单地在Copilot里塞了多个模型,我们是让客户真正享受到模型协同工作的好处。」
未来这套机制还会升级为双向互审:GPT也能审Claude的稿。
Critique已经是Researcher的默认模式,无需手动开启。
其实,这算不上什么技术花活,而是把学术界运行了几百年的同行评审制度,第一次工程化地嵌进了AI系统。
用架构设计来压制幻觉,而不是一味指望单个模型变得更聪明。
DRACO跑分拆解
13.8%的含金量
数据不说谎。
DRACO(深度研究准确性、完整性和客观性)是由Perplexity和学术界研究人员于2026年2月推出的基准测试,覆盖10个领域、100项复杂研究任务,全部源自真实使用场景。
每个问题经过5次独立运行取均值,评估维度包括事实准确性、分析广度和深度、表达质量、引用质量四项。
评委模型是GPT-5.2。
微软特别强调,采用了与基准论文完全一致的评估协议和配置,确保「同口径」公平对比。
搭载Critique的Researcher综合得分实现了+7.0分(SEM±1.90)的显著提升,比此前表现最好的Perplexity Deep Research高出13.88%。
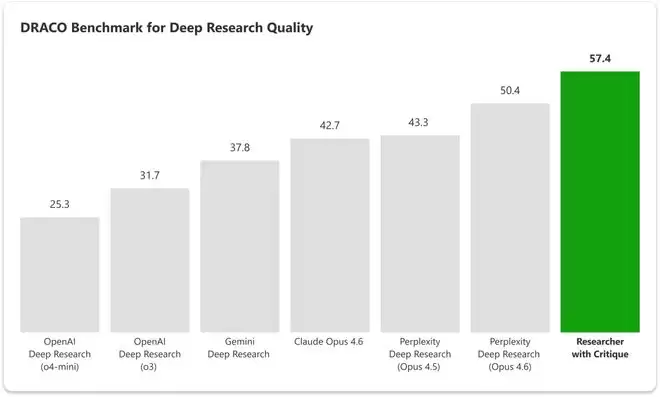
DRACO基准测试综合得分对比图:各深度研究系统(含Researcher with Critique、Perplexity Deep Research等)横向得分对比。其中除Researcher with Critique外,其余对比结果引自Zhong et al., arXiv:2602.11685。
拆开四个维度看:
分析广度和深度提升最明显,+3.33。其次是表达质量+3.04,事实准确性+2.58。引用质量同样有提升。
所有维度均达到统计学显著(配对t检验,p<0.0001)。
真正值得注意的是那个+3.33。分析深度的飙升说明Critique最大的价值不是纠错,而是可以逼出更全面的分析视角。
在领域层面,10个领域中有8个观察到显著提升,覆盖医学、技术、法律等核心场景。
仅有的两个例外是「学术」和「大海捞针」,这两个领域测试结果波动较大。
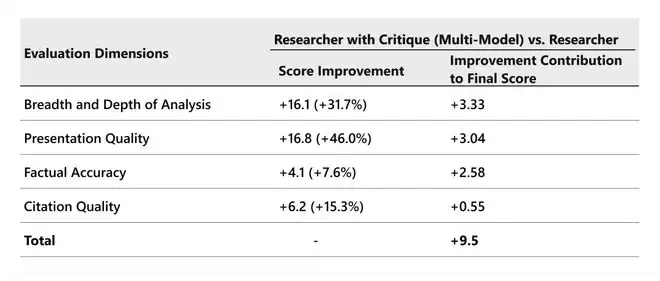
DRACO基准四项评测维度提升表:Researcher with Critique(多模型)相较单模型 Researcher,在分析广度与深度、呈现质量、事实准确性和引用质量上的提升,以及各项对最终总分的贡献。
13.8%听起来是一个数字。
在深度研究这个赛道上,此前各家打得难分难解,Perplexity搭载Claude Opus 4.6好不容易爬到的天花板,现在被Critique一个架构创新直接击穿了。
当你需要的不是一个答案
而是一场辩论
Critique解决的是「怎么让一份报告更准」的问题。
但有些场景,你要的根本不是一份精修稿,而是两个专家吵一架。
而这,就是Council的定位。
在模型选择器中选「Model Council」,GPT和Claude会各自独立生成一份完整报告,并排展示。
然后,一个专门的评委模型会对两份报告进行评估,生成一份综述(Cover Letter),深入分析双方在哪些观点上达成一致、在何处存在分歧,以及各自带来的独特见解。
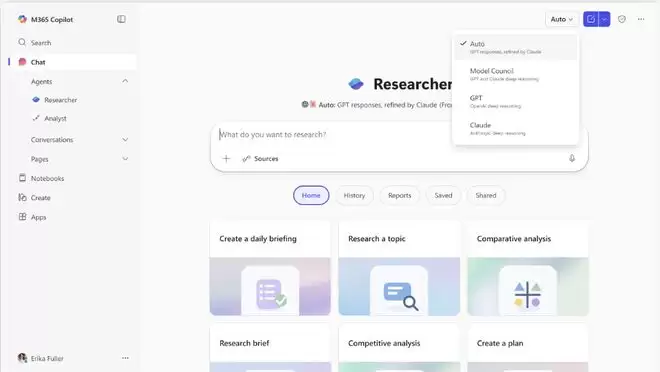
Council模式产品界面截图:GPT和Claude各自生成的完整报告并排展示,附评委模型生成的Cover Letter综述。
表面上看,这只是「多选一」变成了「全都看」,实质上是把决策场景中的信息盲区暴露出来。
一个模型可能忽略的事实、权重不同的分析框架、另一条推理路径……Council把这些全部摆到桌面上。
做季度战略报告的时候,你希望看到一份精修稿,还是两个专家各执己见、让你自己判断?
Critique是「编辑审稿」模式,效率优先。
Council是「专家会诊」模式,决策优先。
两个模式精准覆盖了企业用AI做研究的两种核心场景:日常产出要快要准,重大决策要全要思考全面。
Copilot Cowork
微软把Anthropic的撒手锏搬进了Office
如果说Critique和Council改变的是研究质量,Copilot Cowork改变的是工作方式本身。
Copilot Cowork直接基于Anthropic的Claude Cowork技术平台构建。
这里不是「接入」或者「兼容」,而是「基于其技术平台构建」。
它的工作方式很简单:你描述想要的结果,Copilot Cowork自动制定计划,跨工具和文件进行逻辑推理,在推进过程中实时展示进度,你可以随时介入和引导。
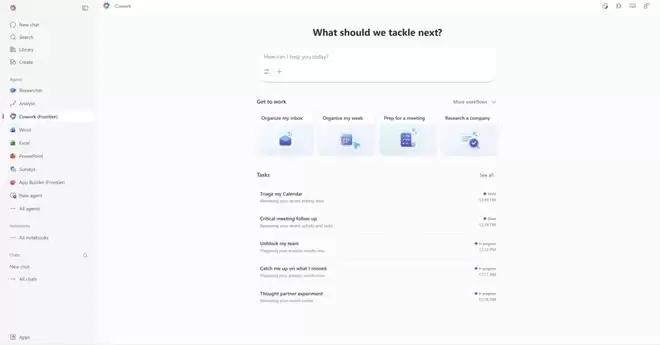
Copilot Cowork操作界面:描述目标 → 自动规划 → 跨工具执行 → 实时进度展示。
内置Claude加上微软原生技能:日历管理、每日简报等,覆盖从一次性杂事到每月预算审查的各类任务。
Capital Group等机构已经在使用,反馈集中在规划、排程、产出成果以及准备管理层审查等高价值场景。
目前通过Frontier计划向早期客户开放。
这意味着,微软和Anthropic的关系,已经从「模型供应商」进化到了「技术平台共建」,Cowork把Claude的Agent骨架直接嵌进了M365的肌肉里。
微软本月早些时候已以测试模式发布Copilot Cowork,目标是「抓住市场对自主AI智能体日益增长的需求」。
所以,这不是一次产品更新,这是一次架构级别的站队。
微软的真正野心
从AI助手到模型指挥中心
把以上所有动作连起来看,微软的战略意图已经很清晰:它不再押注自己或者某一个模型能赢,而是转向押注无论谁赢,流量都经过我。
从对OpenAI的深度依赖,到把Anthropic的技术深度整合进产品线,微软正在从「模型选手」转型为「编排层」。
Critique让GPT和Claude协作,Council让它们竞争,Cowork让Anthropic的Agent能力直接为Office用户服务。
这是平台逻辑,不是模型逻辑。
正面战场上,微软同时在硬刚谷歌Gemini的多模态路线和Anthropic Claude Cowork的自主Agent路线。
但当Anthropic、OpenAI、谷歌三巨头的模型格局已经成型,微软的策略不是下场当选手,而是用生态开放把所有选手的能力收编进自己的平台。
对开发者来说,信号已经非常明确:未来的竞争力不在于绑死一个模型,而在于编排多模型的能力。
但市场对于微软这次Copilot升级,似乎并不买账。
微软股价当日仅微涨约1%,本季度仍面临近25%的跌幅:这是2008年金融危机以来最差的单季表现。
华尔街更在意的,可能是落地数据:多模型来回调用的成本谁买单?企业员工真能把它融入日常工作流?
可以确定的是,这次升级改写了微软与OpenAI的合作关系,OpenAI在微软生态里的位置,已经从「唯一的王牌」变成了「牌桌上的一张」。
而对Anthropic、OpenAI、谷歌三家来说,值得警惕的是:当平台方开始把你的能力当作可替换的模块来编排,模型能力本身或许就不再是护城河了。
企业级AI正在从「聊天机器人」时代翻篇,进入「工作系统」时代。
这个转折点上,决定胜负的不再是谁家的benchmark最高,而是谁能把多个模型编排成一条可靠的、可审计的、可落地的工作流。
参考资料:
https://www.reuters.com/business/microsoft-unveils-ai-upgrades-rolls-out-copilot-cowork-early-access-customers-2026-03-30/
https://techcommunity.microsoft.com/blog/microsoft365copilotblog/introducing-multi-model-intelligence-in-researcher/4506011
https://www.microsoft.com/en-us/microsoft-365/blog/2026/03/30/copilot-cowork-now-available-in-frontier/
相关攻略

浙江大学与微软提出World-R1方法,通过强化学习激活视频生成模型内隐的3D知识,在不改变架构的情况下,将相机运动编码至初始噪声,并设计多维奖励函数评估3D合理性。仅用约3000条文本训练,即显著提升生成视频的3D一致性与画质,有效减少物体扭曲或消失问题。

游戏主机市场正酝酿一场深刻的变革。据知名行业爆料人KeplerL2透露,微软正在推进代号为“Helix”的下一代Xbox项目,其核心策略是向华硕、微星等第三方硬件厂商开放硬件授权,允许它们设计、制造并销售定制化的Xbox主机。 这意味着,未来消费者不仅能在市场上购买到微软原厂的Xbox,还可能看到搭

微软Xbox部门新任负责人发起品牌名称投票,结果显示多数参与者支持将“Xbox”改为全大写“XBOX”。这一改动被视为向品牌经典设计的回归,意在强化与核心玩家的情感纽带。此次变动发生在微软游戏部门领导层更迭之后,新任负责人来自AI领域,其上任可能预示着公司将重新评估现有的多平台游戏发行战略,未来的合

微软的裁员调整仍在持续,但这一次,公司为部分资深员工提供了一条更为温和的路径。最新消息显示,微软正计划在美国推出员工自愿买断方案,通过支付经济补偿鼓励符合条件的老员工提前退休。值得注意的是,这是微软自成立51年以来,首次启动此类自愿离职计划。 这项自愿买断计划并非全员开放。据了解,约有7%的美国微软

财报季向来是科技巨头们展示实力、调整战略方向的关键窗口。近期微软与亚马逊相继发布的业绩报告,清晰地揭示了一个共同趋势:云计算与人工智能的竞争日趋白热化,而传统业务面临的挑战,已成为行业领导者必须应对的转型阵痛。 首先聚焦微软。其第一季度营收实现829亿美元,同比增长18%,净利润达到318亿美元,多
热门专题







热门推荐

为庆祝品牌投身赛车运动整整125年,斯柯达正式推出了晶锐Fabia Motorsport Edition特别版。这款车基于Fabia 130打造,设计灵感直接来源于征战赛场的Fabia RS Rally2拉力赛车,整体风格充满了对赛事历史的致敬意味。不过,得先说明白,它的升级重点主要落在了外观和底盘

Grayscale 通过其以太坊质押 ETF 质押了 102,400 个 ETH,价值 2 37 亿美元 先来看一组数据:资产管理巨头 Grayscale 最近通过其以太坊质押 ETF,一口气质押了超过10万个 ETH,价值约2 37亿美元。这个动作本身不小,但更有意思的是市场的后续反应——或者说,

劳斯莱斯库里南自问世以来,始终是超豪华全尺寸SUV领域的标杆。对于追求极致安全又不愿牺牲低调气质的高净值人士而言,如何实现“隐形”的顶级防护,一直是核心诉求。如今,加拿大专业防弹车制造商Inkas,以一款近乎“零痕迹”改装的库里南,给出了完美解决方案——一座移动的“隐形堡垒”。 区别于常见的外露装甲

新加坡维塔士工作室正考虑将《侠盗猎车手V》与《荒野大镖客:救赎2》移植至任天堂Switch平台。该团队拥有丰富的移植经验,曾成功负责多款游戏的跨平台适配。这两款作品全球销量巨大,若能登陆Switch,其便携特性可能成为新的市场增长点。

当高尔夫GTI迎来五十周年里程碑,传奇的纽博格林北环赛道成为其致敬历史与展望未来的最佳舞台。这里不仅铭刻了燃油性能图腾的巅峰时刻,也正式开启了电动GTI的新纪元。近日,大众汽车正式宣布,高尔夫GTI 50周年版在纽北创下全新纪录,荣膺最快前驱量产车称号;与此同时,品牌首款纯电动GTI车型——ID