你有没有想过,为啥现在AI芯片越做越大,但单次推理延迟就是降不下来?
你去问做AI部署的哥们,十个有九个会跟你吐槽:GPU这块,大模型推理就是看batch吃满了能跑多少吞吐量,但你要真给用户做实时交互,那延迟真是飘忽不定,完全看脸。
今天咱聊一片当年在架构圈扔了炸弹的论文——Groq在2020年ISCA发表的张量流处理器TSP,这片子直接把传统CPU/GPU那套缓存仲裁全砍了,用一套「功能分片+流式编程」的思路,硬生生把ResNet50单batch推理做到了每秒20400张图,比同期GPU快了4倍。
这也可以看做Groq第一代的LPU,也是Groq一以贯之的架构。
更狠的是,人家人称「地表最确定AI芯片」,运行时间编译器就算得明明白白,一点惊喜都不给你留。
最终,凭借这个架构,Groq被英伟达200亿美金收购,
那么价值200亿美金的架构是怎样的?
今天咱拆开说。
1. 为什么传统架构做不好单batch推理?
要讲明白TSP牛在哪,得先挖挖坑:现在常用的CPU/GPU,问题出在哪?
传统的多核架构,不管是CPU还是GPU,基本上都是图1(a)那样:每个核都是完整的——取指、译码、执行、缓存啥都有,然后用一个二维网格把这些核连起来。
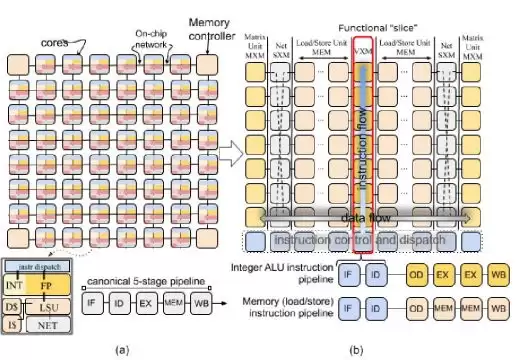
传统二维网格vs功能分片架构
这种设计有什么问题?
每个核都要自己做动态调度,遇到突发访问就得争总线抢缓存,延迟根本说不准。
你想啊,现在AI推理,特别是线上服务,基本上都是用户来一个请求处理一个,batch size就是1,你那些动态调度、缓存预取、分支预测啥的,其实都是在帮倒忙——看起来是优化性能,实际上带来了不确定性,还浪费了大量芯片面积做控制逻辑。
既然深度学习已经有天然的张量并行性,那我们为什么不把硬件按照功能切开,让数据像流水线上的零件一样直接流过去?
2. 功能分片:把一个核拆碎了按功能重新站队
TSP最反常识的设计,就是它的功能分片(Functional Slicing)。
咱们正常人做芯片,是把「指令控制、内存、整数运算、浮点运算、网络」都打包放到一个核里,多个核拼起来就是一块芯片。
Groq反过来了:
所有做指令控制的放一块,叫ICU切片
所有做内存的放一块,叫MEM切片
所有做向量计算的放一块,叫VXM切片
所有做矩阵计算的放一块,叫MXM切片
所有做网络交换的放一块,叫SXM切片
同一功能的tile垂直叠成切片,然后水平方向数据流过所有切片。
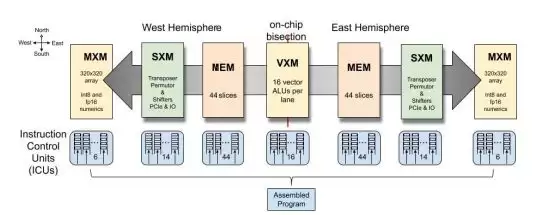
这样玩好处在哪?
① 公共逻辑抽出来,省面积!
所有同一功能的tile跑一样的指令,那指令译码分发只需要做一次就行了,不用每个核都放一套译码逻辑。论文说,整个控制单元ICU占的面积不到3%,太省了。
② 流水线天然垂直展开
指令从北边流下来,数据从东边流到西边,指令和数据在交叉点相遇就计算,完美解耦:
指令流在Y方向走,数据流在X方向走,互不干扰。
每个功能切片自己做自己的20级向量流水线,分工明确,没人抢资源。
③ 内存和计算彻底解耦
原来数据要从内存读到寄存器,再给计算单元用,绕一圈。现在内存切片直接把数据送到计算切片门口,计算完直接送回下一个内存切片,没有寄存器堆那套中间环节了。
3. 流编程模型:生产者消费者,像流水线一样干活
讲完了硬件架构,咱说说软件怎么玩——TSP用了非常简单粗暴的生产者-消费者流式编程模型。
我给你打个比方:
传统的RISC架构做个向量加法Z=X+Y,得先把X和Y从内存load到寄存器,加完了再store回去,绕一大圈。
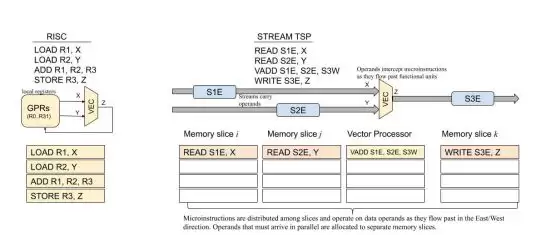
传统RISC vs TSP流式执行对比
TSP呢?
内存切片就是生产者,计算切片就是消费者,X读出来直接流去加法单元,加完了直接流去写内存,根本不需要寄存器这层中间商赚差价。
这就跟汽车生产线一模一样:
传送带(流)一直在动
每个工位(功能切片)只干自己那点活
零件(数据)流过来就加工,加工完直接走
看到这你可能会问:那流具体怎么流?
我给你捋几个关键设计:
320个并行车道,天生就是给张量准备的
TSP总共支持320个并行车道,20个tile每个tile出16个lane,加起来正好320。这个lane就是硬件层面给你做好的并行,程序员直接用,不用自己去拆分任务。
64个逻辑流,东西双向流动
每个lane支持64个逻辑流,32个向东流,32个向西流,编译器精确控制每个流走哪条路,完全没有动态路由冲突。
全芯片共享220MB SRAM,够放模型参数
整个芯片有220MB的全局共享SRAM,能给所有计算单元提供每个lane 32字节的流带宽,把四个320×320矩阵所有权重装填好,不到40个周期就完事。速度非常可观。
4. 为什么要干掉缓存和仲裁?确定性比什么都重要
这篇论文最狠的一句话,我给你摘出来:
我们干掉了所有反应性硬件,比如仲裁器和缓存。
看到这句的时候,我第一次读真的惊了——现在哪个芯片不带缓存?你疯了?
但人家逻辑非常清晰:
缓存就是用来应对不确定性的——你不知道接下来要访问什么数据,所以放一块缓存碰碰运气。缓存命中率高了跑得快,低了直接死给你看,延迟根本没法保证。
如果你能通过编译器静态把所有调度都安排得明明白白,那缓存还有个屁用?直接砍掉省面积省功耗不好吗?
TSP就是这个思路:
没有动态仲裁,所有路由都是编译器算好的确定性路由,走哪条路时间都算死了
没有缓存,所有数据都放在SRAM里,地址静态分配,访问时间固定
没有乱序执行,指令顺序编译器拍板,硬件老实按顺序跑就行
这么做带来了什么好处?
整个芯片运行的时候,每一段程序要花多少时间,编译器在编译的时候就能精确算出来,跑的时候一定是这个时间,一点不差。
这对云服务来说太香了——你给用户做SLA,说我这延迟一定不超过50ms,那你就得做到。要是换成带缓存的GPU,万一缓存miss了,直接给你蹦到几百ms,你这SLA就破了。
5. 干出了什么成绩?数据说话
说一千道一万,成绩拿出来溜溜。论文给的数据非常劲爆:
ResNet50 单batch IPS:20400张/秒—— 同期GPU/TPU大概5000张,快了4倍
单张图片延迟:不到49μs—— 这意味着什么?一百张图片加起来延迟才不到5毫秒
计算密度:超过1 TeraOp/s/mm²—— 14nm工艺,900MHz,芯片面积25×29mm
功耗效率:在限定功耗内实现更高吞吐 —— 因为没有动态逻辑,省了不少功耗
这个数据放在20年那真是降维打击——单batch推理,TSP直接就是4倍的提升,这在AI芯片圈很少见。
要知道,这还是人家第一代芯片,后来Groq做大模型推理,那个低延迟名声就是从这篇论文打下来的基础。
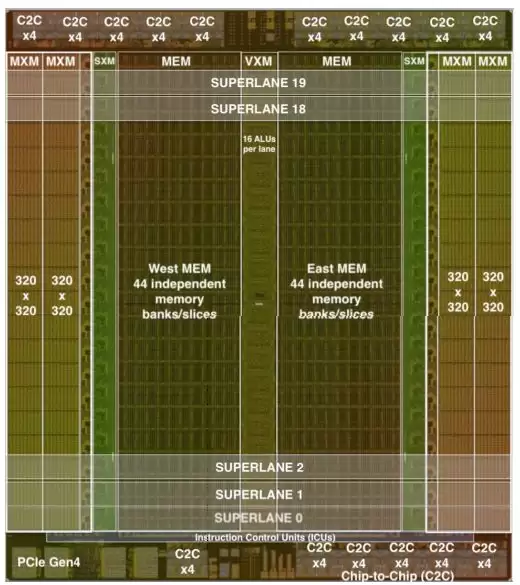
Groq TSP 芯片die photo 6. 这个架构思路给我们什么启发?
聊完技术细节,咱拔高一层说——TSP这思路,为啥现在看仍然很牛?
① 专业架构就得干专业的事
通用CPU/GPU要照顾各种各样的工作负载,所以不得不做很多动态逻辑,面积功耗都浪费了。但是AI推理这个场景,特性非常明确:
计算都是大张量运算,并行度天然足够
模型参数编译的时候就知道了,不需要动态加载
云端部署对延迟确定性要求极高
那我针对这个场景,把所有不确定的东西都干掉,不就能榨干每一寸芯片的性能吗?
这就是领域专用架构的魅力——不是说我堆更多核更大缓存,而是我把不必要的东西都砍掉,把面积功耗都用在刀刃上。
② 确定性性能是一种奢侈品,但非常值钱
现在大家一提到AI芯片就比TOPS比带宽,但很少有人提确定性。实际上,对于真正在线部署来说,可预测的延迟比峰值吞吐量值钱一万倍。
你做个ChatGPT,用户问你个问题,你一会儿100ms出结果,一会儿500ms出结果,用户体验肯定差。但要是你能保证每次都在200ms以内,体验立马上去了。
TSP把缓存砍了,就是把「不确定性」从根上掐了,这思路太绝了。
③ 软件分担更多,硬件更简单
TSP把所有调度都扔给编译器做,硬件只需要傻跑就行了。这其实是现在很多新架构的趋势:
硬件简化,软件变复杂
静态调度代替动态仲裁
编译器替你把一切安排好
这样硬件设计简单了,可靠性上去了,性能也上去了,一举多得。
7. 总结:AI芯片这条路,其实还远没走到头
很多人说,现在AI芯片不就是堆堆堆吗?堆核堆缓存堆带宽,拼工艺拼成本,创新空间不大了。
但Groq这篇论文告诉我们:只要你敢跳出传统CPU/GPU的框框,换个思路玩,就能搞出比传统架构更优的性价比。
注意:不是普适性,普适性CPU和GPU更普世,而是更有针对性,在LPU针对大模型推理方面性能比CPU和GPU更有优势,这也是为什么英伟达花200亿美金买Groq的原因。。
从上面就可以看到,Groq把缓存砍了,功能分片,流式执行,这么简单几个思路改变,直接干出了4倍的性能提升。
这就是架构创新的魅力。
文章来源于歪睿老哥,作者歪睿老哥




